






论文

1 Introduction
先前研究的一些缺点(sliding-window):
① 运行速度慢
② 需要权衡定位精度以及对上下文的应用

文章贡献:
① 提出改进的全卷积网络
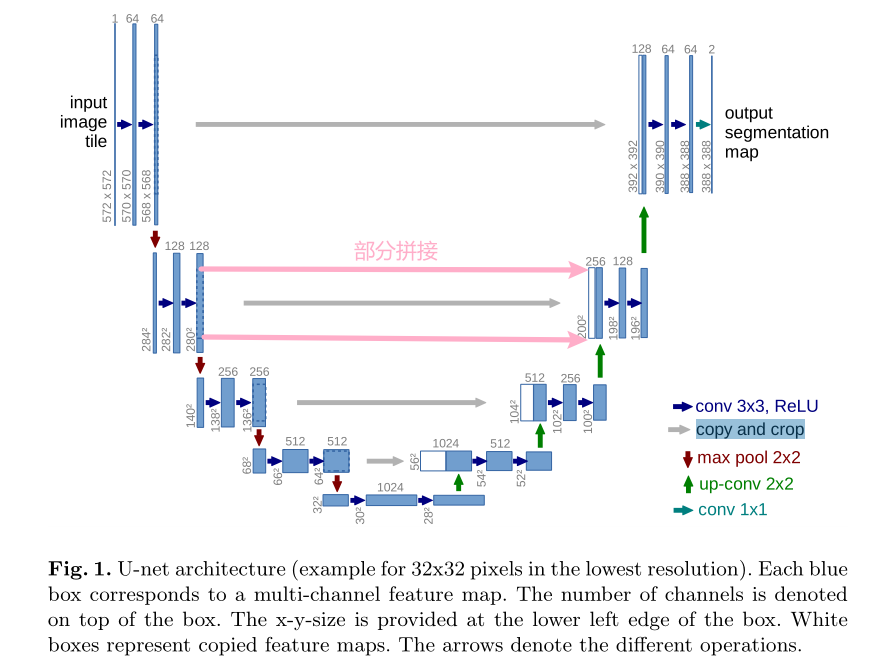
可以看出,该结构与FCN相似。然而不同的是,FCN在扩张过程中只使用了上采样,而UNet中的扩张过程利用到了卷积操作。同时,卷积操作没有使用padding,特征图会逐渐减小。
其中,上采样可以让包含高级抽象特征低分辨率图片在保留高级抽象特征的同时变为高分辨率特征,再与左边低级表层特征高分辨率图片进行concatenate操作,从而实现了更加精确的定位,并且保证分割精度。
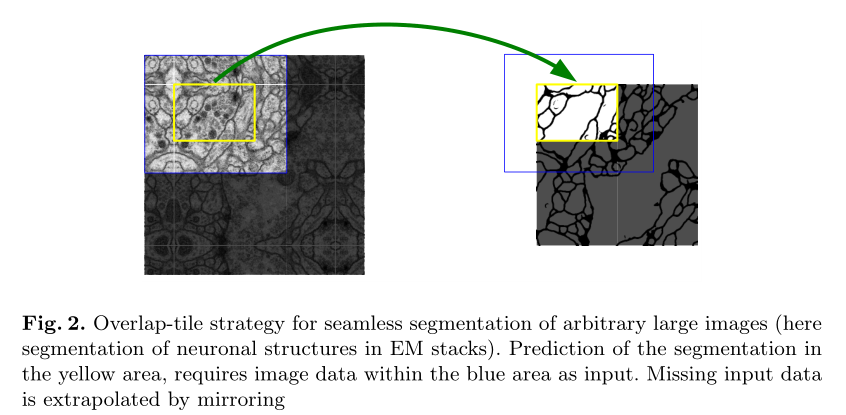
② 文章同时提出了一个无缝分割策略(overlap-tile策略)从而适配任意大小的图片输入。具体做法是:预测右图黄色区域时,需要左侧的蓝色区域大小的图像作为输入。为了实现无缝分割,输入的尺寸应该保证长和宽均为偶数。
③ 对数据进行弹性伸缩数据增强。
2 Network Architecture

需要注意的是,网络最终的输出有两张特征图,实际上代表了二分类(前景与背景)。
3 Training
网络利用交叉熵进行训练。
并且,为了网络更好的学习分割边界信息(例如细胞之间的细小缝隙),首先利用形态学操作预先计算了一个权重图。


4 Data Augmentation
除了基本的移动和旋转的数据增强方式,文中采用了弹性形变的数据增强方式。
具体来说,在一个粗略的3×3的网格上使用随机位移向量产生平滑的变形。位移是从具有10个像素标准偏差的高斯分布中采样的。然后使用双三次插值计算每个像素的位移。
在收缩路径的末端同时也采用了Dropout层,达到了进一步的隐式数据增强效果。
代码
""" Parts of the U-Net model """
import torch
import torch.nn as nn
import torch.nn.functional as F
class DoubleConv(nn.Module):
"""(convolution => [BN] => ReLU) * 2"""
def __init__(self, in_channels, out_channels, mid_channels=None):
super().__init__()
if not mid_channels:
mid_channels = out_channels
# 以下padding为1,特征图大小不会改变,与原文略有差别。
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.double_conv(x)
class Down(nn.Module):
"""Downscaling with maxpool then double conv"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.maxpool_conv = nn.Sequential(
nn.MaxPool2d(2),
DoubleConv(in_channels, out_channels)
)
def forward(self, x):
return self.maxpool_conv(x)
class Up(nn.Module):
"""Upscaling then double conv"""
def __init__(self, in_channels, out_channels, bilinear=True):
super().__init__()
# if bilinear, use the normal convolutions to reduce the number of channels
# 使用普通的上采样进行扩张
if bilinear:
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv = DoubleConv(in_channels, out_channels, in_channels // 2)
# 使用反卷积层进行扩张
else:
self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2) # 反卷积
self.conv = DoubleConv(in_channels, out_channels) # 普通卷积
def forward(self, x1, x2):
x1 = self.up(x1)
# input is CHW
diffY = x2.size()[2] - x1.size()[2]
diffX = x2.size()[3] - x1.size()[3]
x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,
diffY // 2, diffY - diffY // 2]) # 补齐边界
x = torch.cat([x2, x1], dim=1) # 连接
return self.conv(x)
class OutConv(nn.Module):
def __init__(self, in_channels, out_channels):
super(OutConv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1) # 输出层的1×1卷积
def forward(self, x):
return self.conv(x)
""" Full assembly of the parts to form the complete network """
class UNet(nn.Module):
def __init__(self, n_channels, n_classes, bilinear=False):
super(UNet, self).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.bilinear = bilinear
self.inc = DoubleConv(n_channels, 64)
self.down1 = Down(64, 128)
self.down2 = Down(128, 256)
self.down3 = Down(256, 512)
factor = 2 if bilinear else 1
self.down4 = Down(512, 1024 // factor)
self.up1 = Up(1024, 512 // factor, bilinear)
self.up2 = Up(512, 256 // factor, bilinear)
self.up3 = Up(256, 128 // factor, bilinear)
self.up4 = Up(128, 64, bilinear)
self.outc = OutConv(64, n_classes)
self.dropout = nn.Dropout(0.5)
def forward(self, x):
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x5 = self.dropout(x5) # dropout层
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.outc(x)
return logits
x = torch.randn(1, 3, 256, 256)
net = UNet(3, 2)
x = net(x)
# 特征大小的变化
# torch.Size([1, 64, 256, 256])
# torch.Size([1, 128, 128, 128])
# torch.Size([1, 256, 64, 64])
# torch.Size([1, 512, 32, 32])
# torch.Size([1, 512, 16, 16])
# torch.Size([1, 256, 32, 32])
# torch.Size([1, 128, 64, 64])
# torch.Size([1, 64, 128, 128])
# torch.Size([1, 64, 256, 256])
# torch.Size([1, 2, 256, 256])














 3981
3981











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









