







神经网络的学习中所用的指标称为损失函数(loss function),一般使用均方误差和交叉熵误差等。
- 均方误差
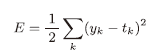
y k y_k yk-神经网络的输出, t k t_k tk-正确解标签,k-数据的维数。Python代码:
def mean_squared_error(y,t):
return 0.5*np.sum((y-t)**2)
- 交叉熵误差
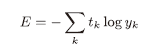
这里, l o g log log表示 l o g e log_e loge,该式只计算对应正确标签的输出y的自然对数。Python代码:
def cross_entropy_error(y,t):
delta=1e-7
return -np.sum(t*np.log(y+delta))
这里,参数y和t是Numpy数组。函数内部在计算ng.log时,加上了一个微小值delta,用于防止出现——np.log(0)=-inf(负无限大)情况的发生。
- mini-batch学习
前面介绍的损失函数的例子考虑的都是针对单个数据的损失函数,如果要求所有训练数据的损失函数的求和,以交叉熵误差为例,可以写成:
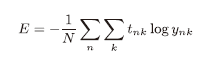
但是如果对全部数据求损失函数的和,遇到大数据的时候是不现实的。从训练数据之中选出一批数据(成为mini-batch,小批量),然后对每个mini-batch进行学习,这种学习方式成为mini-batch学习。 - mini-batch学习
假设训练数据由60000个,输入数据是784维(28x28)的图像数据,监督数据是10维的数据,则x_train、t_train的形状分别是(60000,784)和(60000,10)。接下来从这个训练数据之中随机抽取10笔数据:
train_size=x_train.shape[0] #=60000
batch_size=10
batch_mask=np.random.choice(train_size,batch_size)#从0-59999之间随机选择10个数字
x_batch=x_train[batch_mask]
t_batch=t_train[batch_mask]
使用np.random.choice()可以从指定的数字钟随机选择想要的数字。
- mini-batch版交叉熵误差的实现
实现一个可以同时处理单个数据和批量数据(数据作为batch集中输入)两种情况的函数:
def cross_entropy_error(y,t):
if y.ndim==1:#如果神经网络输出y的维度是1,即如果是单个数据的一维数组(1,784)
t=t.reshape(1,t.size) #重新定义维度,确保是一个图像数据
y=y.reshape(1,y.size)
batch_size=y.shape[0] #把数据的数赋值给batch_size
return -np.sum(t*np.log(y+1e-7))/batch_size
当监督数据非one-hot表示,而是像“0”“2”“7”这样的数据标签时【此时,t的形状不再是(数据数量,10)而是(1,数据量)】,交叉熵误差可以通过如下代码实现:
def cross_entropy_error(y,t):
if y.ndim==1:#如果神经网络输出y的维度是1,即如果是单个数据的一维数组(1,784)
t=t.reshape(1,t.size) #重新定义维度,确保是一个图像数据
y=y.reshape(1,y.size)
batch_size=y.shape[0] #把数据的数赋值给batch_size
return -np.sum(np.log(y[np.arange(batch_size),t]+1e-7))/batch_size
当t是one-hot表示的时候,直接t*p.log就可以把正确标签1对应的神经网络输出值取出,而其他的因为标签是0就全都去掉了。但是如果t是标签形式:np.arange(batch_size)会生成一个从0到batch_size-1的整数数组,比如如果batch是4个数据,np.arange(4)会生成[0,1,2,3]。t又是以标签形式[2,7,0,9]存储的,所以y[np.arange(batch_size),t]能抽取各个数据正确解标签对应的神经网络的输出(在此例子之中,为[y[0,2],y[1,7],y[2,0],y[3,9]])
- 为什么要设置损失函数
也就是问,为什么不直接把识别精度作为指标?因为识别精度对微小参数的变化基本没有什么反应,即便有反应,它的值也是不连续地、突然地变化,导数基本为0。(“导数”在神经网络学习中的作用:)而损失函数可以发生连续性的变化,神经网络的学习需要利用损失函数与参数的联系,使用“导数”来更新权重和偏置。在神经网络的学习中,寻找最优参数时,利用损失函数对参数求导(准确的讲是求梯度),然后以导数为指导,更新参数的值,达到使损失函数逐渐减小的目的。
阶跃函数也是因为不连续问题(导数几乎都为0),不能用它作激活函数。














 454
454











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









