







 论文介绍了一种新型的增强型语言模型ReWOO,通过分离推理与观察,减少Token使用并提高复杂任务下的鲁棒性。与ReAct相比,ReWOO通过全局规划降低与LLM的交互,优化了模型效率和准确性。
论文介绍了一种新型的增强型语言模型ReWOO,通过分离推理与观察,减少Token使用并提高复杂任务下的鲁棒性。与ReAct相比,ReWOO通过全局规划降低与LLM的交互,优化了模型效率和准确性。
ReWOO (Reasoning WithOut Observation),可以解决ReAct的冗杂问题,减少Token使用,并且在相较复杂情况下,表现了比ReAct等框架下更好的鲁棒性。
论文摘要
【论文标题】:《ReWOO: Decoupling Reasoning from Observations for Efficient Augmented Language Models》;
【发布时间】:2023.05.23;
【论文链接】:https://arxiv.org/abs/2305.18323;
【内容摘要】
论文主要介绍了一种新的增强型语言模型(ALM)方法——ReWOO,旨在解决现有ALM系统计算复杂度高、重复执行等问题。该方法将推理过程与外部观察分离,从而显著减少token消耗,并在六个公共NLP基准测试和一个定制数据集上实现了性能提升。此外,这种方法还可以通过解耦参数模块和非参数工具调用来实现指令微调,从而将大型语言模型卸载到更小的语言模型中,大大减少了模型参数(本文不展开,感兴趣的朋友可自行查阅)。
主要内容
论文方法
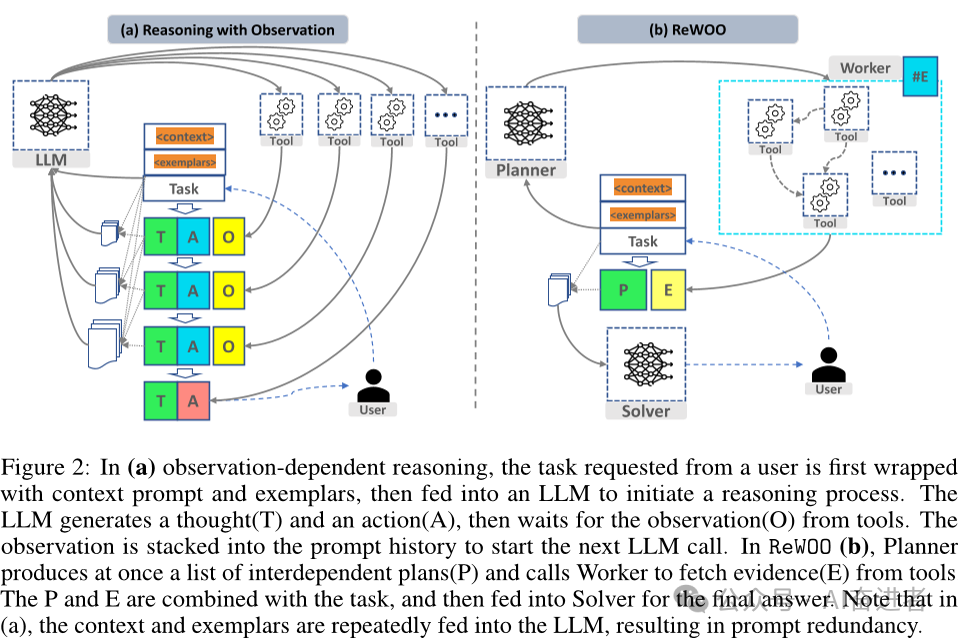
ReWOO(Reasoning with Work and Solve)框架包含三个部分:Planner、Worker和Solver。其中,Planner使用可预见推理能力为复杂任务创建解决方案蓝图;Worker通过工具调用来与环境交互,并将实际证据或观察结果填充到指令中;Solver处理所有计划和证据以制定原始任务或问题的解决方案。
图 2:在 (a) ReAct中,首先使用上下文提示和示例对用户请求的任务进行包装,然后将其馈入 LLM 以启动推理过程。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1281
1281

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









