










2024智源大会Agent分会场,由清华大学自然语言处理实验室钱忱博士分享 LLM驱动的群体智能相关探索与思考,并结合ChatDev进行了解析说明。本文针对会上关键内容进行了整理,供参考。
概要
随着大语言模型的普及和应用,人们逐渐认识到单纯依靠模型参数的增加无法解决所有问题,模型的涌现能力存在局限。因此,研究焦点转向了以大模型为基础的群体智能,目标是通过多个智能体的合作来达到更复杂的任务处理和智能提升。这种方法挑战了传统智能体设计思路,为人工智能的发展提供了新的视角。当前人工智能面临的诸多问题,如信息获取的限制、专业技能的缺乏、自主能力的不足以及模型间的孤立发展,都可以通过智能体之间的协作得到缓解。智能体被赋予了使用工具、反馈循环和自我学习的能力,能通过多种方式进行互动和协作,以解决如软件开发等复杂任务。文章探讨了智能体之间的信息流通、交互方式和组织架构对提升群体智能的重要作用,并提出了解决方案如利用工具进行自我修正和通过对话机制寻求帮助。此外,还提出了多智能体协作网络的概念和在软件开发领域的应用,强调了自主交互和经验学习的重要性。最终,文章展望了未来的研究方向,包括实现人机共事模式以及在各行业的大规模应用。
会议内容
01
人工智能:协作、工具使用与未来发展
当前人工智能面临缺乏实时信息掌握、专业技能欠缺、自主能力不足及模型间孤立发展等问题。通过模型间协作、提升工具使用能力及模拟人类智能发展路径等方式,推进人工智能技术的发展。
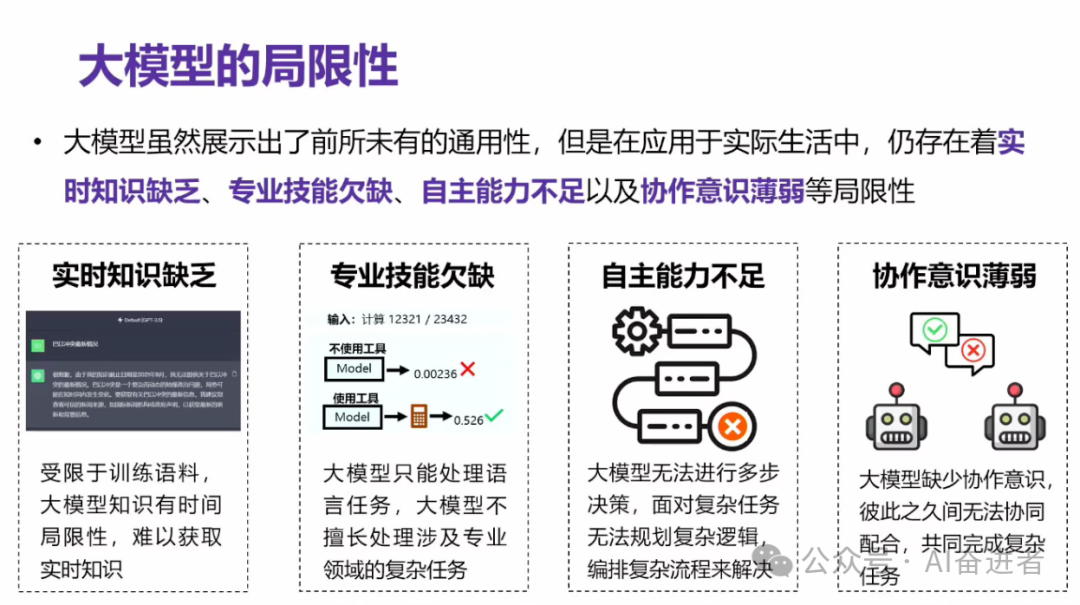
实际上,目前我们看起来人工智能的发展,很有可能会按照人类智能的一个发展的路径来向前演进。人类发展的这个发展就大概如图所示,其实我们在一个很有几千年的猿人到人阶段,其实他们的这个脑容量就发生了很大的一个增长。这种智能之后,其实这个脑容量通常就不涨了,甚至还有微微的一个降低,那么他们是怎么来征服世界的呢?
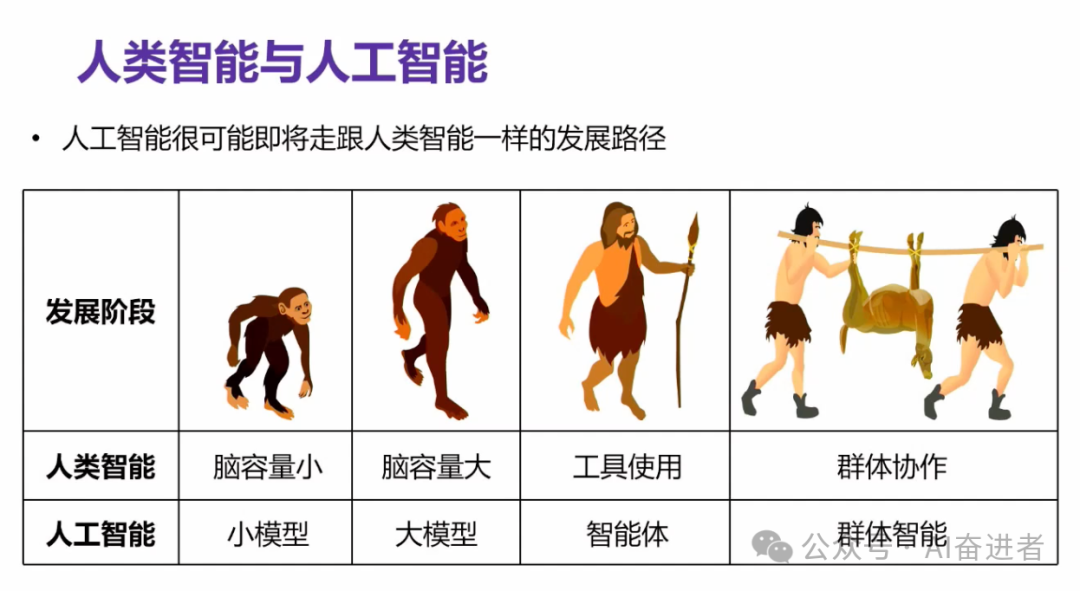
首先,他们通常会使用外部工具,比如说钻木取火等等,他们其实拥有了工具使用能力。其次,他们会做一些群体的协同。比如说我图片展示的这个群体捕猎,使得他们在一个人捕不到猎物的这种情况之下,能够通过群体的力量来解决。所以说我们在想说,人工智能目前从小模型已经发展成了一个大模型这样的一个阶段。
未来甚至说现在其实我们看到了一些叫做智能体的方向。通常来讲是说我们在大模型之上给他封装了一些额外的一个能力。比如说规划能力、记忆能力以及工具能力。工具能力实际上使得大模型能够自主的有意识的去使用外部的工具。使用外部工具可以能干嘛呢?可以实时检索他目前了解不到的知识,或者通过工具进行科学计算,最终把答案很正确的、并且很确信的展示给用户。
我们最后今天可能主要想和大家聊的一个议题是说我有不同的大模型,或者说我有不同的智能体,如何进行协同合作,进而使得产生的能力超过比如说万亿的大模型。
02
任务导向的多智能体系统:理论与应用
在讲这个之前,我们大概梳理一下什么叫做agent,或者什么叫做智能体。实际上我们其实能看到PPT里呈现的这个图,其实很直观的呈现了说大模型和智能体之间的一个主要的一个区别。

在我们看来,这个大模型类似于智能体的一个大脑,它实际上给智能体提供了这样的一个基础的一个推理的能力。大模型类似是一个大学生,掌握了一些通识教育。在此基础上让大模型长出双手来。这个是一个比喻,相当于它会使用了一些外部工具,并且拥有上下文的一些记忆以及一些规划能力,使得它从大模型演变成了一个智能体。这个智能体通常来讲与大模型相关,是大模型动态的对外呈现的一个能力。它可以自主使用工具,并且使用工具之后能从工具执行的结果拿到反馈信号,然后再做一些反思,以及更新或者学习方面的一些能力的一些拓展,使得它能够完成单个大模型成不了的一个任务。这个自主智能体,目前基本上是在大模型发展之后的一个必争之地了。

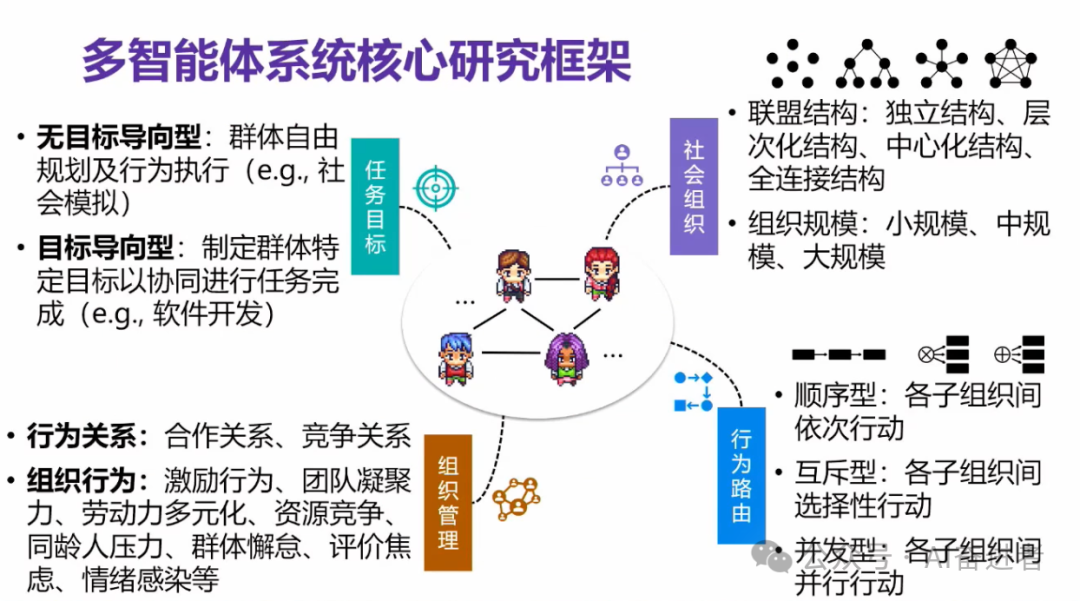
智能体系统,我们大概把它分为社会模拟型的智能体系统和任务完成型的智能体。
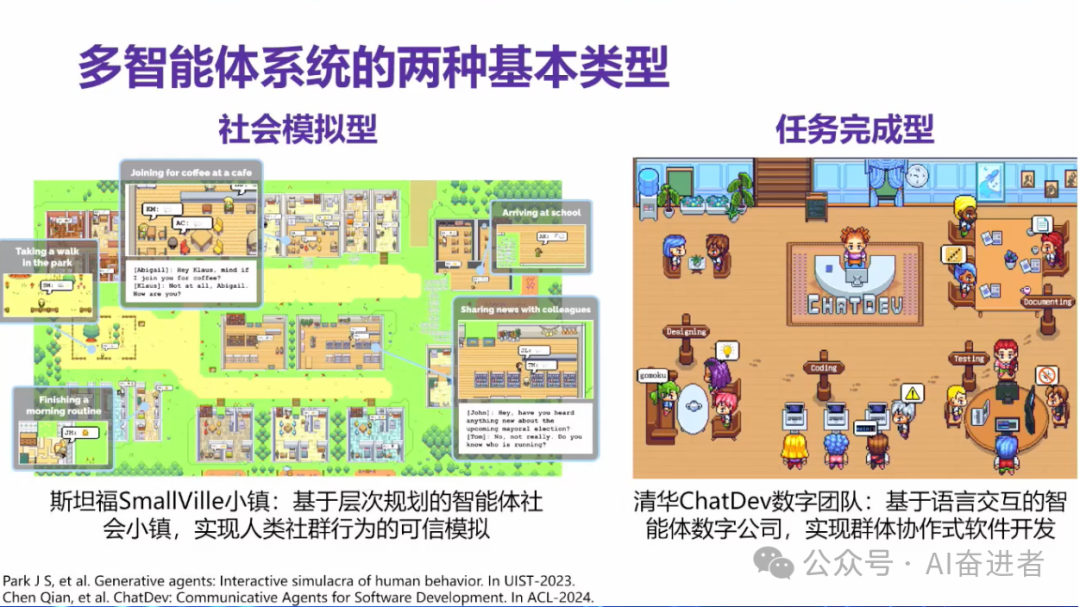
我们如何去驱动任务为导向的多智能体系统。
通过智能体,通过语音交互的形式来达到知识层面的一些融通。所以说我们提出了这样的一个框架,相当于我们有一个复杂任务的输入之后,我们就可以通过他们之间的一个交互式的一个协作来形成一个解决方案。在这个过程当中,他们也有可能产生一些演化方面的一些能力,这个在我们后面也会介绍到。
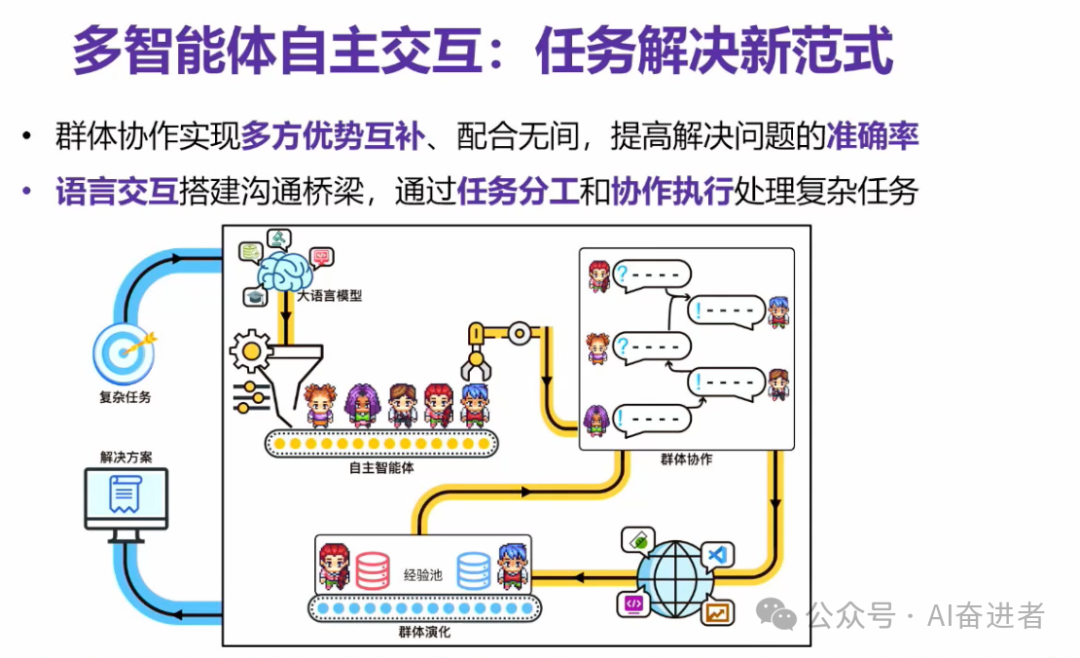
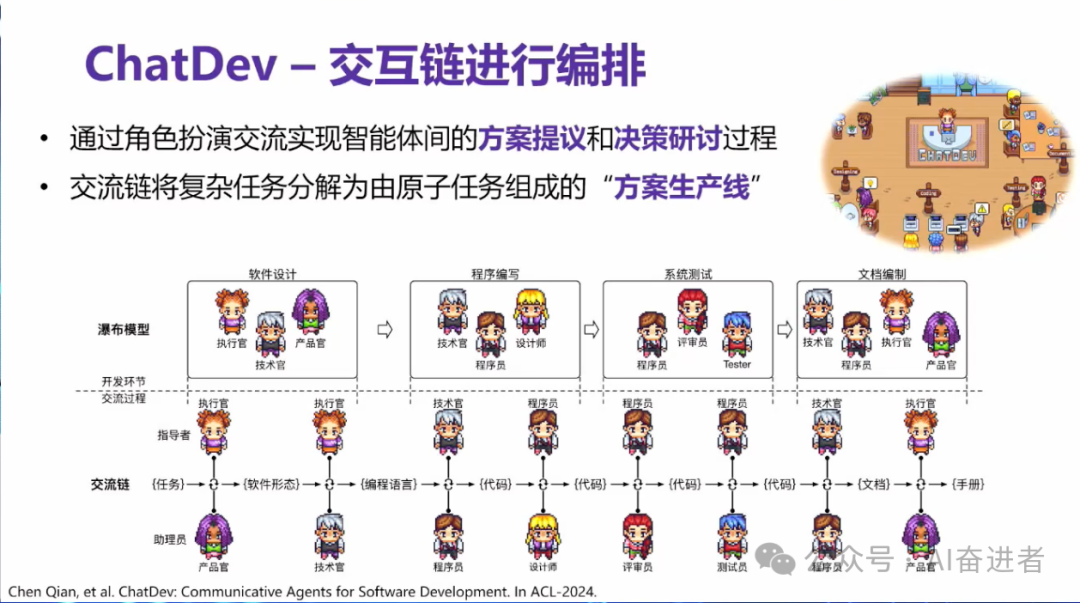
通过角色扮演的形式来使得智能体编排成一条链。那么在这个链的每一个节点之上,我们都可以通过一对智能体的交互,产生出他们应该产生的一个输出。最后可能是多轮的这个代码的讨论,包括代码的编写,代码的review, 代码的test。最后我们会基于他们生成的整个软件的源代码,再让他们讨论出我应该给用户呈现什么样的用户手册。这个用户手册就包括说这个软件怎么使用的,怎么安装的等等等等。所以说这条线,我们就把它叫做交流链。
03
提升智能体自主性与准确性:策略与实践
智能体的大脑是基于大语言模型的,大模型不可能百分之百不产生错误输出,由于它的内部的运行的一个机制,所以说造成了智能体返回给你的解决方案肯定也会有幻觉。
那么我们如何解决这个事情?我们大概列了两种比较比较好的或者说有效的解决方案。
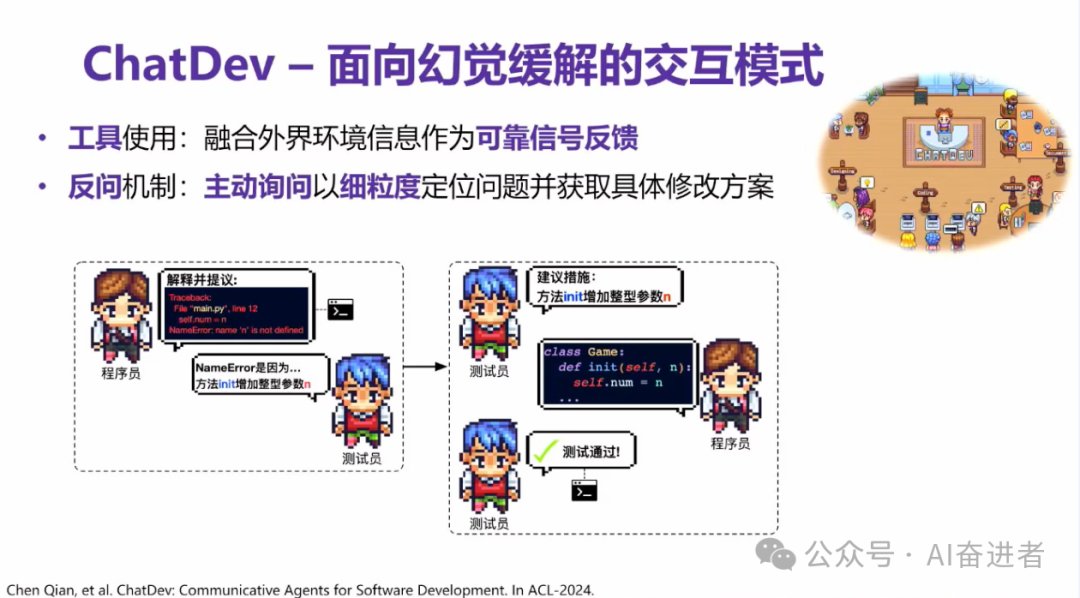
第一种是说我们通过工具的使用,使得它能够从外部获取这些信息源,从这个可靠的信息源当中,我去做一些自反思,来达到我对我之前的方案做一些修改这样的一些幻觉,去优化,或者是在缓解这样一个目的。其次,其实智能体我们最好让它自主一些,就我们尽可能减少人为干预。所以说我们也有可能我们教他怎么去聊。其实我们提了一个反问的一个机制。使得说我智能体在回答一个问题之前,如果信息漏洞的话,需要主动的去询问,说OK我哪行代码写错了,具体我该怎么修改。在有了细腻度的问题定位,以及说更好的一个解决方案。但给出之后,他更有可能把这个问题给修复掉。
我们是通过这种可以理解为硬的工具型的和软的这种对话型的两种机制来缓解幻觉现象。所以说我们没有把它叫做幻觉消除。因为我们看来可能幻觉没有办法百分之百的消除,所以我们想通过这样的一些机制来做一些缓解。
针对多智能体的需求分析和设计,以及这个软件的评审和测试见如下两张图。
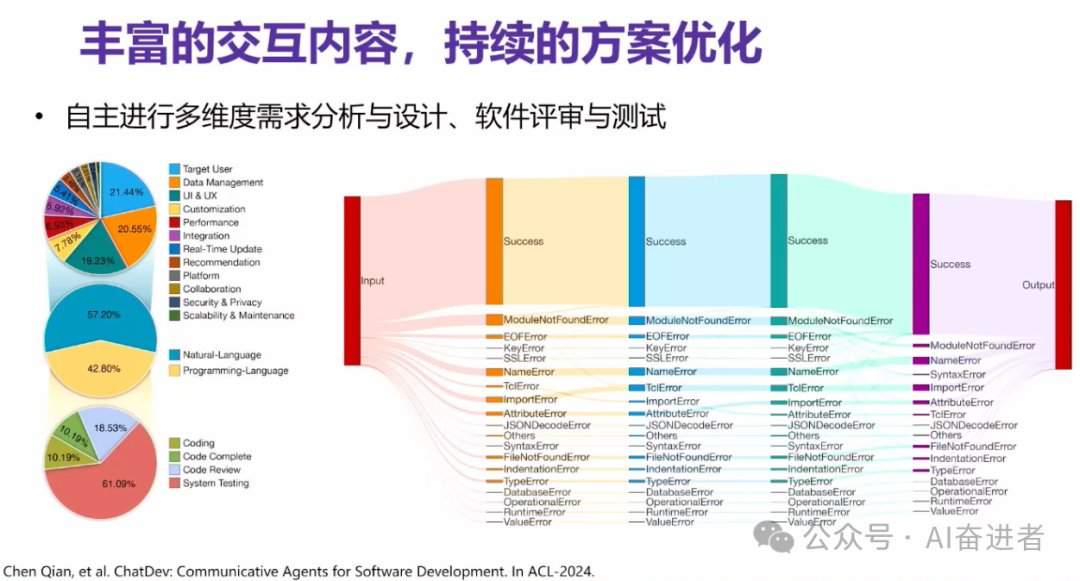
左边的这个图,其实展示的是说智能体交互的这个过程。他们在交互什么内容。您可以看到说智能体之间他们会自主的去交互。就比如说这个就是target user, 就是目标用户,他们以及数据管理UI以及定制化等等各方面的内容。这些内容都是自智能体自主的去参与讨论和设计,都是不需要人为预先定。
右图展示的是说我们在多次软件迭代,它会有什么问题,或者它是否成功了这样的一个信息流。Success表示这个软件其实它要成功了,如果是error的话,其实它其实就是还有问题,还有bug。那么您可以看到说他每一轮修改其实会在不同的error之间,或者从error到success,也有可能从success到error之前这样的去流动。但是总体来讲,随着智能体交互的增多,它的error是越来越少的,它的成功率会越来越高。
实际上大家可能看到说这些规模的软件实际上还不太可能一下子投入到应用。这个确实是这样。但实际上在这样的一个规模的软件开发之下,对于智能体或者大模型其实还比较复杂。因为比如说您可以考虑一个五子棋的一个这样的一个游戏,他假如说代码有2两300行,实际上代码哪怕错一行,这个软件就基本上不起来了,基本就编译错了。


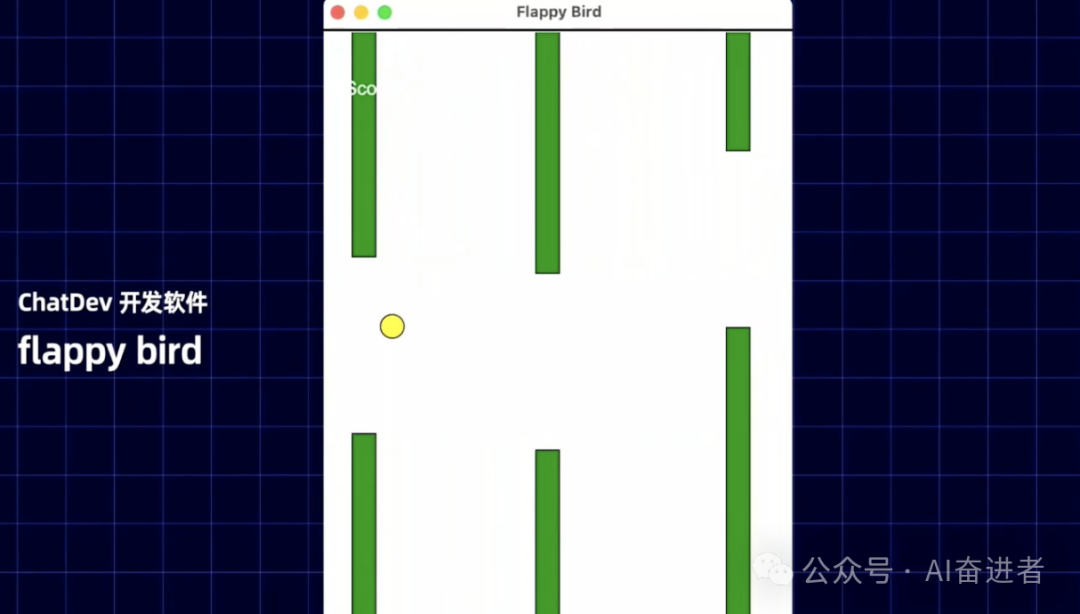
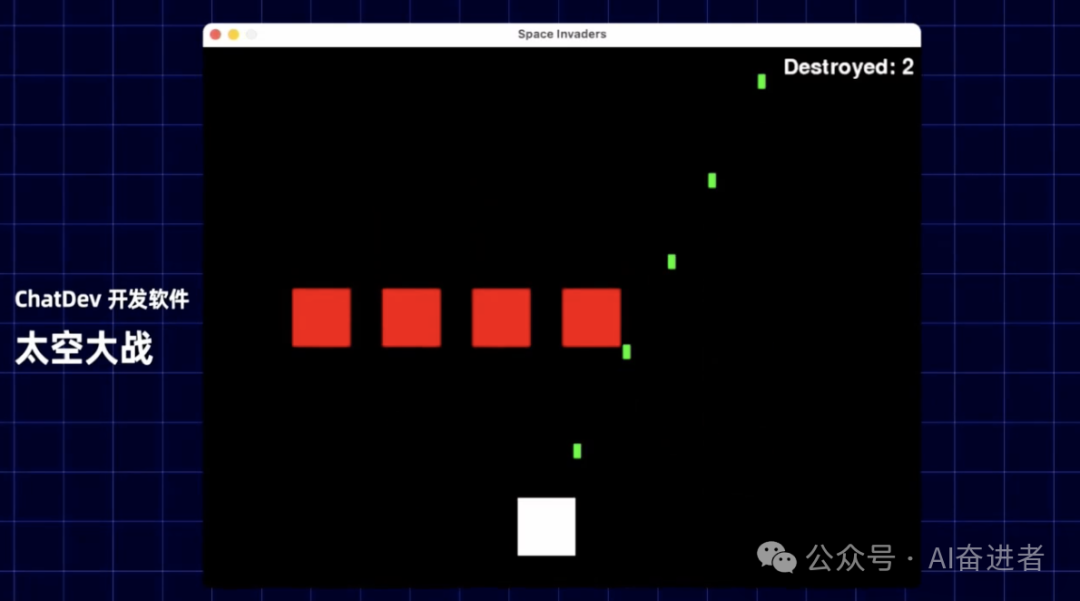

实际上我再让他做另做一次五子棋,他有可能还是按照那个逻辑再给我来一遍,有可能产出可能是相似的或者一致的。实际上我们认为,智能体在完成任务之间其实是缺乏这种过往经验的。过往经验的缺乏,导致了说我们在未来再重新做相似或者相同的任务之下,我们就产生了一个推理浪费。所以实际上说我们为了去增强多智能体的一个推的一个效率,我们其实需要给智能体赋予跨任务的一个经验。
04
构建多智能体协作网络:理论与应用
其实类似于人类的成长,为什么我们会有经验呢?因为我们犯过错了,我们知道哪些是对的,哪些是错的,才能够以此指导我们未来应该怎么去决策。
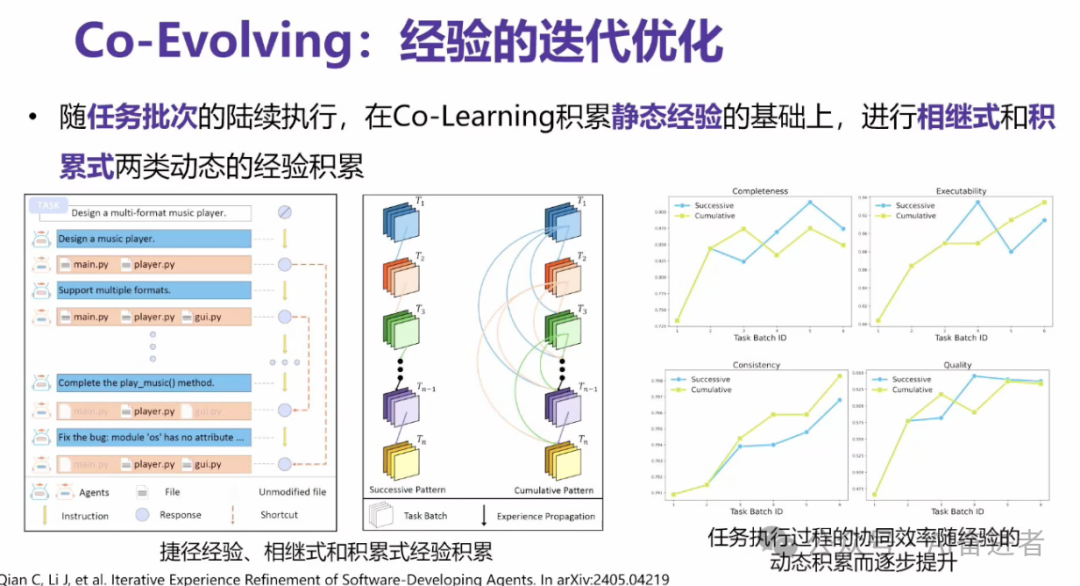
大家可以类似做图,我做了一个示例,可以认为右图的五个点是我们完成一个事情的五个版本。比如说V1一直到V5,实际上我们在这里给智能体定义的经验是这种捷径。
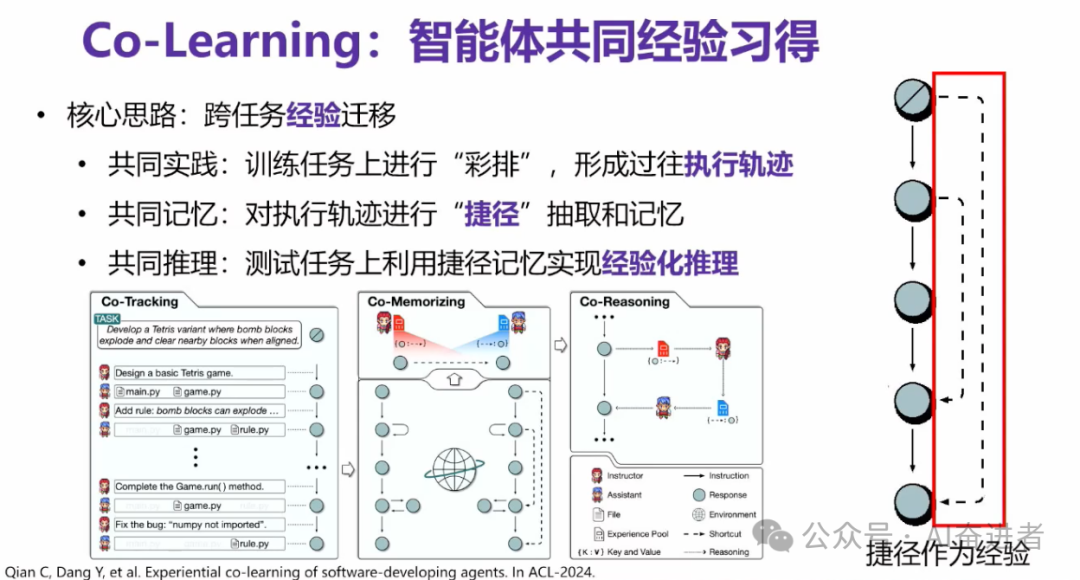
就比如说我们从V2能跳到V4,或者从V1直接跳到V5。假如智能体有了这种捷径的经验,并且存下来,未来能够检索来类似的去推理的话,那么有可能我们未来在做一件事情的时候,理论上从V1做到V10你才能做好。有了这种经验之后,你有可能从V1先做到V5的水平,然后再做到V10的水平。你只用花两步。所以说我们通过这样的一个思想,很有效的来提高了这个智能体经验的一个共同的一个进化。
这个图展示的是说我们带经验的智能体验,还有一些不带经验的智能体,推理的步骤的一些显著减少,以及说它实现了更显著的一个这样的增效。
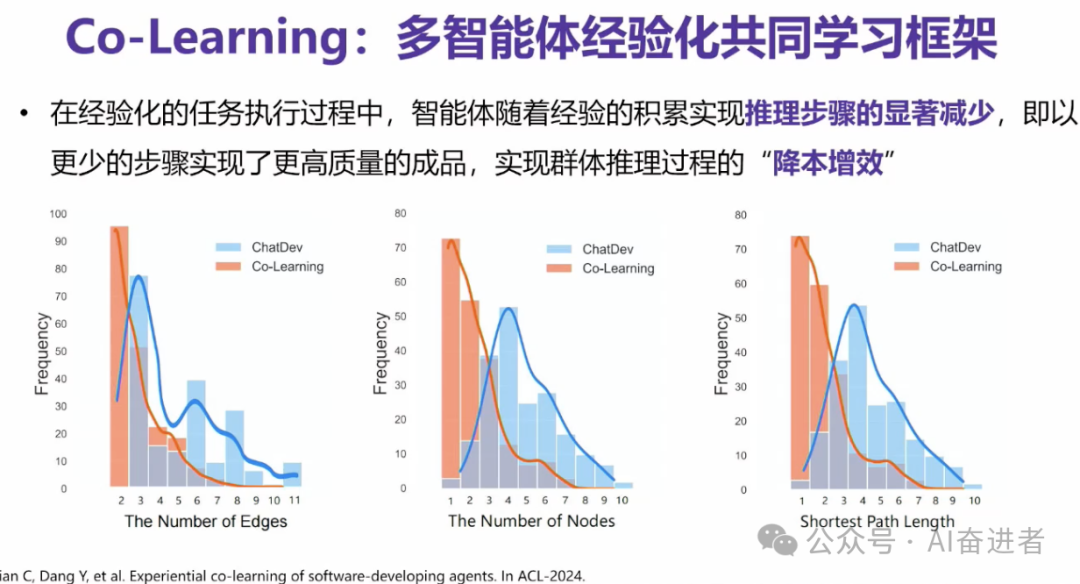
实际上我们智能体在积累了一批经验。在使用的这个过程,实际上类似于智能体的一代,你的经验传给了下一代,让下一代去解决。
实际上我们其实智能体之间是可以传递多代的。这个地方就涉及到我们智能体之间的经验,怎么传递给后代。我们可以通过这种比如说爷生父 父生子,也可以通过爷的经验和父的经验,所有潜在的竞争全都传递给后代。所以我们提了这种相继式和积累式的传送动态经验的一个积累的方式。我们也可以看到,智能体在随着经验增长的同时,它所完成的这个任务质量也会越来越高。
我们也考虑说智能体有没有可能符合一种scaling law,达到了百亿模型或者千亿模型造成的这种很强的一个智能。假如我一个多智能体系统,我扩增了或者拓展了多智能体的数量,也类似于我这种员工增加了,我有没有可能造成更高阶的这样的一个智能智力的产生。所以这个其实我们是想研究这样的一个事情。这样的一个事情研究其实还是比较复杂,通常涉及到比较通用的一个组织结构,合理的路由的策略。以及建立一些有效的记忆管理,我们才能够把多智能的系统给大家解释起来。
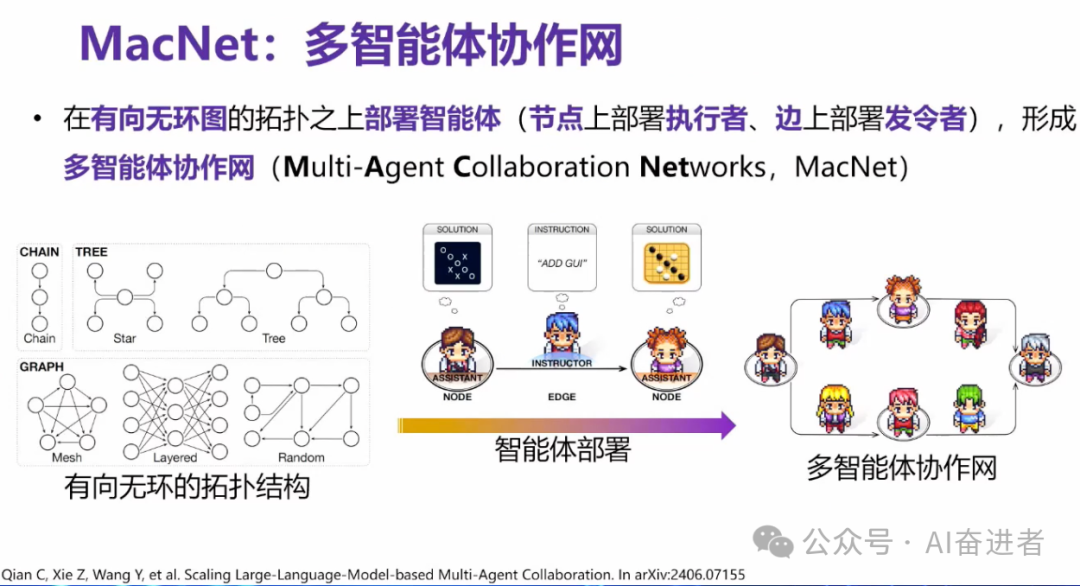
我们提出了MacNet。我们叫做多智能体协作网,类似于左图是我们在对多智能体做编排的时候,他们应该以一个什么样的组织架构去编排,类似于一个公司,尤其是大部分公司都是以树形的结构层次化的去编排的。你有一个上级,然后你有多个下属。
有了一个拓扑之后,我们需要它就类似于我们一个公司或者一个地图。这个之后,我们需要把我们的智能体部署在上面。这个地方其实我们采用了一个比较的一个做法,我们是把一个图或者说一个拓扑的节点上部署了一个assistant或者叫做助理。然后边上其实我们部署了导师。他们的功能助理通常会提供解决方案。导师类似于老师,他会提供一个修改的一个方向,所以说您可以看到说我们在某一个拓扑之下,如果把所有的学生都布在上面,所有的老师都布在上面,那么我们通过老师和学生这样的一个交互,多轮的就能够达成说老师可以提供相应方向的指导,学生可以提供相应方向之下的一个解决方案。这个可能造成我们通过这两种角色实现了这种群体比较更可拓展的这种组织的拓扑。
后面,我们讲到的是这个拓扑的一个排序。就是说我们有了一个拓扑之后,怎么样去编排智能体OK,到底谁先发言,谁后发言,谁先行动,谁后行动。这个地方其实为了和我们的网络拓扑几乎是信息的流向是一致的。所以我们其实提了这个拓扑排序,基于拓扑排序的这个网络便利。
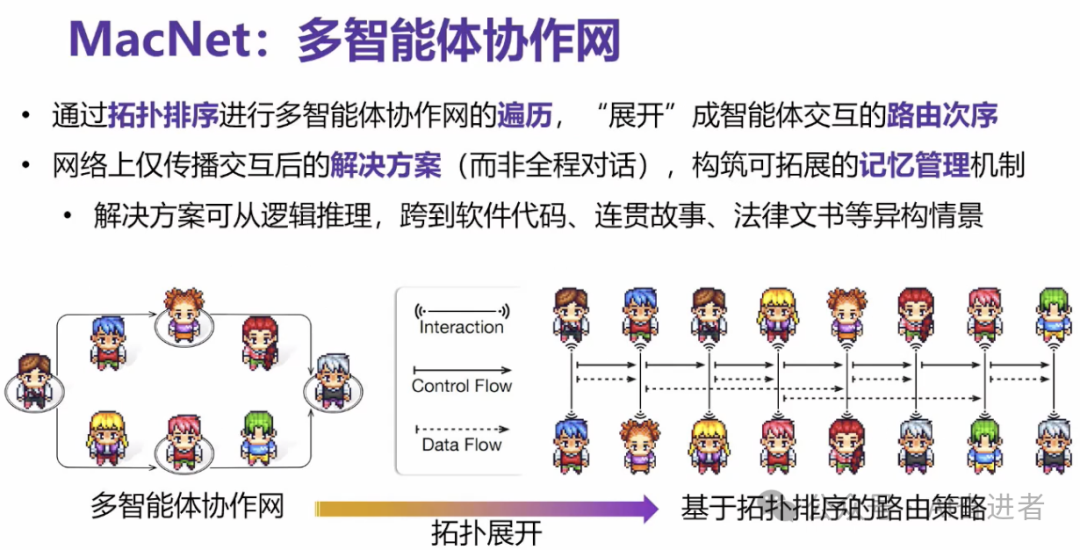
我们基于拓扑排序来指导智能体遍历到谁就谁发言。通过这样的一个情况,我们就能够展开成这种智能体交互的这种路由的一个次序。同时多智能体系统有一个比较棘手的问题,就是我人多了,聊多了,信息量就很大,信息量很大的话有可能会超长,就是可能会大家可能懂的就是大模型的长度限制。这个肯定是有一定限制的。所以在这个方面,我其实做了一些也是比较垂直的一些事情。
我们在整个智能体交互的网上,仅仅传播他们的解决方案,而不是传递整个对话过程。这样的一个情况,使得说我几乎可以承载非常大规模的一个智能体系的协同。因为我仅仅把解决方案给后面,那后面只能看到这个问题,并不知道我之前聊过的全程的信息,可能也没必要。
所以其实我们通过这样的一个事情,使得我们的这个MacNet能够解决事情其实比较多,包括逻辑推理,或者跨到这个软件代码。连贯的故事编写甚至法律文书的一些各方面的一些讨论等等。其实它是比较通用的一种,通用性比较强且可拓展的这种多智能体协作的一个网络。
现在几乎能承载上千个智能体,我们大概能承载1275个智能体协同去完成一个工作。同时我们也发现一些比较有意思的现象,包括一些小事件协同性,多智能体的架构越接近小世界网络的属性,综综合性能往往会越好。同时我们也初步发现了一些协同缩放法则的一些可能性。
我们目前做了一些平均的一些实验结果,大概能够看出来多智能体系统随着多智能体数量的一个增加,那么它产生的这个任务的性能是形成这种sigmoid的形,或者叫logistic形的一个上升的趋势。我们要把这个线上的称作协同数字化法则。
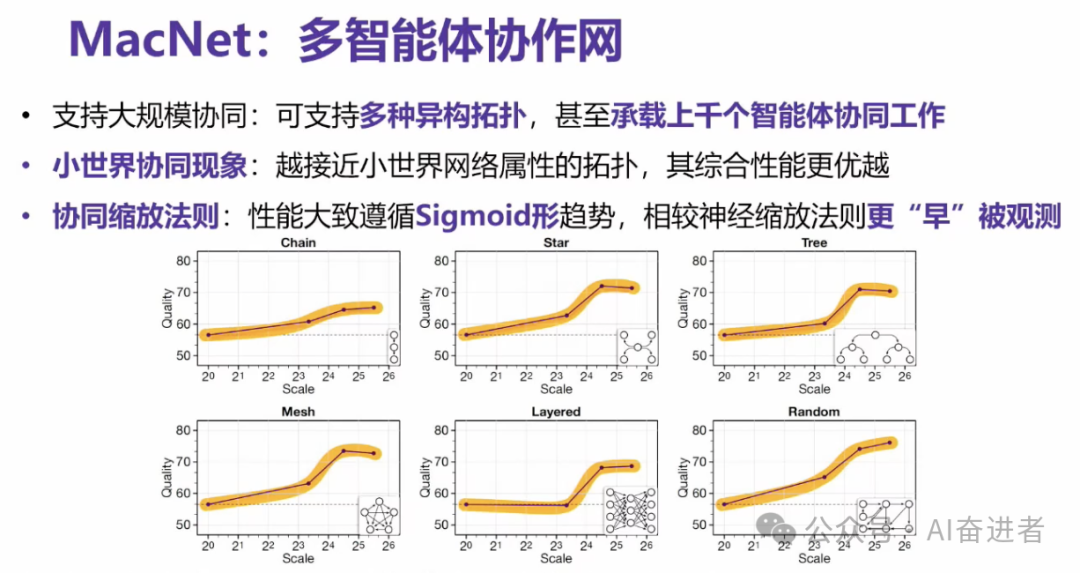
他还有一个比较有意思的现象是说,他在上升的那个区间,或者说涌现的那个点,通常会比传统的基于神经的这个涌现发现的要早。就是我可能在很小的多智能体协同的规模之下,就能够发现这样的一个东西了。而不像神经的scaling law, 你可能得scale到100倍、1000倍才有这样的一个现象发生。因为时间问题,我们大概就列了一个之前的综述。
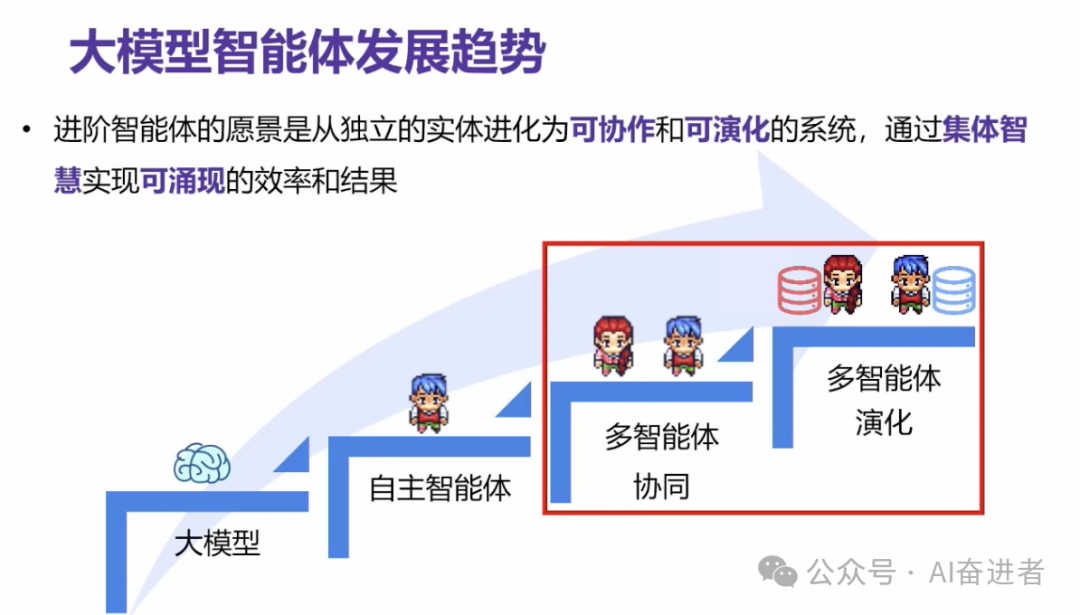
实际上我们也期待说这个智能体的一个愿景,是从这个独立的实体,比如说从这个大语言模型到自主智能体,到多智能体协作,最后到演化,然后产生一个可用性的效率,或者说一个结果。最后我们也是说未来也许智能体和人能够共同的工作产生这种Internet of Agents, 就是人类和Agents共同去协同,去工作,去辅助,然后去促进这样的一个美好的一个愿景。
如果对学术或者这方面的技术比更想再深挖一下的话,有一些主要的参考文献,提供一些可能学者的信息的学者来来做一些检索。

问答内容精选:
我们把可以把一个复杂的软件做一个层次的切分。比如说你把一个软件切分成模块,模块切分成类,类切分成方法。可能再继续往后拆分,你可以发现一个软件是一个树形结构组成的代码块。你可以想象,如果我在对一个功能进行了一个非常细分的拆分之后的叶子节点,实际上是很简单的,也许就是一个排序。所以说我大概想表达的意思,我们大概觉得说软件开发这样的一些事情,其实没有难在写代码是难在做这个树的planning。但凡如果树的planning做的非常好,就是叶子节点的补全代码的这个工作。其实目前大模型也可以,因为它的功能很简单,就是大概是这样的方法,所以其实我们更多的是在探究说怎么对一个任务做一个拆解,拆解的越精细越准确,可能会更好。
关于我:AI产品经理(目前在寻找新机会),主要关注AI Agent 应用方向。公众号:AI奋进者。如有好的想法欢迎一起沟通交流。
Agent系列框架文章,欢迎点赞、转发,更多内容,可关注微信公众号:AI奋进者。
2024-北京智源大会-通用人工智能的关键问题及思考-李开复、张亚勤
Agent系列文章已经逐步更新:
Agent知识库:功能、原理浅析 https://blog.csdn.net/letsgogo7/article/details/139030233
https://blog.csdn.net/letsgogo7/article/details/139030233
Agent 系列之 ReWOO框架解析https://blog.csdn.net/letsgogo7/article/details/138259507
Agent系列之 Plan-and-Solve Prompting 论文解析https://blog.csdn.net/letsgogo7/article/details/138259154
Agent系列之LangChain中ReAct的实现原理浅析https://blog.csdn.net/letsgogo7/article/details/138197137
Agent系列之ReAct: Reasoning and Acting in LLM 论文解析https://blog.csdn.net/letsgogo7/article/details/138259590Agent 系列之 LLM Compiler框架解析https://blog.csdn.net/letsgogo7/article/details/138284351
Agent 系列之Reflection框架解析https://blog.csdn.net/letsgogo7/article/details/138392568


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









