







逻辑斯蒂回归
机器学习实战的代码详见:https://editor.csdn.net/md/?articleId=105162141
sklearn中的逻辑斯蒂回归详见:https://blog.csdn.net/leemusk/article/details/103111878
基本概念
几率(odds):一个事件发生的概率与时间不发生的概率的比值。
p 1 − p \frac p {1-p} 1−pp
对数几率(log odds)
l o g p 1 − p log \frac p {1-p} log1−pp
1 优缺点
优点:
- 计算代价不高
- 易于理解和实现
缺点:
- 容易欠拟合
- 分类精度可能不高
2 基本概念及结论推理
-
逻辑斯蒂回归模型属于对数线性模型。
-
逻辑斯蒂回归是判别模型,返回的是一维向量,第i个值代表第i个类发生的条件概率值。比较条件概率值的大小,将实例分到概率值较大的那一类。
-
逻辑斯蒂回归模型是由以下条件概率分布表示的分类模型。逻辑斯蒂回归模型可以用于二分类问题或多分类问题。
以下 x x x为输入特征, w w w为特征的权值。公式中的 w w w 包括 b b b ,将其作为 w 0 w_0 w0 , w i w_i wi表示预测该样本为第 i i i类的特征的权值,通过最优化方法获取。
逻辑斯蒂回归模型源自逻辑斯蒂分布,其分布函数 F ( x ) F(x) F(x)是 S S S形函数。逻辑斯蒂回归模型是有输入的线性函数表示的输出的对数几率模型。二分类:
P ( Y = 1 ∣ x ) = e x p ( w ⋅ x ) 1 + e x p ( w ⋅ x ) P ( Y = 0 ∣ x ) = 1 1 + e x p ( w ⋅ x ) P(Y = 1|x) = \frac {exp({w} \cdot {x})} {1+ exp({w} \cdot {x})} \\ P(Y = 0|x) = \frac 1 {1+ exp({w} \cdot {x})} P(Y=1∣x)=1+exp(w⋅x)exp(w⋅x)P(Y=0∣x)=1+exp(w⋅x)1
在二分类问题中,存在sigmoid激活函数: 1 1 + e x p ( − z ) \frac 1 {1 + exp(-z)} 1+exp(−z)1:
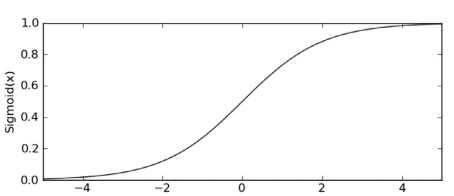
当z越接近于正无穷,函数值(预测值)h 越接近于1,当z越接近于负无穷,函数值(预测值)h 越接近于0; 在逻辑斯蒂回归算法中, z = w ⋅ x z = w \cdot x z=w⋅x。给定某一个阈值 x(0~1),当h >= x时,输出1, 当h < x时,输出0。多分类:
P ( Y = k ∣ x ) = e x p ( w k ⋅ x ) 1 + ∑ k = 1 K − 1 e x p ( w k ⋅ x ) , k = 1 , 2 , . . . K − 1 P ( Y = K ∣ x ) = 1 1 + ∑ k = 1 K − 1 e x p ( w k ⋅ x ) P(Y = k|x) = \frac {exp({w_k} \cdot {x})} {1+ \sum_{k=1}^{K-1} exp({w_k} \cdot {x})}, k=1,2,...K-1\\ P(Y = K| x) = \frac 1 {1+ \sum_{k=1}^{K-1} exp({w_k} \cdot {x})} P(Y=k∣x)=1+∑k=1K−1exp(wk⋅x)exp(wk⋅x),k=1,2,...K−1P(Y=K∣x)=1+∑
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6305
6305











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









