






0 Abstract

· 问题:多任务学习中,通常简单任务将被不必要地强调,从而使得困难任务的训练进程被减缓(有可能造成简单任务过拟合,困难任务欠拟合,同时降低各种任务的性能);
· 解决:提出动态优先级,自适应地调整不同任务损失函数的权值。
1 Introduction
· 启发:人类进行学习时会动态分配不同的心理资源(不同学习优先级)到不同难度的任务中,而计算模型也可能做到。
· 当前多任务存在的问题:简单任务在表现好时仍占有较多资源,使得困难任务得以训练得到较好的性能。
· 关键问题:为什么课程式学习(Curriculum Learning)不能应用于多任务?将什么资源分配给位于什么优先级的任务?
① 课程式学习将单个任务分解为若干个子任务,并且按照难度递增的顺序进行训练(先训练简单任务再训练困难任务)。然而其有【任务同分布,并且随时间熵增】的假设,在多任务中,通常不同任务之间没有相同的分布;
② 可分配的资源有梯度步幅、参数统计和更新频率等。
· 文章贡献:
① 在example-level和task-level上分析得出更多的学习资源应该分配给困难任务;
② 提出一个统一框架:动态对任务的优先级进行排序,使用learning processing signals来计算权重。
2 Related Work
方法一:使用task-level权重为不同任务分配不同优先级
① 联合损失函数的权重(Loss(total) = w(t1) * loss(t1) + w(t2) * loss(t2) + …):不确定性加权(没有考虑任务难度);
② 自主学习(由模型的能力决定):梯度正则化;
③ learning progress signal:将例如准确率作为任务的奖励信号(reward signal)对任务优先级进行动态调整;
方法二:利用任务间的关系构建网络体系结构
① 硬参数共享:不同的相关任务共享主干网,但使用分开的输出层(例如全连接层),利用相关任务之间的领域知识提高泛化能力,使得不同任务之间可以进行协同学习。这有两个缺点:(1)通常loss函数需要进行合并,选择权重是一个困难的问题;(2)关键层较大的负担;
② 任务层次结构:例如在前馈神经网络中,在不同网络深度中用不同函数学习其隐式结构
3 Method
提出动态任务优先级DTP,不利用损失函数的数值,而是利用一种衡量指标KPI来衡量任务的难易程度,并给困难的任务赋予较大的权重。
① 预设:
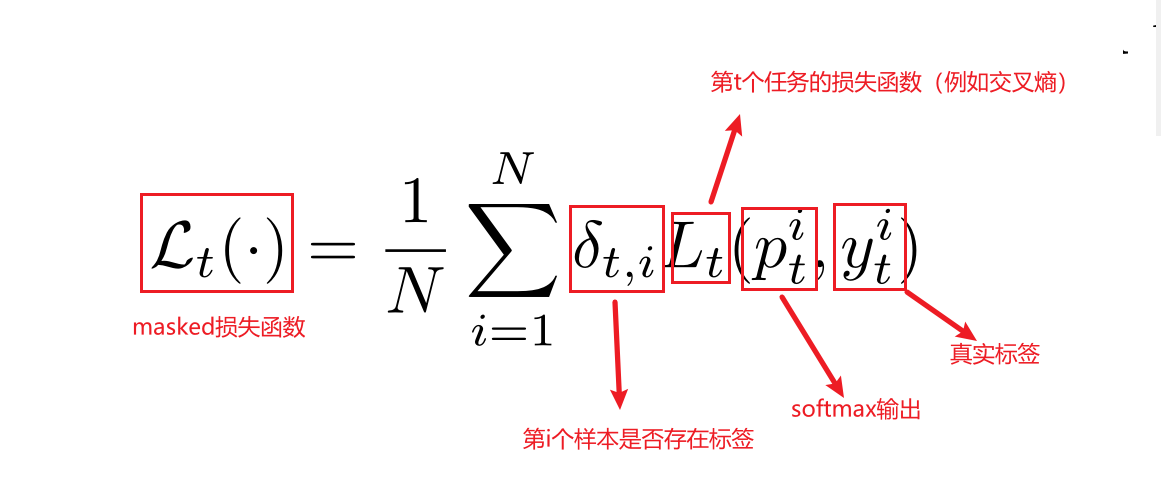

② KPI:
1)KPI需要是一个有意义的衡量指标,例如分类任务中的平均准确率,或者回归任务中关于【成功样本】所定义的【门限值】;
2)KPI的更新是基于指数移动平均值方法:
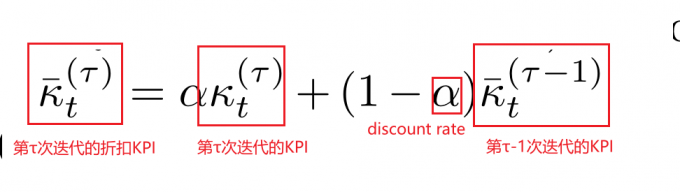
3)KPI的范围是0-1,折扣率的范围也是0-1。折扣率越大表示优先考虑最近的examples;
4)KPI不一定是需要可微的。
③ Example-level优先级:同一个任务中不同训练难度的样本
1)对于分类任务来说,有论文提出了Focal loss用于关注更难训练的样本:

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cFCazcWi-1654503650431)(D:\Typora\images\X01vcT.png)]
其中,y0是一个超参数可以用于调整。
2)对于回归任务来说,可以将Focal loss拓展到回归任务:
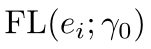
其中,ei的范围从0-1,可以是一些经过归一化的误差值。
④ Task-level优先级:不同任务的训练难度差异,借鉴于example-level:
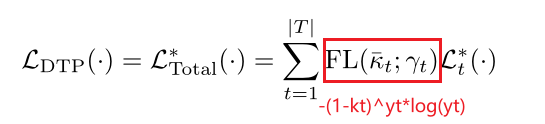
⑤ 梯度:
1)如果KPI可微,梯度是可以被正常计算的;
2)如果KPI不可微,那么梯度KPI可以被视为常数进行计算,从而达到权重的缩放效果:
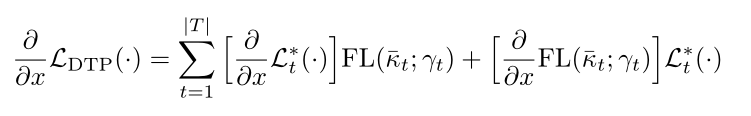
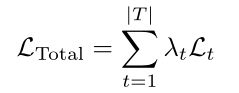
4 来自网络架构的隐式优先级
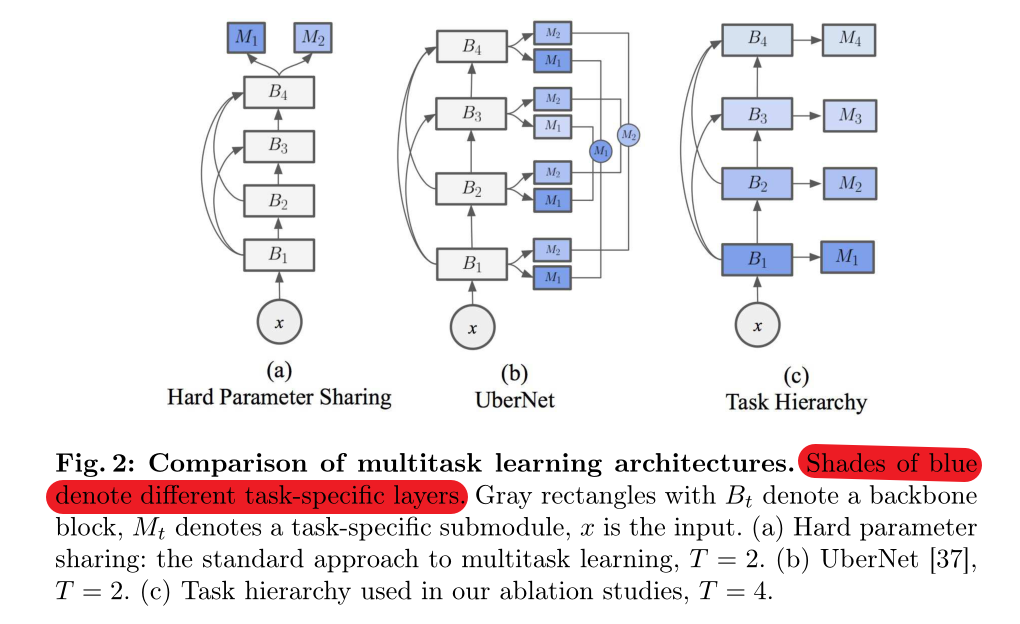
通过实验总结:在有任务层次结构的网络架构中,较难的任务优先于较容易的任务进行处理(如上图的b和c),这意味着较容易任务对应层的输出将作为较难任务对应层的输入(由于反向传播,较难任务对应的层会首先进行梯度更新)。而在a中的硬参数共享架构中,则没有这个概念。
5 讲讲什么是Focal Loss?
提出动机:在物体检测中,希望让one-stage方法的精度接近two-stage的精度。前者精度不如后者的根本原因是样本类别不均匀(负样本的数量远大于正样本的数量)。
① 普通的交叉熵:
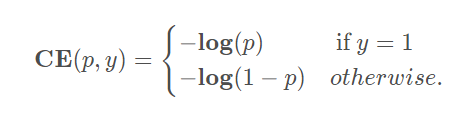
② 用p_t代替①中的p:
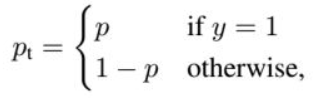
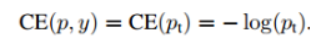
可以看出,普通交叉熵中对于正负样本都有相同的权重。这时候需要一个权重,使得对于正样本的权重更大,负样本更小:
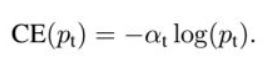
③ Focal loss的提出:
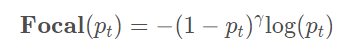
核心:减小易分类样本的权重(pt >> 0.5),从而使得模型在训练过程中注重于难样本。














 8469
8469











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









