







1.loss函数
损失函数(loss function)是用来估量模型的预测值f(x)与真实值Y的不一致程度,它是一个非负实值函数,通常使用L(Y, f(x))来表示,损失函数越小,模型的鲁棒性就越好
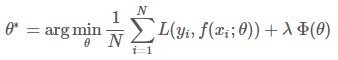
这个公式中的前一项是损失项,后一项是正则项
正则项:防止过拟合
正则方法链接(处理过拟合的问题)
2.损失项分类
现在已经接触过的
(1)线性回归问题:L2 loss,Mean Squared Loss/ Quadratic Loss(MSE loss),梯度容易爆炸
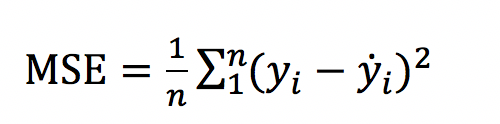
(2)分类问题:
交叉熵cross entropy loss:度量两个概率分布间的差异性信息
对于两个分布p、q,它们的交叉熵如下
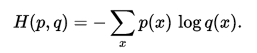
交叉熵loss:
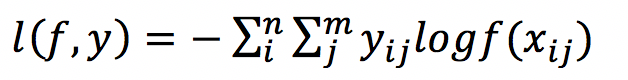
n对应于样本数量,m是类别数量,yij 表示第i个样本属于分类j的标签,它是0或者1。对于单分类任务,只有一个分类的标签非零。f(xij) 表示的是样本i预测为j分类的概率。loss的大小完全取决于分类为正确标签那一类的概率,当所有的样本都分类正确时,loss=0,否则大于0。
逻辑回归(二分类)的loss函数为:
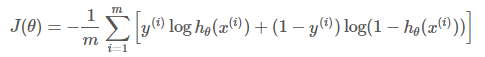
注意:softmax使用的即为交叉熵损失函数,binary_cossentropy为二分类交叉熵损失,categorical_crossentropy为多分类交叉熵损失,当使用多分类交叉熵损失函数时,标签应该为多分类模式,即使用one-hot编码的向量。
补充
(3)线性回归问题:L1 loss,梯度在0点不光滑,导致容易跳掉最小值点
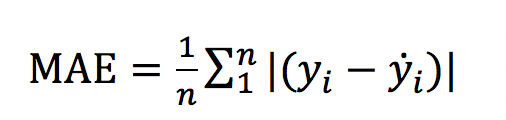
(4)线性回归问题:Huber loss,结合L1 loss和L2 loss,当预测偏差小于 δ 时,它采用平方误差,当预测偏差大于 δ 时,采用的线性误差。Huber loss增强了平方误差损失函数MSE对离群点(噪声点)的鲁棒性。
不过,Huber损失函数也存在一个问题,我们可能需要训练超参数δ,而且这个过程需要不断迭代
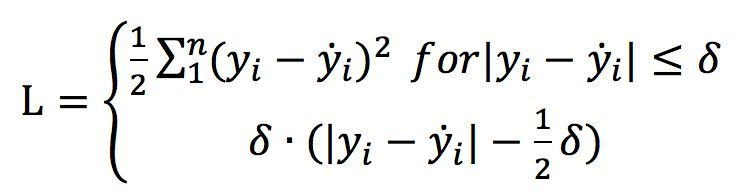
(5)Hinge loss(合页损失函数,主要用在支持向量机SVM(暂未了解)中的最大间隔算法maximum-margin中)
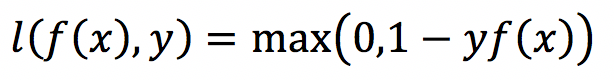
y是确定值,取+1或-1,f(x)为预测值
当f(x)>=+1或者<=-1时,都是分类器确定的分类结果,此时的损失函数loss为0;
而当预测值f(x)∈(−1,1)时,分类器对分类结果不确定,loss不为0















 11万+
11万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









