






论文
1 Introduction
Gait Lateral Network:步态横向网络
创新之处:
① Lateral Connection:横向连接。利用深度CNN网络中的固有的特征金字塔来学习更具有判别性表示的步态特征,不同层提取的特征捕获了不同的细节。通过对GaitSet的改进,将不同阶段提取的轮廓集特征与集合级特征以横向连接的方式合并,从而学习更具有判别性的表示。
② Compact Block:紧缩块。通过HPM学习到的表示存在冗余, 文章将高维表示看成是低维表示的集合,利用dropout选择一个小子集,通过全连接层映射到一个紧凑的空间从而实现蒸馏。

2 Related Work
Inherent Feature Pyramid:固有金字塔特征,从FPN(特征金字塔网络,用于物体检测)得到了启发。
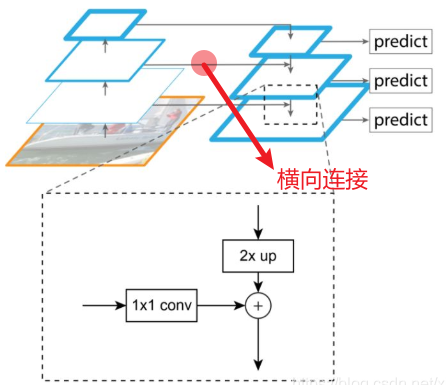
文章与FPN存在三点不同:
① GLN有两个分支(轮廓级别与集合级别),利用横向连接同时合并两个级别的特征。
② FPN根据接受域不同分配不同的训练标签,而GLN不同阶段的标签是一致的。
③ FPN在不同阶段的头部共用参数,而GLN在不同阶段的后续层有独立的参数。
3 Our Approach
3.1 BackBone简介
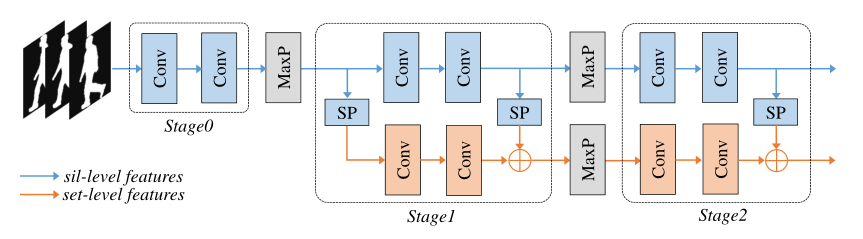
GaitGLN是一个GaitSet的改进版本,以下为GaitSet网络,作者将其划分为Stage0,1,2三个阶段(有些许改动,下边提及):
并在此基础上提出了自己的横向连接网络:
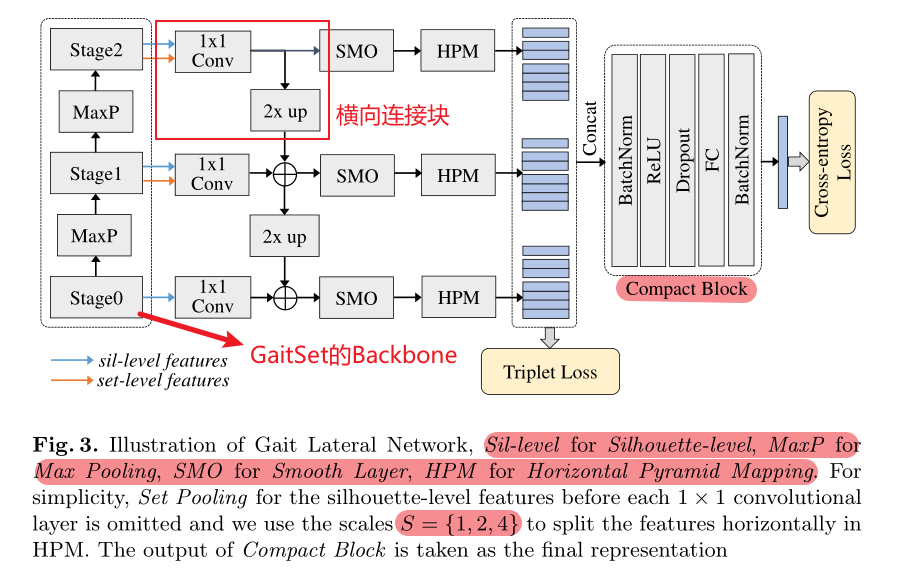
注意!上图的蓝色与橙色箭头均已经过了Set Pooling!并且,两者先通过concat之后再经过1x1Conv
3.2 Lateral Connections
**作用:**通过CNN的特征金字塔学习更具有判别性的步态表示
**Fine-tune:**调换了Stage1中MaxPooing与SP的顺序,作用应该是方便横向连接网路的接入
修改前,先MP再SP:
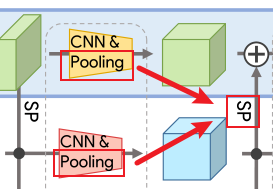
修改后,先SP再MP:
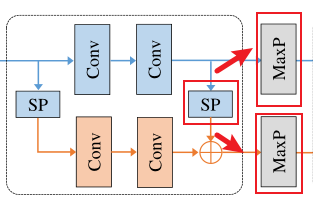
※ 这里特别提及了MaPooling与SetPooling的区别,前者在h和w维度做操作([30, 64, 44] => [30, 32,22]),后者在s维度做操作([30, 64, 44] => [1, 64, 44])。
**作用机理:**主干网络的不同Stage提取了步态轮廓集合的不同细节(bottom-up),而利用横向连接网络对这些细节进行融合(up-bottom)。
① 1×1Conv:对通道维度进行重新调整,从而使得深层的特征可以与上一层的channel数目相匹配,在文中固定为256
② 2 × up:两倍上采样(扩大特征图像),通过最近邻上采样实现
③ SMO:平滑层,作用是为了缓解上采样造成的混叠效应和不同阶段之间的语义差距,通道大小也为256,通过3×3的卷积层进行实现
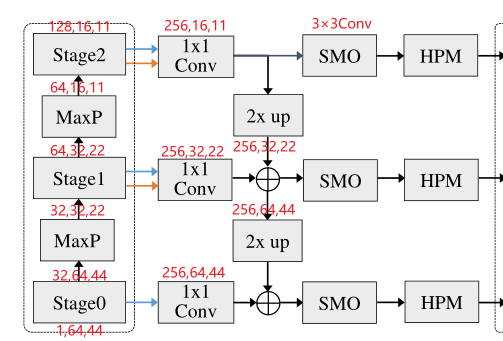
3.3 Compact Block
**作用:**压缩原本GaitSet的15872维特征向量到只有256维,减小两个数量级的存储,后边做解释。
作用机理:发现HPM跨不同尺度的表示中,编码了一些重复的信息,例如4尺度的第一条度 与 8尺度的第1和2条 代表轮廓的同一区域,并且为此猜想在高维表示中存在着一定的冗余信息
① HPM:与GaitSet保持一致,划分为1,2,4,8,16个不同的尺度
② 紧缩快:
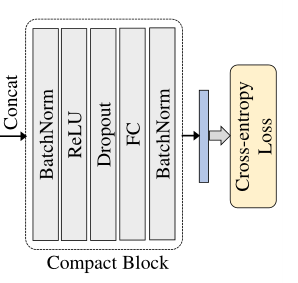

注意:Dropout层只在train阶段开启,dropout rate设置为0.9
3.4 Training Strategy
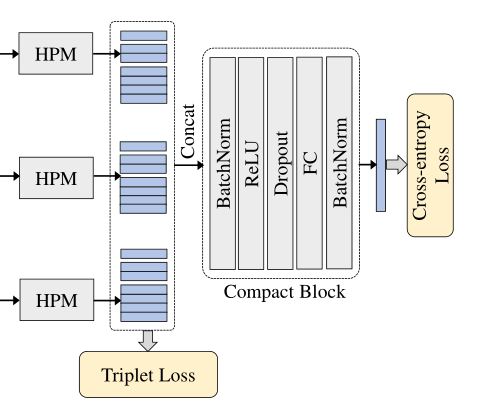
如图所见,训练过程中包含了两个损失函数:三元数损失 + 交叉熵损失。
三元数损失用于预训练横向连接网络(训练细节如同GaitSet),而三元数损失 + 交叉熵损失之和将被用于全局训练,具体做法是将每一个被试者单独看做一类(平滑标记技术),用交叉熵训练多分类问题。
平滑标记技术:在通常的交叉熵训练中,label通常设计为one-hot编码。但在本文中,为了鼓励模型降低对训练集的信心,概率的设置有些许改变(0概率变成了一个小概率值):
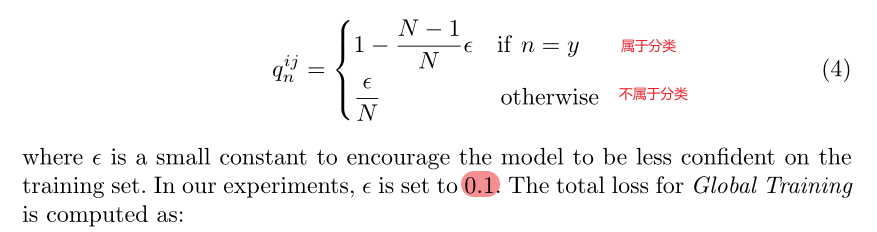

小细节:Compact Block的输出被固定为256,那对于OUMVLP这种大数据集,有10307个分类,256维根本不够one-hot的维度。确实,文章是有再最后再加入一个线性层的,但是在推理阶段并不能把改维度的特征作为最终表示,仍然应该以256维作为最终表示。简而言之,这个线性层是为了辅助交叉熵训练的,但它不是最终表示。

代码复现(仅主干网)
'''BackBone'''
import torch
import torch.nn as nn
import torch.nn.functional as F
from model.network.basic_blocks import SetBlock, BasicConv2d, BasicConv1x1, SMO, Compact_Block
class GaitGLN(nn.Module):
def __init__(self, hidden_dim):
super(GaitGLN, self).__init__()
self.hidden_dim = hidden_dim
self.batch_frame = None
_set_in_channels = 1
_set_channels = [32, 64, 128]
self.set_layer1 = SetBlock(BasicConv2d(_set_in_channels, _set_channels[0], 5, padding=2))
self.set_layer2 = SetBlock(BasicConv2d(_set_channels[0], _set_channels[0], 3, padding=1))
self.set_layer3 = SetBlock(BasicConv2d(_set_channels[0], _set_channels[1], 3, padding=1))
self.set_layer4 = SetBlock(BasicConv2d(_set_channels[1], _set_channels[1], 3, padding=1))
self.set_layer5 = SetBlock(BasicConv2d(_set_channels[1], _set_channels[2], 3, padding=1))
self.set_layer6 = SetBlock(BasicConv2d(_set_channels[2], _set_channels[2], 3, padding=1))
_gl_in_channels = 32
_gl_channels = [64, 128]
self.gl_layer1 = BasicConv2d(_gl_in_channels, _gl_channels[0], 3, padding=1)
self.gl_layer2 = BasicConv2d(_gl_channels[0], _gl_channels[0], 3, padding=1)
self.gl_layer3 = BasicConv2d(_gl_channels[0], _gl_channels[1], 3, padding=1)
self.gl_layer4 = BasicConv2d(_gl_channels[1], _gl_channels[1], 3, padding=1)
self.gl_pooling = nn.MaxPool2d(2)
self.conv1x1_layer1 = BasicConv1x1(_set_channels[0])
self.conv1x1_layer2 = BasicConv1x1(_set_channels[1] * 2)
self.conv1x1_layer3 = BasicConv1x1(_set_channels[2] * 2)
self.smo = SMO()
self.upsample = nn.Upsample(scale_factor=2, mode='nearest')
self.bin_num = [1, 2, 4]
self.cb = Compact_Block(21, 1)
for m in self.modules():
if isinstance(m, (nn.Conv2d, nn.Conv1d)):
nn.init.xavier_uniform_(m.weight.data)
elif isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight.data)
nn.init.constant(m.bias.data, 0.0)
elif isinstance(m, (nn.BatchNorm2d, nn.BatchNorm1d)):
nn.init.normal(m.weight.data, 1.0, 0.02)
nn.init.constant(m.bias.data, 0.0)
def pooling(self, x):
n, s, c, h, w = x.size()
x = x.view(-1, c, h, w)
pool2d = nn.MaxPool2d(2)
x = pool2d(x)
_, c, h, w = x.size()
return x.view(n, s, c, h, w)
def sp(self, x):
return torch.max(x, 1)
def hpm(self, x):
feature = list()
n, c, h, w = x.size()
for num_bin in self.bin_num: # 1 2 4
z = x.view(n, c, num_bin, -1)
z = z.mean(3) + z.max(3)[0]
feature.append(z)
feature = torch.cat(feature, 2).permute(2, 0, 1).contiguous()
return feature
def forward(self, silho):
x = silho.unsqueeze(2)
del silho
# Stage 0
x = self.set_layer1(x) # Conv [8, 30, 32, 64, 44]
x = self.set_layer2(x) # Conv [8, 30, 32, 64, 44]
# Lateral Connection 0
lc0 = self.conv1x1_layer1(self.sp(x)[0]) # SP + Adjust [8, 256, 64, 44]
# MP 0
x = self.pooling(x) # MP [8, 30, 32, 32, 22]
# Stage 1
gl = self.gl_layer1(self.sp(x)[0]) # SP + Conv [8, 64, 32, 22]
gl = self.gl_layer2(gl) # Conv [8, 64, 32, 22]
x = self.set_layer3(x) # Conv [8, 30, 64, 32, 22]
x = self.set_layer4(x) # Conv [8, 30, 64, 32, 22]
gl = gl + self.sp(x)[0] # SP + Concat [8, 64, 32, 22]
# Lateral Connection 1
lc1 = torch.cat((self.sp(x)[0], gl), dim=1) # Concat [8, 128, 32, 22]
lc1 = self.conv1x1_layer2(lc1) # Adjust [8, 256, 32, 22]
# MP 1
x = self.pooling(x) # MP [8, 30, 64, 16, 11]
gl = self.gl_pooling(gl) # MP [8, 64, 16, 11]
# Stage 2
gl = self.gl_layer3(gl) # Conv [8, 128, 16, 11]
gl = self.gl_layer4(gl) # Conv [8, 128, 16, 11]
x = self.set_layer5(x) # Conv [8, 30, 128, 16, 11]
x = self.set_layer6(x) # Conv [8, 30, 128, 16, 11]
gl = gl + self.sp(x)[0] # Concat + SP [8, 128, 16, 11]
# Lateral Connection 2
lc2 = torch.cat((self.sp(x)[0], gl), dim=1) # Concat [8, 256, 16, 11]
lc2 = self.conv1x1_layer3(lc2) # Adjust [8, 256, 16, 11]
feature1 = self.hpm(self.smo(lc2)) # SMO + HPM [7, 8, 256]
lc2 = self.upsample(lc2) # Upsample [8, 256, 32, 22]
lc1 = lc1 + lc2 # Add [8, 256, 32, 22]
feature2 = self.hpm(self.smo(lc1)) # SMO + HPM [7, 8, 256]
lc1 = self.upsample(lc1) # Upsample [8, 256, 64, 44]
lc0 = lc0 + lc1 # Add [8, 256, 64, 44]
feature3 = self.hpm(self.smo(lc0)) # SMO + HPM [7, 8, 256]
feature = torch.cat((feature1, feature2, feature3), dim=0).permute(1, 0, 2).contiguous() # Concat [8, 21, 256]
# Compact Block
feature_cb = self.cb(feature) # [8, 256]
return feature, feature_cb
'''basic_blocks'''
import torch
import torch.nn as nn
import torch.nn.functional as F
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, **kwargs):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, bias=False, **kwargs)
def forward(self, x):
x = self.conv(x)
return F.leaky_relu(x, inplace=True)
class BasicConv1x1(nn.Module):
def __init__(self, in_channels):
super(BasicConv1x1, self).__init__()
self.conv = nn.Conv2d(in_channels, 256, 1, bias=False)
def forward(self, x):
x = self.conv(x)
return x
class SMO(nn.Module):
def __init__(self):
super(SMO, self).__init__()
self.conv = nn.Conv2d(256, 256, 3, bias=False, padding=1)
def forward(self, x):
x = self.conv(x)
return x
class SetBlock(nn.Module):
def __init__(self, forward_block, pooling=False):
super(SetBlock, self).__init__()
self.forward_block = forward_block
self.pooling = pooling
if pooling:
self.pool2d = nn.MaxPool2d(2)
def forward(self, x):
n, s, c, h, w = x.size()
x = self.forward_block(x.view(-1, c, h, w))
if self.pooling:
x = self.pool2d(x)
_, c, h, w = x.size()
return x.view(n, s, c, h, w)
class Compact_Block(nn.Module):
def __init__(self, input_size, common_size):
super(Compact_Block, self).__init__()
self.bn = nn.BatchNorm1d(256)
self.relu = nn.ReLU(inplace=True)
self.dropout = nn.Dropout(0.9)
self.fc = nn.Linear(input_size, common_size)
def forward(self, x):
x = x.permute(0, 2, 1).contiguous()
x = self.bn(x)
x = self.relu(x)
x = self.dropout(x)
x = self.fc(x)
x = self.bn(x)
x = x.squeeze()
return x














 1035
1035











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









