






需求
- 对矩阵A[V][61]求伪逆矩阵A+[61][V]。该矩阵A为满秩。
- 矩阵行数为V,每次上电行数V可配,61<V ≤ 800。
- 求出伪逆矩阵A+后,A+与矩阵A的第一列相乘,得到61*1的结果矩阵。
- 计算时间小于3ms。
实现方式
- 通过vitis_hls实现,最终生成vivado ip核,运行在V7-690T FPGA上。
- 由于矩阵A为满秩,因此采用左逆矩阵方式。
- 首先对A[V][61]求AT*A,得到ATA[61][61];
- 对ATA[61][61]求逆部分采用LU分解+三角矩阵求逆方式,
- 对ATA[61][61]进行LU分解得到矩阵L和U;
- 通过下三角矩阵求逆,对L求逆得到inv_L
- 通过上三角矩阵求逆,对U求逆得到inv_U
- ATA的逆 inv_ATA= invU * inv_L。
- A的逆 inv_A = inv_ATA * AT。

实现结果
代码
VITIS_HLS代码共两套,分别为定点实现和浮点实现。
定点实现顶层代码如下
#include "kernel.h"
void pinv_Kernel(hls::stream<ap_uint<8>> &din, // input data
hls::stream<ap_uint<10>> &row, // input row parameter, only ones
hls::stream<ap_fixed<32, 16>> &dout)
{
#pragma HLS INTERFACE axis port = din
#pragma HLS INTERFACE axis port = row
#pragma HLS INTERFACE axis port = dout
#pragma HLS INTERFACE ap_ctrl_none port = return
ap_uint<6> col_index;
ap_uint<10> rows;
ap_uint<8> A[V][N];
ap_fixed<35, 27> ATA[N][N];
ap_uint<8> AT[N][V];
ap_uint<8> A_1[V];
ap_fixed<35, 27> L[N][N];
ap_fixed<35, 27> U[N][N];
ap_fixed<35, 27> invL[N][N];
ap_fixed<35, 27> invU[N][N];
ap_fixed<32, 16> invATA[N][N];
ap_fixed<32, 16> invA[N][V];
ap_fixed<32, 16> invAA1[N];
#pragma HLS ARRAY_PARTITION dim = 2 factor = 61 type = block variable = A
#pragma HLS ARRAY_PARTITION dim = 1 factor = 61 type = block variable = ATA
#pragma HLS ARRAY_PARTITION dim = 1 factor = 61 type = block variable = L
#pragma HLS ARRAY_PARTITION dim = 2 factor = 61 type = block variable = U
#pragma HLS ARRAY_PARTITION dim = 2 factor = 61 type = block variable = invL
#pragma HLS ARRAY_PARTITION dim = 1 factor = 61 type = block variable = invU
#pragma HLS ARRAY_PARTITION dim = 1 factor = 61 type = block variable = invATA
#pragma HLS ARRAY_PARTITION dim = 1 factor = 61 type = block variable = invA
#pragma HLS BIND_STORAGE type = ram_s2p latency = 1 variable = A
#pragma HLS BIND_STORAGE type = ram_s2p latency = 1 variable = AT
#pragma HLS BIND_STORAGE type = ram_t2p latency = 1 variable = ATA
#pragma HLS BIND_STORAGE type = ram_t2p latency = 1 variable = invL
#pragma HLS BIND_STORAGE type = ram_t2p latency = 1 variable = invU
#pragma HLS BIND_STORAGE type = ram_t2p latency = 1 variable = invATA
#pragma HLS BIND_STORAGE type = ram_t2p latency = 1 variable = invA
#pragma HLS BIND_STORAGE type = ram_s2p latency = 1 variable = A_1
#pragma HLS BIND_STORAGE type = ram_s2p latency = 1 variable = invAA1
axis2mem(din, row, A, AT, A_1, rows, col_index);
matrix_ATA(A, ATA, rows, col_index);
lu(ATA, L, U);
invTriLow(L, invL);
invTriHig(U, invU);
matrix_invATA(invU, invL, invATA);
matrix_invA(invATA, AT, col_index, invA);
matrix_invAA1(invA, A_1, rows, invAA1);
mem2axis(invAA1, dout);
}浮点实现顶层代码如下
#include "kernel.h"
void pinv_Kernel(hls::stream<ap_uint<8>> &din, // input data
hls::stream<ap_uint<10>> &row, // input row parameter, only ones
hls::stream<ap_fixed<32, 16>> &dout)
{
#pragma HLS INTERFACE axis port = din
#pragma HLS INTERFACE axis port = row
#pragma HLS INTERFACE axis port = dout
#pragma HLS INTERFACE ap_ctrl_none port = return
ap_uint<6> col_index;
ap_uint<10> rows;
ap_uint<8> A[V][N];
float ATA[N][N];
ap_uint<8> AT[N][V];
ap_uint<8> A_1[V];
float L[N][N];
float U[N][N];
float invL[N][N];
float invU[N][N];
float invATA[N][N];
float invA[N][V];
float invAA1[N];
#pragma HLS ARRAY_PARTITION dim = 2 factor = 61 type = block variable = A
#pragma HLS ARRAY_PARTITION dim = 1 factor = 61 type = block variable = ATA
#pragma HLS ARRAY_PARTITION dim = 1 factor = 61 type = block variable = L
#pragma HLS ARRAY_PARTITION dim = 2 factor = 61 type = block variable = U
#pragma HLS ARRAY_PARTITION dim = 2 factor = 61 type = block variable = invL
#pragma HLS ARRAY_PARTITION dim = 1 factor = 61 type = block variable = invU
#pragma HLS ARRAY_PARTITION dim = 1 factor = 61 type = block variable = invATA
#pragma HLS ARRAY_PARTITION dim = 1 factor = 61 type = block variable = invA
#pragma HLS BIND_STORAGE type = ram_s2p latency = 1 variable = A
#pragma HLS BIND_STORAGE type = ram_s2p latency = 1 variable = AT
#pragma HLS BIND_STORAGE type = ram_t2p latency = 1 variable = ATA
#pragma HLS BIND_STORAGE type = ram_t2p latency = 1 variable = invL
#pragma HLS BIND_STORAGE type = ram_t2p latency = 1 variable = invU
#pragma HLS BIND_STORAGE type = ram_t2p latency = 1 variable = invATA
#pragma HLS BIND_STORAGE type = ram_t2p latency = 1 variable = invA
#pragma HLS BIND_STORAGE type = ram_s2p latency = 1 variable = A_1
#pragma HLS BIND_STORAGE type = ram_s2p latency = 1 variable = invAA1
axis2mem(din, row, A, AT, A_1, rows, col_index);
matrix_ATA(A, ATA, rows, col_index);
lu(ATA, L, U);
invTriLow(L, invL);
invTriHig(U, invU);
matrix_invATA(invU, invL, invATA);
matrix_invA(invATA, AT, col_index, invA);
matrix_invAA1(invA, A_1, rows, invAA1);
mem2axis(invAA1, dout);
}耗时情况
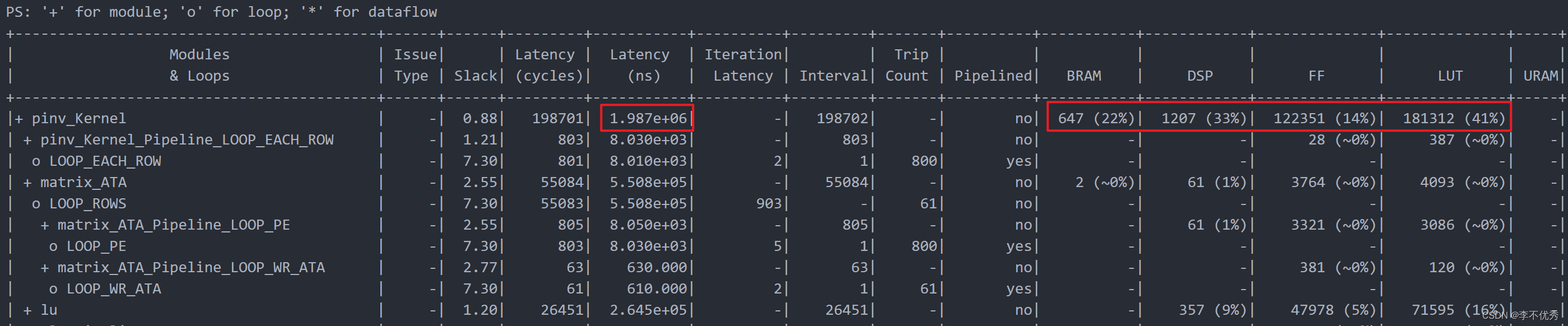
定点数实现整体耗时低于2ms。
其中LU分解消耗0.26ms;
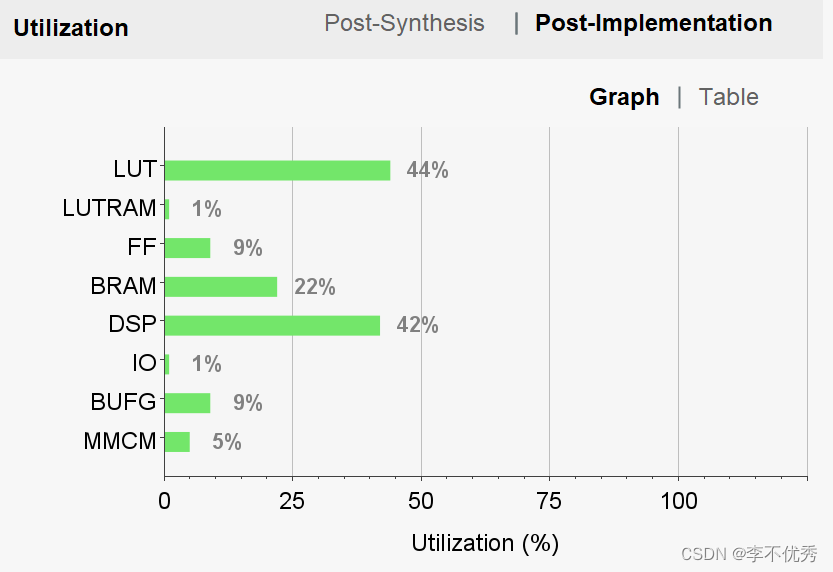
资源使用情况
LUT使用44%
DSP使用42%
BRAM使用22%
vivado impl报告


导出IP到vivado
ip的例化端口如下
pinv_Kernel_0 your_instance_name (
.ap_clk(ap_clk), // input wire ap_clk
.ap_rst_n(ap_rst_n), // input wire ap_rst_n
.din_TVALID(din_TVALID), // input wire din_TVALID
.din_TREADY(din_TREADY), // output wire din_TREADY
.din_TDATA(din_TDATA), // input wire [7 : 0] din_TDATA
.row_TVALID(row_TVALID), // input wire row_TVALID
.row_TREADY(row_TREADY), // output wire row_TREADY
.row_TDATA(row_TDATA), // input wire [15 : 0] row_TDATA
.dout_TVALID(dout_TVALID), // output wire dout_TVALID
.dout_TREADY(dout_TREADY), // input wire dout_TREADY
.dout_TDATA(dout_TDATA) // output wire [31 : 0] dout_TDATA
);源码
源码将在后续推出,考虑篇幅太大,只推出核心的三部分:
1. 矩阵并行计算
2. LU分解
3. 三角矩阵求逆
















 3175
3175

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











