







 FLAME是针对联邦学习中后门攻击的防御方法,它结合了模型聚类和权重剪裁来减少高斯噪声的需求,同时保护模型免受恶意更新的影响。通过HDBSCAN聚类算法检测异常模型并剪裁权重以限制单个模型的影响力,再添加适量的高斯噪声以消除后门。此外,FLAME还考虑了差分隐私,确保了模型更新的隐私安全。
FLAME是针对联邦学习中后门攻击的防御方法,它结合了模型聚类和权重剪裁来减少高斯噪声的需求,同时保护模型免受恶意更新的影响。通过HDBSCAN聚类算法检测异常模型并剪裁权重以限制单个模型的影响力,再添加适量的高斯噪声以消除后门。此外,FLAME还考虑了差分隐私,确保了模型更新的隐私安全。
个人阅读笔记,若有错误欢迎指正
会议:
USENIX Security Symposium 2022 论文地址:[2101.02281] FLAME: Taming Backdoors in Federated Learning (arxiv.org)
问题:
基于检测和过滤恶意模型更新的针对后门攻击的拟议防御仅考虑非常特定和有限的攻击者模型,基于差异隐私激发的噪声注入的防御显著降低了聚合模型的良性性能
本文通过向模型中注入噪声消除后门,并使用模型聚类和权重剪裁的方法来最小化所需的噪声。将上述两种方法的优势结合起来,同时不用undergo the narrow attacker model and loss of benign performance
创新:
1、通过以下两种策略减少所需的高斯噪声量:a)应用聚类方法来删除潜在的恶意模型更新;b)将局部模型的权重裁剪到适当的水平,以限制单个(特别是恶意)模型对聚合模型的影响。
2、为噪声注入所需的高斯噪声量提供了噪声边界证明,以消除后门贡献。
3、还考虑了如何保护模型更新对诚实但好奇的聚合器的隐私,并开发了一种安全的多方计算方法,该方法可以在实现后门防御方法的同时保护单个模型更新的隐私
方法:
问题定义及目标:
两个更新权重之间的角度及大小定义如下


下图显示了三种不同的后门攻击

,与全局模型相比具有相似的权重向量,但是又较大的角度偏差。这类模型通过加大PDR或大量的本地训练,来获得较高的后门精度。e.g. DBA
,具有较小的角度偏差,但有较大权重来放大攻击。这类模型通过放大模型权重来增强其对全局模型的影响。e.g. 模型替换攻击
,与良性模型相似, 角度和幅度没有显著差异。这种隐蔽后门可以由攻击者仔细限制训练过程或缩小中毒模型权重实现。e.g. 约束和规范攻击
模型包含三个部分:过滤、剪裁、加噪


过滤:通过动态聚类筛选出角度差异过大的模型,并将其剔除模型聚合
目前大多基于聚类的防御手段大多将模型分为两个组,其中包含数量较少的组被认为是恶意模型而剔除。1)如果聚合中不存在恶意模型,则这种方法可能会导致许多模型被错误删除,从而降低聚合模型的准确性;2)不能防止对手通过使用不同的客户端组注入不同的后门的攻击
下图显示了不同聚类方法在一组模型更新的权重向量上的行为,包含三类权重,良性模型、后门模型、随机输入模型。a显示了攻击场景的基本情况,其中使用两组客户端:一组用于注入后门,而另一组提供随机模型,目的是欺骗基于集群的防御。b显示了在这种情况下,K-means未能成功地分离良性模型和中毒模型,因为所有中毒模型最终与良性模型位于同一集群中。

本文使用成对余弦距离来测量所有模型更新之间的角度差,并应用HDBSCAN聚类算法,如果模型不适合任何集群,HDBSCAN会将其标记为异常值,可以实现检测出多个后门注入。因此,将最小集群大小设置为至少为所有客户端数量的一半,其余模型均被视为异常,如上图d
剪裁:对具有较高权重大小的权重向量进行剪裁,设定剪裁边界,超过边界的向量通过缩小权重向量进行剪裁。此处的难点是如何设置clipping bound,太大太小都会导致效果不好(太大易被攻击方钻空子,太小限制良性模型)
图显示了在三个数据集中良性客户端模型更新的平均L2范数在后续训练循环中的变化

首先计算(聚类筛选后留下的客户端)在第轮迭代中所有模型L2范数的中值,
缩放因子被定义为,其中
为模型
和全局模型之间的欧氏距离(2范数)
对于超出clipping bound的模型缩放为

加噪:通过添加噪声水平为\sigma的高斯噪声,以减轻后门模型的对抗性影响。同样如何选择噪声水平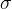 是一个难点(太高降低模型性能,太低防御可能无效)。
是一个难点(太高降低模型性能,太低防御可能无效)。
通过基于局部模型之间的差异(距离)估计灵敏度来确定噪声量,(该方法无需访问训练数据)。
将噪声添加至全局模型中,以从聚合模型中消除后门贡献。

噪声边界证明
看这一部分之前最好先搞清楚差分隐私以及高斯噪声的松弛差分隐私,参考差分隐私(一) Differential Privacy 简介 - 知乎 (zhihu.com) 差分隐私(三)- 指数,高斯,拉普拉斯机制 - 知乎 (zhihu.com)
定义噪声尺度由边界
和噪声水平因子
确定

敏感度:它代表的意思是对于两个兄弟数据集(只相差一个元素)查询函数
最大的变化范围(比如查询数量敏感度就是1)。敏感度由查询函数给出

局部模型噪声的标准差记为:其中为敏感度,
为模型
的L2范数

那么,全局模型用数学公式表示如下。W^* G^*分别为加噪后的本地模型和全局模型。该式表示由于局部模型是独立的,向每个局部模型添加噪声在数学上等同于向全局模型添加聚合噪声的情况,即,全局模型上的等效高斯噪声是应用于具有缩放因子的每个局部模型上的高斯噪声的总和,
分别为分布是
的随机变量

根据上述原理,计算等价的全局模型噪声:(显示出了全局噪声尺度和局部噪声尺度之间的关系)

在剪裁一步中使用了欧氏距离作为裁剪上界,假设敏感度和模型的权重大小是正相关的,那么在线性模型中敏感度
和权重
具有线性关系,因此可以近似为下式:

根据上述近似,全局模型的差分隐私噪声尺度可以用如下公式表示:(该全局噪声尺度是动态自适应的,因为在第轮迭代中
是变换的)

根据聚类和剪裁来对DP噪声边界的减小:
由于先进行了聚类过滤和裁剪权重两个步骤,使得通过添加DP噪声来移除剩余的后门变得更容易(得到更小的)
定理2:与良性模型的角度偏差较大或参数幅值较大的后门模型具有较高的灵敏度值∆

对定理的证明:从下式可以看到如果后门攻击改变了模型的参数大小
或方向
,则根据等式中的定义,生成的中毒模型
具有较大的灵敏度值

通过上述证明可以推断,在进行了聚类过滤角度偏差大和剪裁权重大小过大的模型后,其余后门的灵敏度较低,因此,FLAME可以使用小的高斯噪声来消除应用聚类和裁剪后的剩余后门,这有利于保持主要任务的准确性。
算法流程

使用成对余弦距离来测量所有模型更新之间的角度差,并应用HDBSCAN聚类算法。这里的优点是,即使对手放大模型更新以增强其影响,余弦距离也不会受到影响,因为这不会改变更新权重向量之间的角度。由于HDBSCAN算法根据余弦距离分布的密度对模型进行聚类,并动态确定所需的聚类数。
步骤:
1.服务器获取个用户的模型
2.计算个模型两两之间的余弦相似度
3.使用动态聚类算法HDBSCAN对两两之间的余弦相似度进行聚类,超过50%的类为良性更新。其他类均视为离群值,将其剔除,得到剩余的良性模型
4.对个模型中的每个模型计算和当前全局模型的欧式距离
,并令
5.对于每一轮的个用聚类算法筛选出来的模型,令其动态自适应剪裁因子为
6.计算剪裁后的局部模型
7.对剪裁后的局部模型赋予相同的权重进行聚合得到全局模型
8.基于局部模型之间的差异(距离)得到动态自适应噪声量,其中超参数
是根据经验设置的噪声水平因子(可参考高斯差分隐私定义)
9.得到加噪后的全局模型
实验
数据集和模型信息,在单词预测、IoT入侵检测和图像分类三个应用场景上进行了实验

在防御state-of-art后门攻击上的准确率

和state-of-art防御方法比较

模型自适应攻击上的准确率

总恶意客户端数量超过50%防御效果差

恶意客户端在每一轮中的比例对整体训练没有影响


















 1343
1343

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









