







 该文研究了在联邦学习环境中,即使少量恶意客户端也能显著影响全局模型性能的数据投毒攻击。攻击者通过控制数据集,使模型对特定类别产生高误差,而防御策略通过PCA展示恶意更新与诚实更新的聚类差异。实验表明,攻击者在后期参与和较高的可用性更具影响力,而防御方法能有效识别恶意行为。
该文研究了在联邦学习环境中,即使少量恶意客户端也能显著影响全局模型性能的数据投毒攻击。攻击者通过控制数据集,使模型对特定类别产生高误差,而防御策略通过PCA展示恶意更新与诚实更新的聚类差异。实验表明,攻击者在后期参与和较高的可用性更具影响力,而防御方法能有效识别恶意行为。
个人阅读笔记,如有错误欢迎指正
会议: ESORICS 2020 Data Poisoning Attacks Against Federated Learning Systems
问题:
在数据投毒下, 即使恶意客户端百分比很少,攻击效果也很明显
创新:
联邦学习中的数据投毒后门攻击
方法:
攻击:一定数量的攻击者参与一定轮数的攻击
攻击目标:使得最终模型对一定的类别具有高误差而其他类影响低而躲过监测。
攻击者能力:只能够控制数据集(白盒)。
防御:只显示了降维后的输出层参数的变化,中间有聚类步骤,但文中并未提及使用的是什么方法

- 选择每一轮参与的客户端
- r-1轮后的全局模型参数
- 对于选中的每一个客户端执行:
- 用本地数据训练本地模型
- 计算本地模型与全局模型之间的差值,即更新变化量
- 将模型输出层的参数
提出,添加至列表
中
- 用本地数据训练本地模型
- 将列表中的每个元素
- 使用主成分分析PCA方法对
降维
- 画图
实验:
攻击影响:随着恶意参与者百分比的增加,整体模型测试精度下降。即使m很小,我们也观察到模型精度与非中毒模型相比有所下降,并且源类精度有更大的下降。攻击者即使控制了客户端的很小一部分,也有能力对全球模型效果产生重大影响。
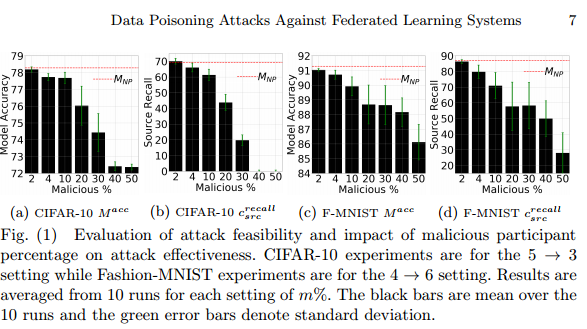
三种数据类别替换方式与实验结果的关系不太明显,在CIFAR-10中,差异较小的效果最好,在Fashion-MNIST中两者之间的效果最好
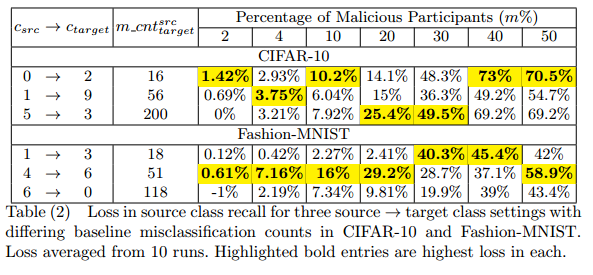
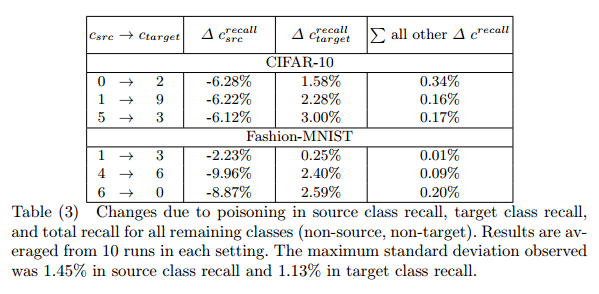
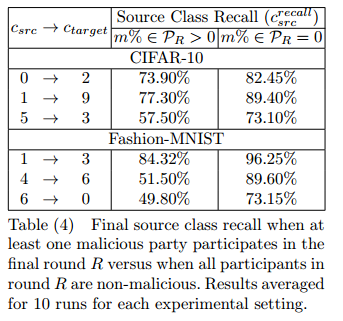
攻击具有针对性,被攻击的类别精度下降较为明显,而其他类别影响较小。全局模型精度与被攻击类别精度密切相关,比率几乎为1:10。
攻击时间对实验的影响
- 在200轮的迭代中,在75轮之前攻击在当时会对模型造成影响,但是在后续的迭代中几乎会被纠正。
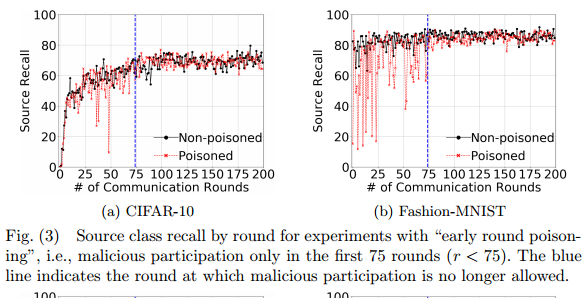
- 而75轮之后的攻击则较为有效。
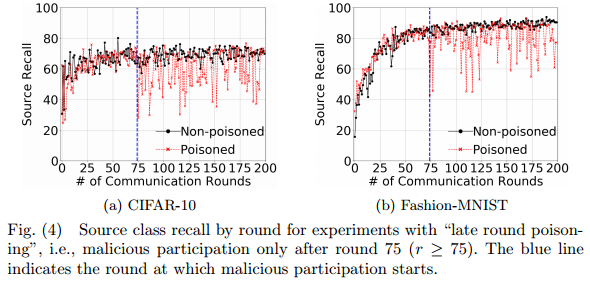
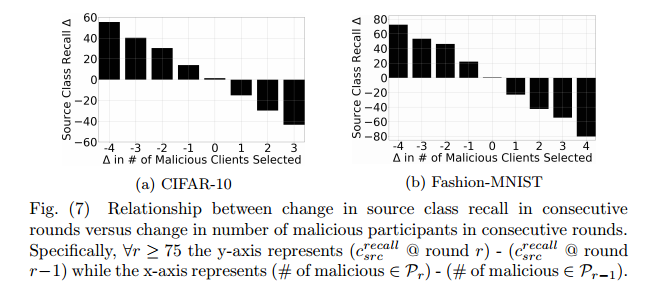
由此,标签翻转攻击的效用影响主要取决于在最后几轮训练中选择的恶意参与者的数量。
衡量的是攻击者参与攻击的可能性,也即恶意参与可用性,当对手在客户端中保持足够的代表性(即m≥10%)时,操纵恶意参与者的可用性可以对全局模型效用产生显著更高的影响,但若比率较小,可用性对实际影响较小。
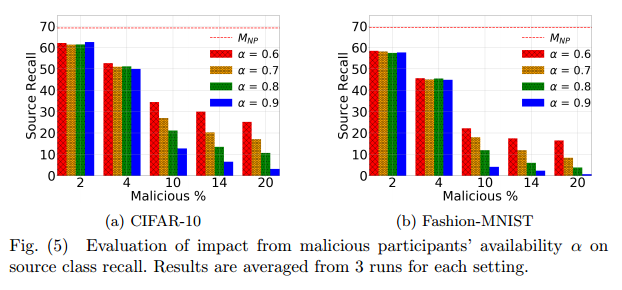
可用性越大,攻击效果越好
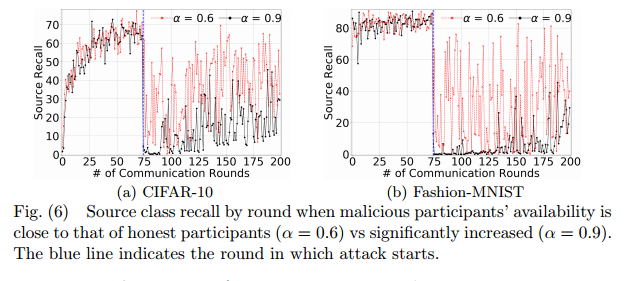
攻击者连续参与攻击,对下一轮的影响很大,反之,若攻击者持续多轮没有攻击,则模型可能显著的恢复。
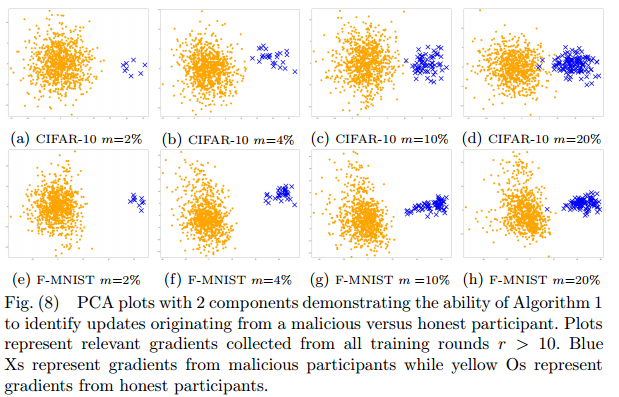
防御结果:plot结果显示,与诚实参与者的更新形成自己的集群相比,恶意参与者的更新属于一个明显不同的集群,即使攻击者较少,也能够明显识别出恶意模型,且防御并没有受到“梯度漂移”问题的影响。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









