







概述
情感分类是自然语言处理中的经典任务,是典型的分类问题。本文介绍如何使用MindSpore实现一个基于RNN网络的情感分类模型,实现如下的效果:
输入: This film is terrible
正确标签: Negative
预测标签: Negative
输入: This film is great
正确标签: Positive
预测标签: Positive
数据准备
使用情感分类的经典数据集IMDB影评数据集,数据集包含Positive和Negative两类。
下载数据集
代码示例:
import os
import shutil
import requests
import tempfile
from tqdm import tqdm
from typing import IO
from pathlib import Path
cache_dir = Path.home() / '.mindspore_examples'
def http_get(url: str, temp_file: IO):
"""使用requests库下载数据,并使用tqdm库进行流程可视化"""
req = requests.get(url, stream=True)
content_length = req.headers.get('Content-Length')
total = int(content_length) if content_length is not None else None
progress = tqdm(unit='B', total=total)
for chunk in req.iter_content(chunk_size=1024):
if chunk:
progress.update(len(chunk))
temp_file.write(chunk)
progress.close()
def download(file_name: str, url: str):
"""下载数据并存为指定名称"""
if not os.path.exists(cache_dir):
os.makedirs(cache_dir)
cache_path = os.path.join(cache_dir, file_name)
cache_exist = os.path.exists(cache_path)
if not cache_exist:
with tempfile.NamedTemporaryFile() as temp_file:
http_get(url, temp_file)
temp_file.flush()
temp_file.seek(0)
with open(cache_path, 'wb') as cache_file:
shutil.copyfileobj(temp_file, cache_file)
return cache_path
imdb_path = download('aclImdb_v1.tar.gz', 'https://mindspore-website.obs.myhuaweicloud.com/notebook/datasets/aclImdb_v1.tar.gz')
imdb_path
加载数据集
下载好的IMDB数据集为tar.gz文件,我们使用Python的tarfile库对其进行读取,并将所有数据和标签分别进行存放。原始的IMDB数据集解压目录如下:
├── aclImdb
│ ├── imdbEr.txt
│ ├── imdb.vocab
│ ├── README
│ ├── test
│ └── train
│ ├── neg
│ ├── pos
...
数据集已分割为train和test两部分,且每部分包含neg和pos两个分类的文件夹,因此需分别train和test进行读取并处理数据和标签。
代码示例:
import re
import six
import string
import tarfile
class IMDBData():
"""IMDB数据集加载器
加载IMDB数据集并处理为一个Python迭代对象。
"""
label_map = {
"pos": 1,
"neg": 0
}
def __init__(self, path, mode="train"):
self.mode = mode
self.path = path
self.docs, self.labels = [], []
self._load("pos")
self._load("neg")
def _load(self, label):
pattern = re.compile(r"aclImdb/{}/{}/.*\.txt$".format(self.mode, label))
# 将数据加载至内存
with tarfile.open(self.path) as tarf:
tf = tarf.next()
while tf is not None:
if bool(pattern.match(tf.name)):
# 对文本进行分词、去除标点和特殊字符、小写处理
self.docs.append(str(tarf.extractfile(tf).read().rstrip(six.b("\n\r"))
.translate(None, six.b(string.punctuation)).lower()).split())
self.labels.append([self.label_map[label]])
tf = tarf.next()
def __getitem__(self, idx):
return self.docs[idx], self.labels[idx]
def __len__(self):
return len(self.docs)
# 加载训练数据集进行测试
imdb_train = IMDBData(imdb_path, 'train')
import mindspore.dataset as ds
def load_imdb(imdb_path):
imdb_train = ds.GeneratorDataset(IMDBData(imdb_path, "train"), column_names=["text", "label"], shuffle=True, num_samples=10000)
imdb_test = ds.GeneratorDataset(IMDBData(imdb_path, "test"), column_names=["text", "label"], shuffle=False)
return imdb_train, imdb_test
imdb_train, imdb_test = load_imdb(imdb_path)
加载预训练词向量
预训练词向量是对输入单词的数值化表示,通过nn.Embedding层,采用查表的方式,输入单词对应词表中的index,获得对应的表达向量。
因此进行模型构造前,需要将Embedding层所需的词向量和词表进行构造。这里使用Glove(Global Vectors for Word Representation)这种经典的预训练词向量,
其数据格式如下:
| Word | Vector |
|---|---|
| the | 0.418 0.24968 -0.41242 0.1217 0.34527 -0.044457 -0.49688 -0.17862 -0.00066023 … |
| , | 0.013441 0.23682 -0.16899 0.40951 0.63812 0.47709 -0.42852 -0.55641 -0.364 … |
直接使用第一列的单词作为词表,使用dataset.text.Vocab将其按顺序加载;同时读取每一行的Vector并转为numpy.array,用于nn.Embedding加载权重使用。
代码示例:
import zipfile
import numpy as np
def load_glove(glove_path):
glove_100d_path = os.path.join(cache_dir, 'glove.6B.100d.txt')
if not os.path.exists(glove_100d_path):
glove_zip = zipfile.ZipFile(glove_path)
glove_zip.extractall(cache_dir)
embeddings = []
tokens = []
with open(glove_100d_path, encoding='utf-8') as gf:
for glove in gf:
word, embedding = glove.split(maxsplit=1)
tokens.append(word)
embeddings.append(np.fromstring(embedding, dtype=np.float32, sep=' '))
# 添加 <unk>, <pad> 两个特殊占位符对应的embedding
embeddings.append(np.random.rand(100))
embeddings.append(np.zeros((100,), np.float32))
vocab = ds.text.Vocab.from_list(tokens, special_tokens=["<unk>", "<pad>"], special_first=False)
embeddings = np.array(embeddings).astype(np.float32)
return vocab, embeddings
# 下载Glove词向量,并加载生成词表和词向量权重矩阵
glove_path = download('glove.6B.zip', 'https://mindspore-website.obs.myhuaweicloud.com/notebook/datasets/glove.6B.zip')
vocab, embeddings = load_glove(glove_path)
len(vocab.vocab())
idx = vocab.tokens_to_ids('the')
embedding = embeddings[idx]
idx, embedding
数据集预处理
通过加载器加载的IMDB数据集进行了分词处理,但不满足构造训练数据的需要,因此要对其进行额外的预处理。其中包含的预处理如下:
- 通过Vocab将所有的Token处理为index id。
- 将文本序列统一长度,不足的使用
<pad>补齐,超出的进行截断。
这里使用mindspore.dataset中提供的接口进行预处理操作。这里使用到的接口均为MindSpore的高性能数据引擎设计,每个接口对应操作视作数据流水线的一部分,详情请参考MindSpore数据引擎。
首先针对token到index id的查表操作,使用text.Lookup接口,将前文构造的词表加载,并指定unknown_token。其次为文本序列统一长度操作,使用PadEnd接口,此接口定义最大长度和补齐值(pad_value),这里我们取最大长度为500,填充值对应词表中<pad>的index id。
除了对数据集中
text进行预处理外,由于后续模型训练的需要,要将label数据转为float32格式。
代码示例:
import mindspore as ms
lookup_op = ds.text.Lookup(vocab, unknown_token='<unk>')
pad_op = ds.transforms.PadEnd([500], pad_value=vocab.tokens_to_ids('<pad>'))
type_cast_op = ds.transforms.TypeCast(ms.float32)
imdb_train = imdb_train.map(operations=[lookup_op, pad_op], input_columns=['text'])
imdb_train = imdb_train.map(operations=[type_cast_op], input_columns=['label'])
imdb_test = imdb_test.map(operations=[lookup_op, pad_op], input_columns=['text'])
imdb_test = imdb_test.map(operations=[type_cast_op], input_columns=['label'])
imdb_train, imdb_valid = imdb_train.split([0.7, 0.3])
imdb_train = imdb_train.batch(64, drop_remainder=True)
imdb_valid = imdb_valid.batch(64, drop_remainder=True)
模型构建
完成数据集的处理后,我们设计用于情感分类的模型结构。首先需要将输入文本(即序列化后的index id列表)通过查表转为向量化表示,此时需要使用nn.Embedding层加载Glove词向量;然后使用RNN循环神经网络做特征提取;最后将RNN连接至一个全连接层,即nn.Dense,将特征转化为与分类数量相同的size,用于后续进行模型优化训练。整体模型结构如下:
nn.Embedding -> nn.RNN -> nn.Dense
这里我们使用能够一定程度规避RNN梯度消失问题的变种LSTM(Long short-term memory)做特征提取层。
Embedding
Embedding层又可称为EmbeddingLookup层,其作用是使用index id对权重矩阵对应id的向量进行查找,当输入为一个由index id组成的序列时,则查找并返回一个相同长度的矩阵,例如:
embedding = nn.Embedding(1000, 100) # 词表大小(index的取值范围)为1000,表示向量的size为100
input shape: (1, 16) # 序列长度为16
output shape: (1, 16, 100)
这里我们使用前文处理好的Glove词向量矩阵,设置nn.Embedding的embedding_table为预训练词向量矩阵。对应的vocab_size为词表大小400002,embedding_size为选用的glove.6B.100d向量大小,即100。
RNN
循环神经网络(Recurrent Neural Network, RNN)是一类以序列(sequence)数据为输入,在序列的演进方向进行递归(recursion)且所有节点(循环单元)按链式连接的神经网络。下图为RNN的一般结构:
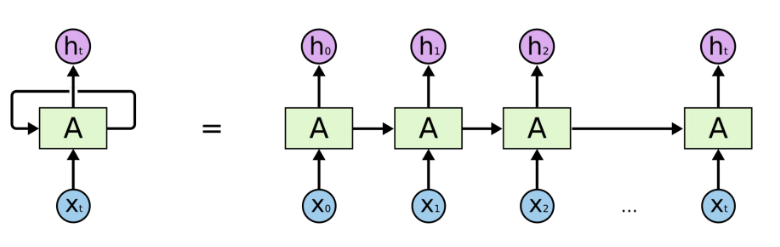
图示左侧为一个RNN Cell循环,右侧为RNN的链式连接平铺。实际上不管是单个RNN Cell还是一个RNN网络,都只有一个Cell的参数,在不断进行循环计算中更新。
由于RNN的循环特性,和自然语言文本的序列特性(句子是由单词组成的序列)十分匹配,因此被大量应用于自然语言处理研究中。下图为RNN的结构拆解:
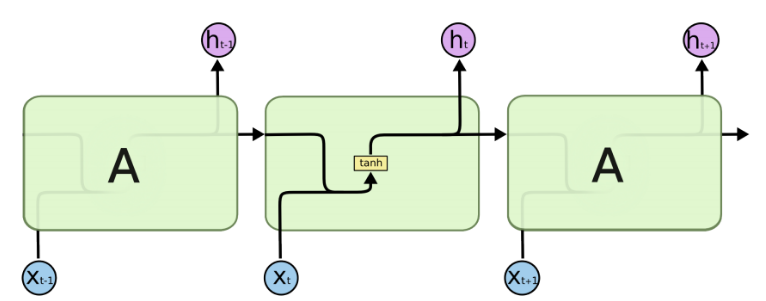
RNN单个Cell的结构简单,因此也造成了梯度消失(Gradient Vanishing)问题,具体表现为RNN网络在序列较长时,在序列尾部已经基本丢失了序列首部的信息。为了克服这一问题,LSTM(Long short-term memory)被提出,通过门控机制(Gating Mechanism)来控制信息流在每个循环步中的留存和丢弃。下图为LSTM的结构拆解:
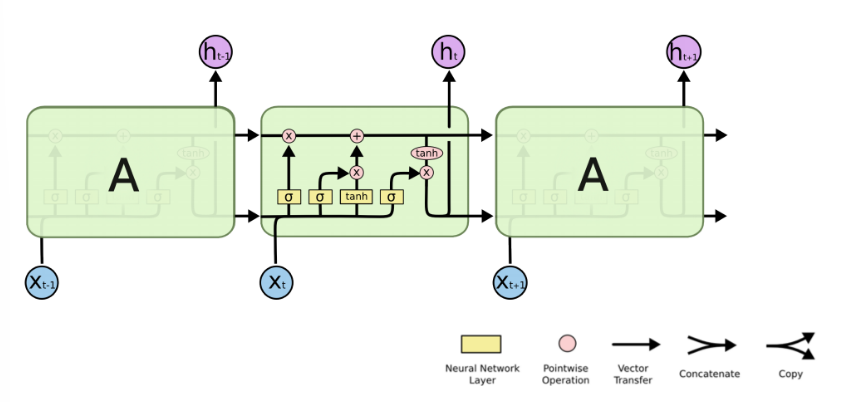
本节我们选择LSTM变种而不是经典的RNN做特征提取,来规避梯度消失问题,并获得更好的模型效果。下面来看MindSpore中nn.LSTM对应的公式:
h 0 : t , ( h t , c t ) = LSTM ( x 0 : t , ( h 0 , c 0 ) ) h_{0:t}, (h_t, c_t) = \text{LSTM}(x_{0:t}, (h_0, c_0)) h0:t,(ht,ct)=LSTM(x0:t,(h0,c0))
这里nn.LSTM隐藏了整个循环神经网络在序列时间步(Time step)上的循环,送入输入序列、初始状态,即可获得每个时间步的隐状态(hidden state)拼接而成的矩阵,以及最后一个时间步对应的隐状态。我们使用最后的一个时间步的隐状态作为输入句子的编码特征,送入下一层。
Time step:在循环神经网络计算的每一次循环,成为一个Time step。在送入文本序列时,一个Time step对应一个单词。因此在本例中,LSTM的输出 h 0 : t h_{0:t} h0:t对应每个单词的隐状态集合, h t h_t ht和 c t c_t ct对应最后一个单词对应的隐状态。
Dense
在经过LSTM编码获取句子特征后,将其送入一个全连接层,即nn.Dense,将特征维度变换为二分类所需的维度1,经过Dense层后的输出即为模型预测结果。
代码示例:
import math
import mindspore as ms
import mindspore.nn as nn
import mindspore.ops as ops
from mindspore.common.initializer import Uniform, HeUniform
class RNN(nn.Cell):
def __init__(self, embeddings, hidden_dim, output_dim, n_layers,
bidirectional, pad_idx):
super().__init__()
vocab_size, embedding_dim = embeddings.shape
self.embedding = nn.Embedding(vocab_size, embedding_dim, embedding_table=ms.Tensor(embeddings), padding_idx=pad_idx)
self.rnn = nn.LSTM(embedding_dim,
hidden_dim,
num_layers=n_layers,
bidirectional=bidirectional,
batch_first=True)
weight_init = HeUniform(math.sqrt(5))
bias_init = Uniform(1 / math.sqrt(hidden_dim * 2))
self.fc = nn.Dense(hidden_dim * 2, output_dim, weight_init=weight_init, bias_init=bias_init)
def construct(self, inputs):
embedded = self.embedding(inputs)
_, (hidden, _) = self.rnn(embedded)
hidden = ops.concat((hidden[-2, :, :], hidden[-1, :, :]), axis=1)
output = self.fc(hidden)
return output
损失函数与优化器
完成模型主体构建后,首先根据指定的参数实例化网络;然后选择损失函数和优化器。针对本节情感分类问题的特性,即预测Positive或Negative的二分类问题,我们选择nn.BCEWithLogitsLoss(二分类交叉熵损失函数)。
代码示例:
hidden_size = 256
output_size = 1
num_layers = 2
bidirectional = True
lr = 0.001
pad_idx = vocab.tokens_to_ids('<pad>')
model = RNN(embeddings, hidden_size, output_size, num_layers, bidirectional, pad_idx)
loss_fn = nn.BCEWithLogitsLoss(reduction='mean')
optimizer = nn.Adam(model.trainable_params(), learning_rate=lr)
训练逻辑
在完成模型构建,进行训练逻辑的设计。一般训练逻辑分为一下步骤:
- 读取一个Batch的数据;
- 送入网络,进行正向计算和反向传播,更新权重;
- 返回loss。
下面按照此逻辑,使用tqdm库,设计训练一个epoch的函数,用于训练过程和loss的可视化。
代码示例:
def forward_fn(data, label):
logits = model(data)
loss = loss_fn(logits, label)
return loss
grad_fn = ms.value_and_grad(forward_fn, None, optimizer.parameters)
def train_step(data, label):
loss, grads = grad_fn(data, label)
optimizer(grads)
return loss
def train_one_epoch(model, train_dataset, epoch=0):
model.set_train()
total = train_dataset.get_dataset_size()
loss_total = 0
step_total = 0
with tqdm(total=total) as t:
t.set_description('Epoch %i' % epoch)
for i in train_dataset.create_tuple_iterator():
loss = train_step(*i)
loss_total += loss.asnumpy()
step_total += 1
t.set_postfix(loss=loss_total/step_total)
t.update(1)
评估指标和逻辑
训练逻辑完成后,需要对模型进行评估。即使用模型的预测结果和测试集的正确标签进行对比,求出预测的准确率。由于IMDB的情感分类为二分类问题,对预测值直接进行四舍五入即可获得分类标签(0或1),然后判断是否与正确标签相等即可。
代码示例:
def binary_accuracy(preds, y):
"""
计算每个batch的准确率
"""
# 对预测值进行四舍五入
rounded_preds = np.around(ops.sigmoid(preds).asnumpy())
correct = (rounded_preds == y).astype(np.float32)
acc = correct.sum() / len(correct)
return acc
def evaluate(model, test_dataset, criterion, epoch=0):
total = test_dataset.get_dataset_size()
epoch_loss = 0
epoch_acc = 0
step_total = 0
model.set_train(False)
with tqdm(total=total) as t:
t.set_description('Epoch %i' % epoch)
for i in test_dataset.create_tuple_iterator():
predictions = model(i[0])
loss = criterion(predictions, i[1])
epoch_loss += loss.asnumpy()
acc = binary_accuracy(predictions, i[1])
epoch_acc += acc
step_total += 1
t.set_postfix(loss=epoch_loss/step_total, acc=epoch_acc/step_total)
t.update(1)
return epoch_loss / total
模型训练与保存
前序完成了模型构建和训练、评估逻辑的设计,下面进行模型训练。这里我们设置训练轮数为5轮。同时维护一个用于保存最优模型的变量best_valid_loss,根据每一轮评估的loss值,取loss值最小的轮次,将模型进行保存。为节省用例运行时长,此处num_epochs设置为2,可根据需要自行修改。
代码示例:
num_epochs = 2
best_valid_loss = float('inf')
ckpt_file_name = os.path.join(cache_dir, 'sentiment-analysis.ckpt')
for epoch in range(num_epochs):
train_one_epoch(model, imdb_train, epoch)
valid_loss = evaluate(model, imdb_valid, loss_fn, epoch)
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
ms.save_checkpoint(model, ckpt_file_name)
运行结果:

模型加载与测试
模型训练完成后,一般需要对模型进行测试或部署上线,此时需要加载已保存的最优模型(即checkpoint),供后续测试使用。这里我们直接使用MindSpore提供的Checkpoint加载和网络权重加载接口:1.将保存的模型Checkpoint加载到内存中,2.将Checkpoint加载至模型。
代码示例:
param_dict = ms.load_checkpoint(ckpt_file_name)
ms.load_param_into_net(model, param_dict)
imdb_test = imdb_test.batch(64)
evaluate(model, imdb_test, loss_fn)
运行结果:

自定义输入测试
最后我们设计一个预测函数,实现开头描述的效果,输入一句评价,获得评价的情感分类。具体包含以下步骤:
- 将输入句子进行分词;
- 使用词表获取对应的index id序列;
- index id序列转为Tensor;
- 送入模型获得预测结果;
- 打印输出预测结果。
代码示例:
score_map = {
1: "Positive",
0: "Negative"
}
def predict_sentiment(model, vocab, sentence):
model.set_train(False)
tokenized = sentence.lower().split()
indexed = vocab.tokens_to_ids(tokenized)
tensor = ms.Tensor(indexed, ms.int32)
tensor = tensor.expand_dims(0)
prediction = model(tensor)
return score_map[int(np.round(ops.sigmoid(prediction).asnumpy()))]
predict_sentiment(model, vocab, "This film is terrible")
# 结果:'Negative'
predict_sentiment(model, vocab, "This film is great")
# 结果:'Positive'
截图时间
















 916
916











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









