






Reflexion: Language Agents with Verbal Reinforcement Learning论文介绍了一种名为“Reflexion”的新框架,通过反思提高决策能力。
论文摘要
【论文标题】:《Reflexion: Language Agents with Verbal Reinforcement Learning》;
【发布时间】:2023.10.10;
【论文链接】:https://arxiv.org/abs/2303.11366;
【内容摘要】
这篇论文介绍了一种名为“Reflexion”的新框架,用于强化LLM Agent,而不是通过更新权重的方法进行学习。传统的强化学习方法需要大量的训练样本和昂贵的模型微调,这对于把大型语言模型(LLMs)与外部环境进行交互作为目标驱动的代理来说仍然是具有挑战性的。Reflexion通过将任务反馈信号转化为反思,并将其保存在循环记忆缓冲区中以诱导更好的决策,在后续试验中提高决策能力。该框架灵活地集成了各种类型和来源的反馈信号,并在多种任务上取得了显著的改进,包括序列决策、编码和语言推理等。例如,在HumanEval编程基准测试中,Reflexion实现了91%的准确率,超过了之前的GPT-4(其准确率为80%)。此外,作者还进行了不同反馈信号、反馈集成方法和代理类型的分析和实验,提供了对性能影响的见解。最后,作者发布了所有代码、演示和数据集,以便其他人可以尝试并进一步研究这个新框架。
主要内容
方法描述
“Reflexion”强化学习框架,它由三个不同的模型组成:Actor、Evaluator和Self-Reflection。Actor模型使用大型语言模型(LLM)来生成文本和动作,并在环境中接收观察结果。Evaluator模型负责评估Actor产生的轨迹的质量,并计算一个奖励分数以反映其性能。Self-Reflection模型则对反馈内容进行反思,为后续流程提供有价值的反馈信息。这三个模型共同协作,在任务中不断迭代优化,从而提高决策能力。
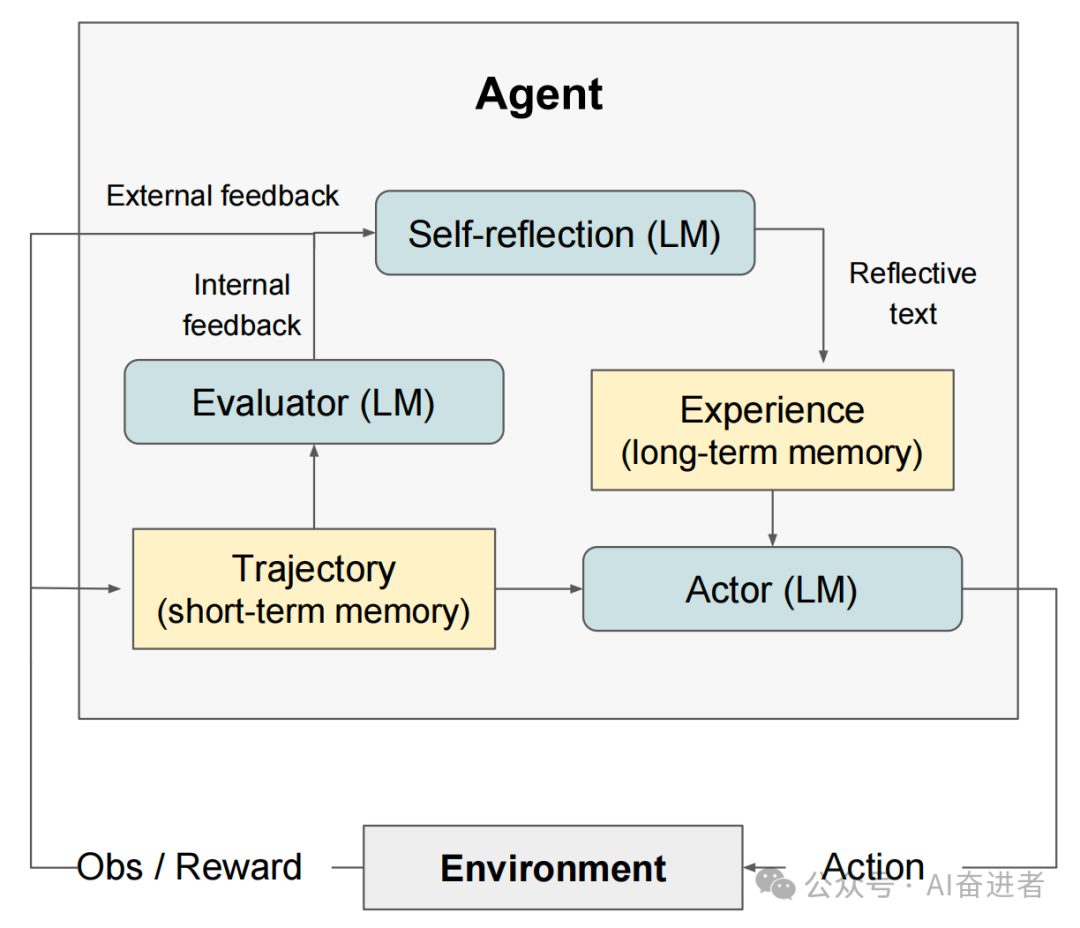
方法改进
该论文提出的“Reflexion”框架引入了记忆机制,包括短期和长期记忆。短期记忆用于存储最近的任务历史记录,而长期记忆则存储来自Self-Reflection模型的经验反馈。这种记忆机制使得Agent能够记住重要的经验并应用于后续的决策过程中,从而提高了决策能力和适应性。
解决的问题
该论文主要解决了强化学习中的两个问题:一是如何评估生成的输出质量;二是如何提供有用的反馈信息以帮助Agent改进自身的表现。通过设计有效的奖励函数和自省模型,该论文提出的“Reflexion”框架可以有效地解决这些问题,从而实现更高效的决策过程。
文章优点
该论文提出了一种新的强化学习方法——Reflexion,通过利用自然语言来优化策略,并使用自反反馈来帮助智能体从过去的错误中学习。相比于传统的强化学习方法,Reflexion具有以下优点:
-
不需要对大型语言模型进行微调;
-
允许提供更细致的反馈信号,例如针对特定行动的改变;
-
提供了更明确和可解释的前向记忆,以及更具体的下一步操作提示;
-
可以避免传统强化学习中的黑盒问题,提高智能体的可解释性和诊断能力。
方法创新点
该论文的主要贡献在于提出了Reflexion这一新型强化学习方法,并在实验中证明了其有效性。具体来说,该方法有以下几个创新点:
-
利用自然语言作为反馈信号,将二进制或标量环境反馈转化为文本形式的自反反馈,从而为智能体提供了更加清晰和可解释的方向;
-
使用长短期记忆(LSTM)网络存储自反反馈经验,以便于智能体在未来的学习过程中参考;
-
在LeetcodeHardGym环境中进行了大量的实验验证,证明了Reflexion在决策制定、推理和编程任务上的有效性。
LangChain实现
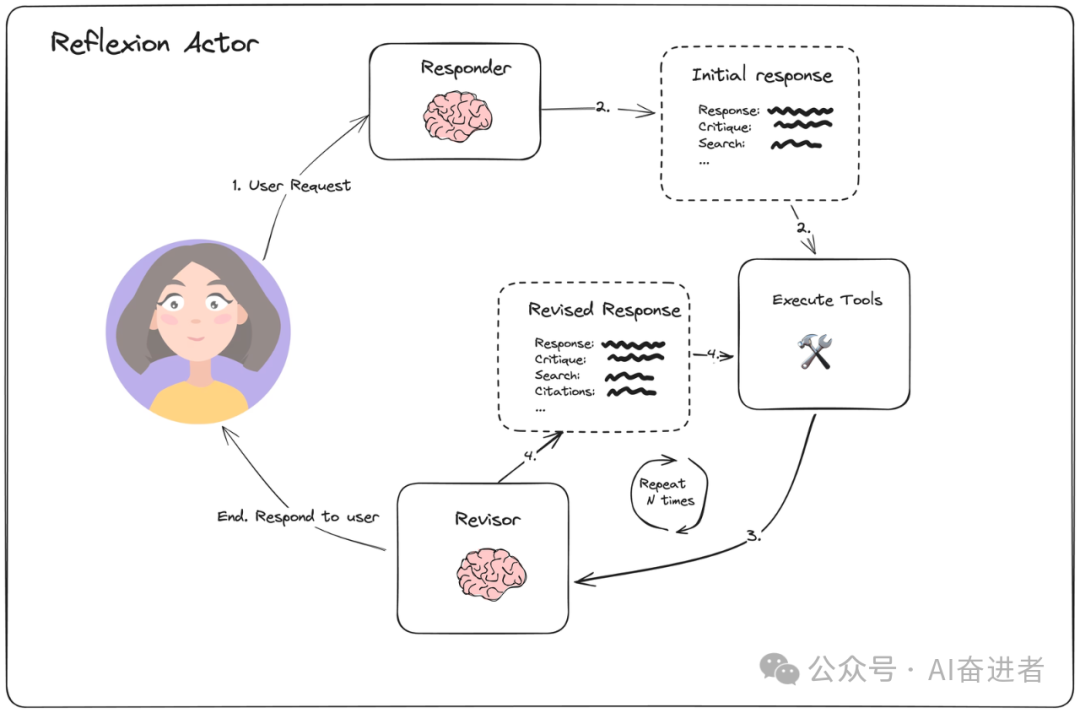
论文中框架主要由三部分构成(上文已介绍过):
-
Actor (agent) with self-reflection
-
External evaluator (task-specific, e.g. code compilation steps)
-
Episodic memory that stores the reflections from (1).
Actor (with reflection)
Actor主要由以下部分构成:
-
Tools/tool execution
-
Initial responder: generate an initial response (and self-reflection)
-
Revisor: re-respond (and reflec) based on previous reflections
A.Construct tools构建工具

B.Initial responder
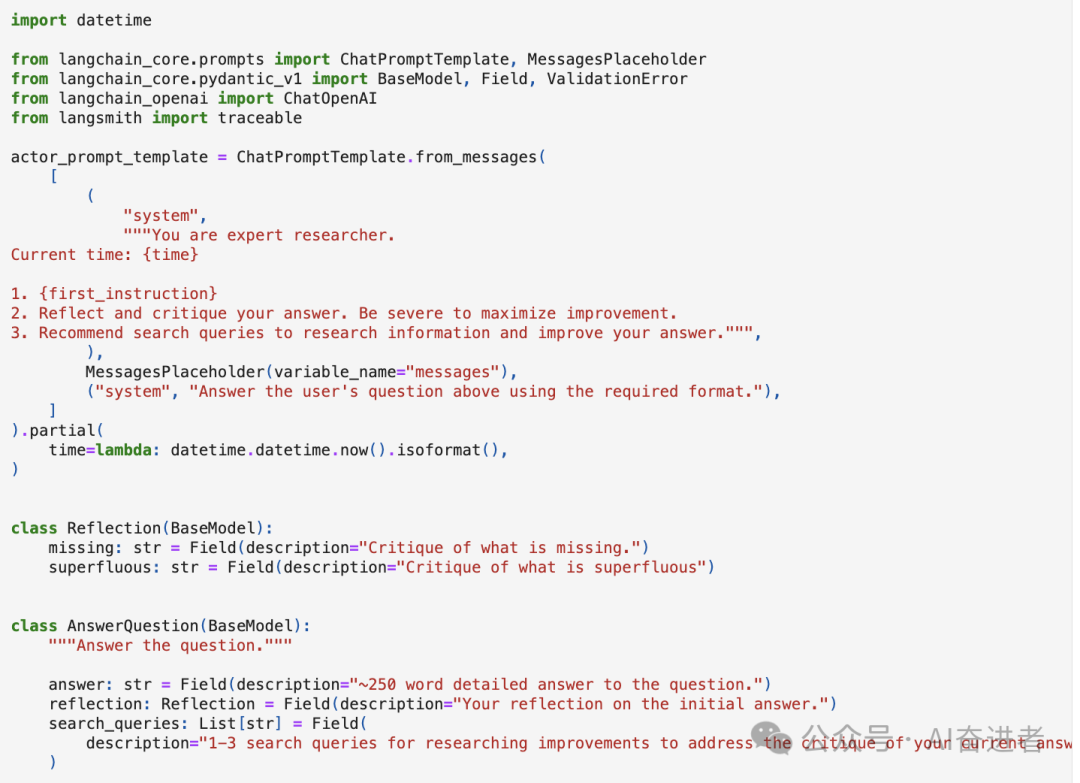
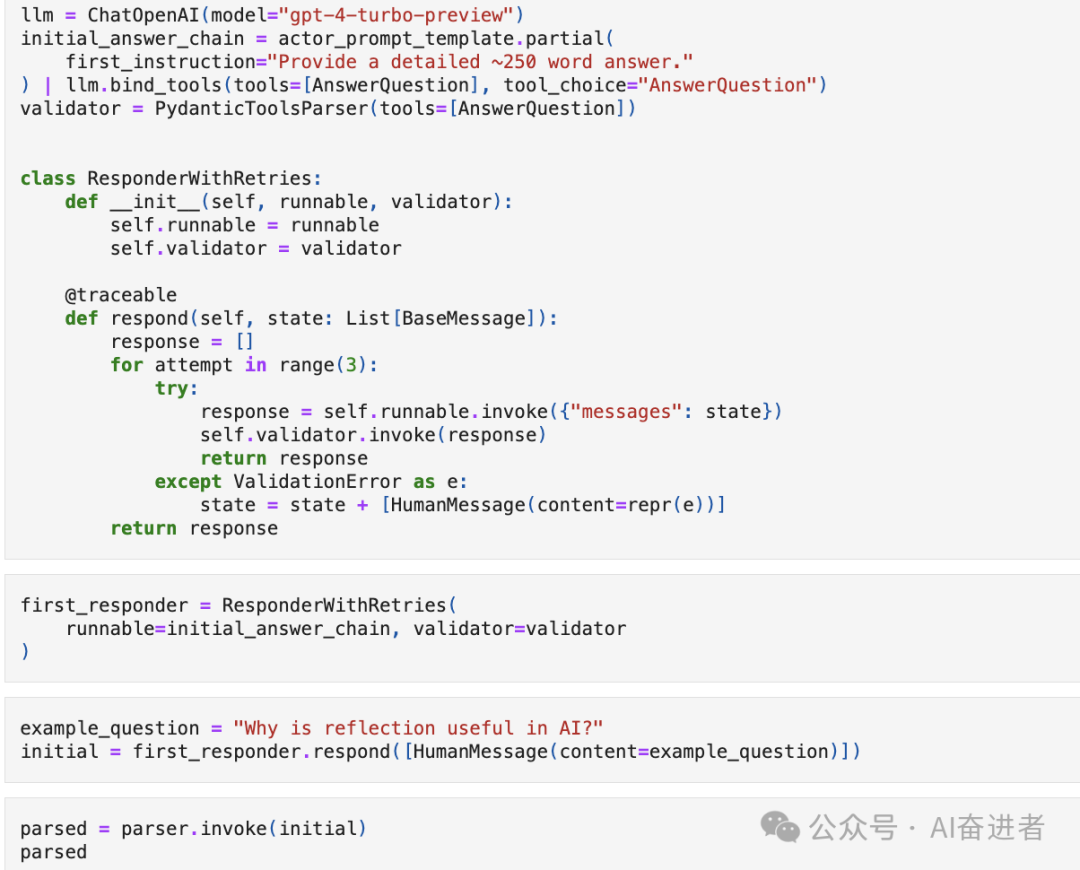
C.Revision
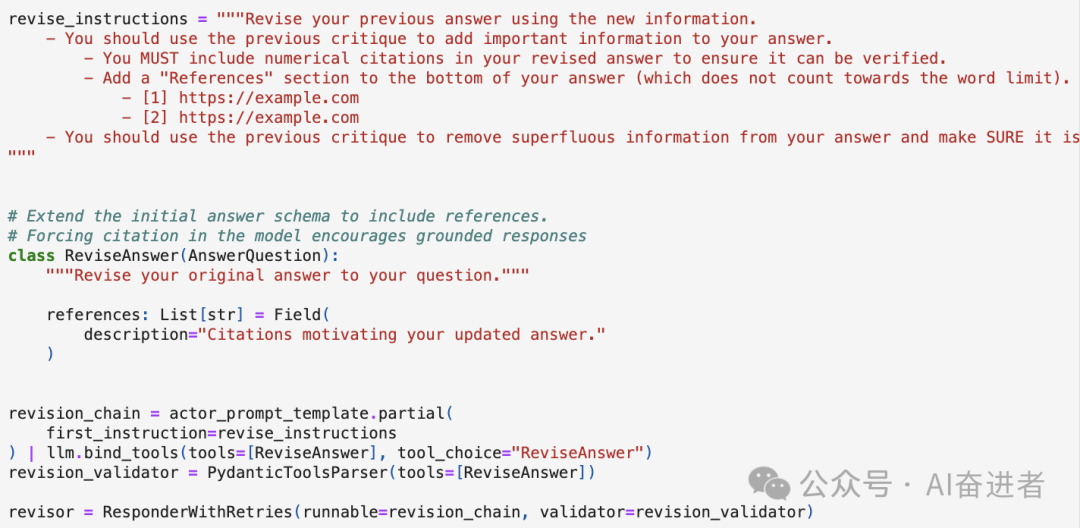
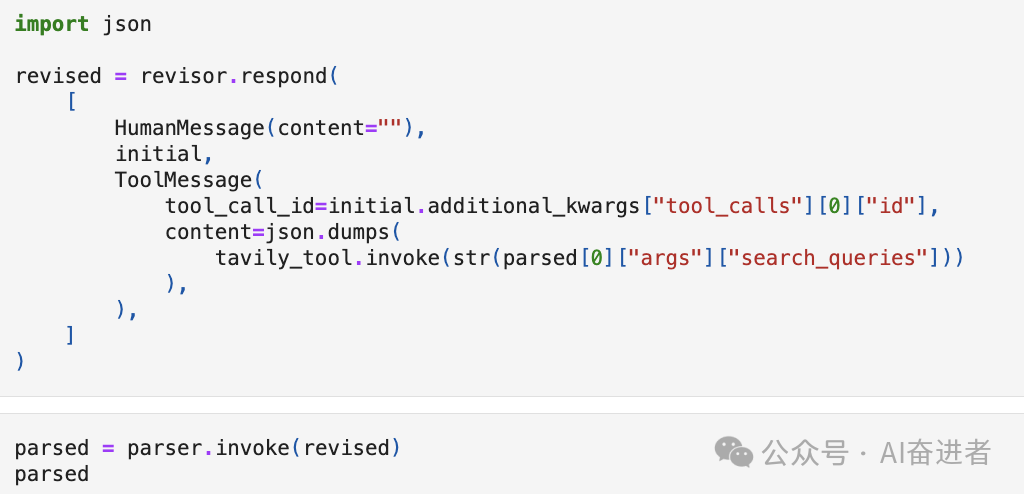
总结与思考
通过反思与长短期记忆可以提升生成内容的质量,但整体步骤可能比较耗时。LangChain中给的例子没有突出说明长短期记忆部分,仅对Actor部分做了展示。
站在未来的角度来看,LLM的能力还需要巨幅的提升。一生二,二生三,三生万物,当前的大模型还远不具备“一”的能力,而现在基于能力不健全的大模型(LLM)所做的设计与尝试,还有很长的路要走。期待我们在这条道路上,能够越走越远~
关于我:AI产品经理(目前在寻找新机会),主要关注AI Agent 应用。公众号:AI奋进者。如有好的想法欢迎一起沟通交流。
Agent系列文章已经逐步更新:
Agent 系列之 ReWOO框架解析 https://blog.csdn.net/letsgogo7/article/details/138259507
https://blog.csdn.net/letsgogo7/article/details/138259507
Agent系列之 Plan-and-Solve Prompting 论文解析https://blog.csdn.net/letsgogo7/article/details/138259154
Agent系列之LangChain中ReAct的实现原理浅析https://blog.csdn.net/letsgogo7/article/details/138197137
Agent系列之ReAct: Reasoning and Acting in LLM 论文解析https://blog.csdn.net/letsgogo7/article/details/138259590Agent 系列之 LLM Compiler框架解析https://blog.csdn.net/letsgogo7/article/details/138284351
Agent 系列之Reflection框架解析https://blog.csdn.net/letsgogo7/article/details/138392568

















 1127
1127

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









