







 本文介绍了一种新型的红外与可见光图像融合方法MFST,通过引入聚焦自注意力和自适应融合策略,有效利用多模态特征。文章探讨了损失函数的设计,并展示了在多个数据集上的有效性,尽管存在一些改进空间,但方法在融合质量和效率上优于现有方法。
本文介绍了一种新型的红外与可见光图像融合方法MFST,通过引入聚焦自注意力和自适应融合策略,有效利用多模态特征。文章探讨了损失函数的设计,并展示了在多个数据集上的有效性,尽管存在一些改进空间,但方法在融合质量和效率上优于现有方法。
没有代码
整体框架就是改进了RFN-Nest中间的融合模块,把当年对ViT的一个新改进的方法拿来用了。
使用了很多损失,但个人觉得损失的权重系数的计算不是很好。
1、Motivation
- 现有的融合策略太简单没有利用特征信息
- 基于CNN的方法仅考虑到了局部,没有考虑到全局上下文信息。
- 端到端的方法缺少明显的特征提取步骤。
本文贡献为:
- 引进了聚焦自注意力(focal self-attention,就是一个对transformer的改进,作者拿过来用了)
- 有效地利用多模态特征,设计了一个自适应的融合策略,该策略是根据特征提取器不同层不同的特征设计的。
- 实验表明我们的方法大多数sota要好。
二、网络结构
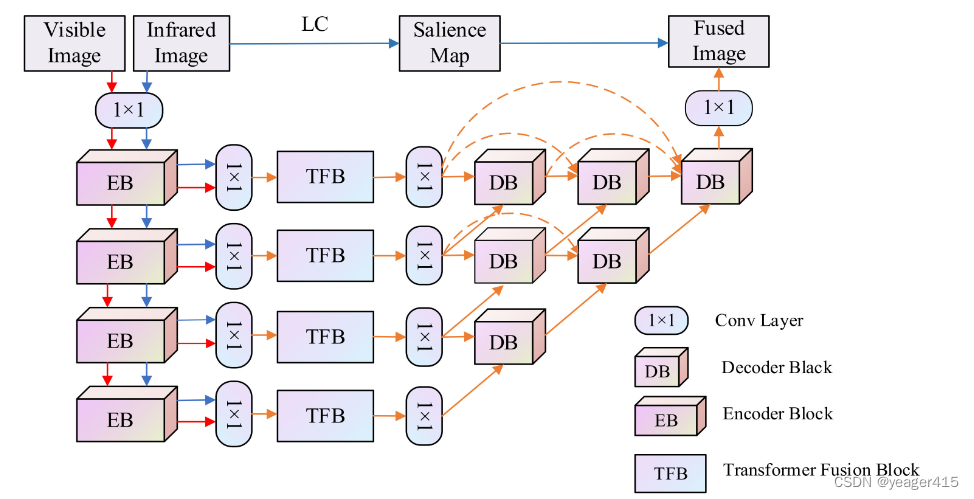
每个EB,由两个卷积层和一个ReLU和maxpooling。
中间的融合层:
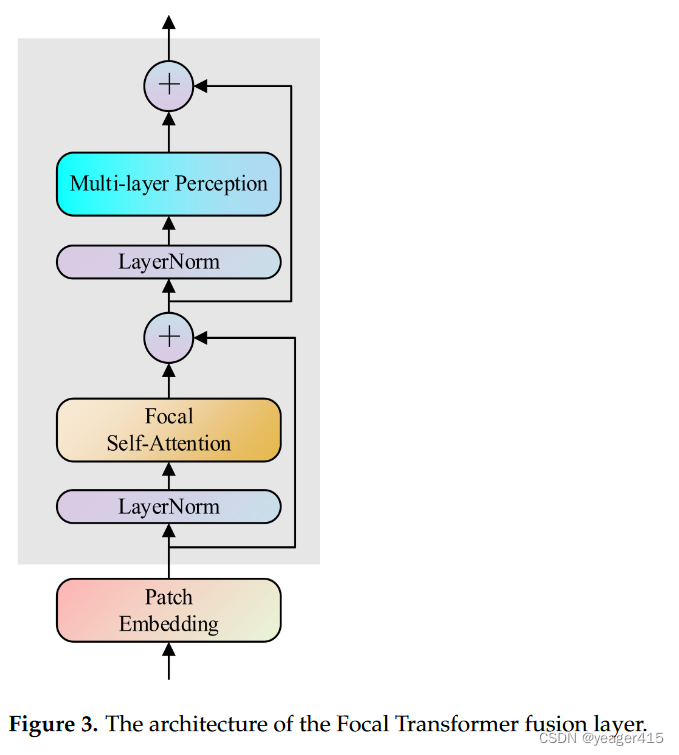
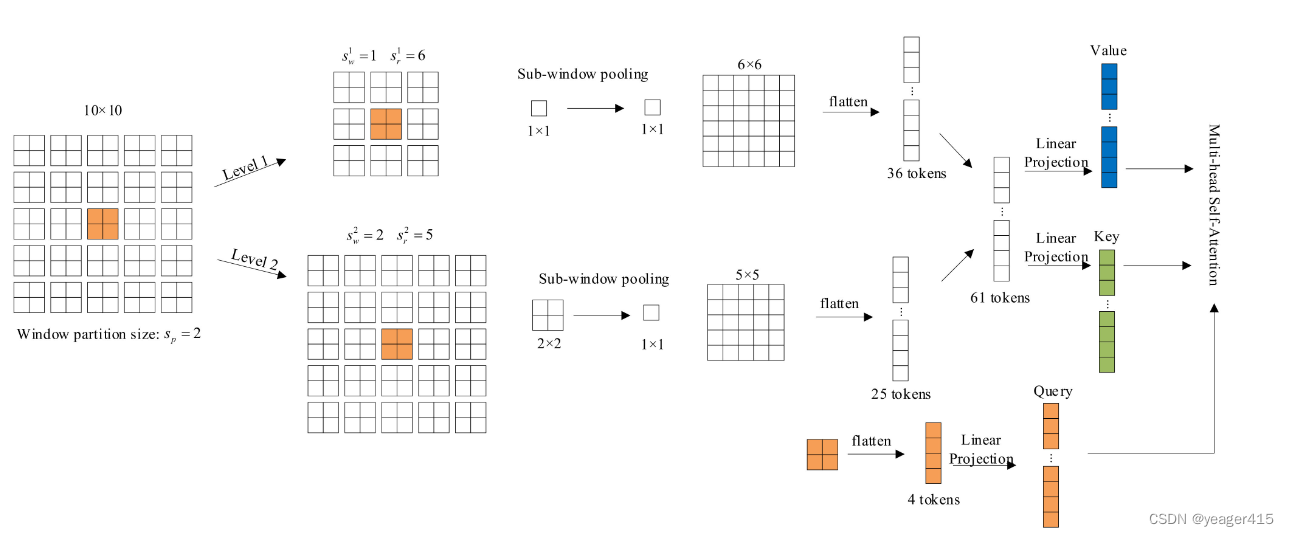
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3214
3214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









