









An LLM Compiler for Parallel Function Calling论文详细介绍了一种名为LLMCompiler的新方法,用于在语言模型中并行执行多个函数调用,以提高效率和准确性。
论文摘要
【论文标题】:《An LLM Compiler for Parallel Function Calling》;
【发布时间】:2023.12.04;
【论文链接】:https://arxiv.org/abs/2312.04511;
【内容摘要】
这篇论文介绍了一种名为LLMCompiler的新方法,用于在语言模型中并行执行多个函数调用,以提高效率和准确性。该方法基于经典编译器的原则,包括规划、任务获取和执行三个组件。通过自动优化执行计划,LLMCompiler可以与开源和私有模型一起使用,并已在各种任务上进行了测试,取得了比现有方法更高的速度、成本节省和准确性的结果。

主要内容
方法描述
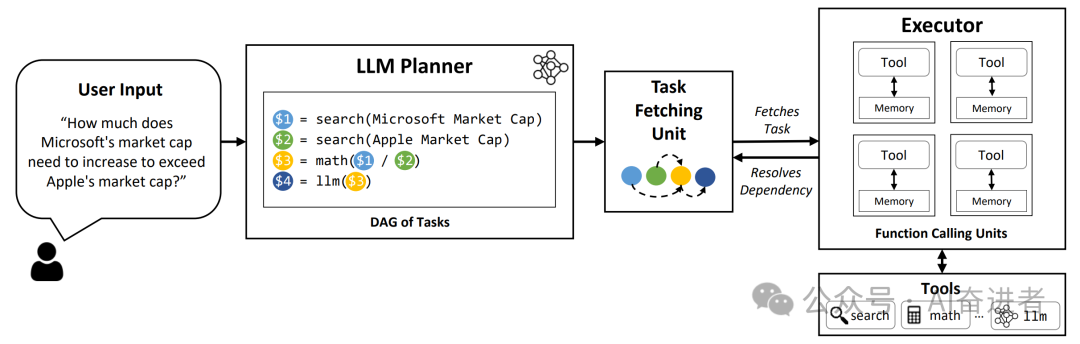
LLMCompiler,旨在通过自动识别任务之间的依赖关系来优化大规模多模态推理问题的执行效率。该方法包括三个组件:一个LLM规划器(LLM Planner),一个任务获取单元(Task Fetching Unit)和一个执行器(Executor)。其中,LLM规划器负责生成一系列任务及其依赖关系,并使用预定义的提示引导其创建依赖并确保正确的语法;任务获取单元根据策略将任务分配给执行器,同时替换变量为前一任务的实际输出;执行器异步地执行任务,并将结果传递给后续任务。
此外,该方法还支持动态重新规划,即在未知中间结果的情况下适应执行流程。当出现复杂的分支结构时,执行器会将中间结果发送回LLM规划器,以便重新计划和分派任务。
解决的问题
LLMCompiler的目标是优化大规模多模态推理问题的执行效率。传统的工具增强型LLMs通常需要手动指定任务之间的依赖关系,这可能会导致计算效率低下。而LLMCompiler则可以自动识别任务之间的依赖关系,并将其转化为执行顺序,从而实现更高效的计算。此外,LLMCompiler还支持动态重新规划,可以在未知中间结果的情况下适应执行流程,进一步提高了计算效率。
LangChain实现
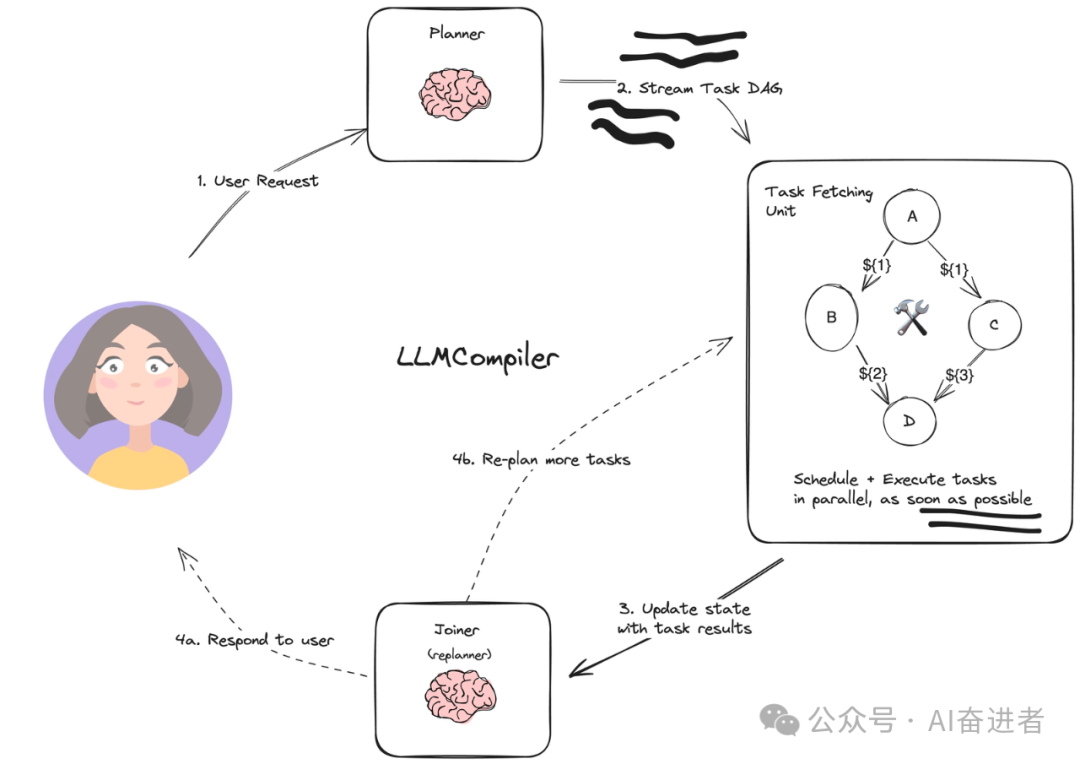
LLMCompiler 有以下主要组件:
Planner:流式传输任务的 DAG。每个任务都包含一个工具、参数和依赖项列表。
Task Fetching Unit:调度并执行任务。一旦满足任务的依赖性,该单元就会安排任务。由于许多工具涉及对搜索引擎或 LLM 的其他调用,因此额外的并行性可以显着提高速度(论文声称提高了 3.6 倍)。
Joiner:由LLM根据整个历史记录(包括任务执行结果)动态重新计划或结束,决定是否响应最终答案或是否将进度传递回(重新)计划代理以继续工作。
代码不贴了,可参考github:https://github.com/langchain-ai/langgraph/blob/main/examples/llm-compiler/LLMCompiler.ipynb?ref=blog.langchain.dev
总结一下,LLM Compiler与AcWOO类似,都通过宏观的计划与执行减少了Prompt内容,但LLM Compiler通过支持任务并发执行实现效率的显著提升。
关于我:AI产品经理(目前在寻找新机会),主要关注AI Agent 应用。公众号:AI奋进者。如有好的想法欢迎一起沟通交流。
Agent系列文章已经逐步更新:
Agent 系列之 ReWOO框架解析 https://blog.csdn.net/letsgogo7/article/details/138259507
https://blog.csdn.net/letsgogo7/article/details/138259507
Agent系列之 Plan-and-Solve Prompting 论文解析https://blog.csdn.net/letsgogo7/article/details/138259154
Agent系列之LangChain中ReAct的实现原理浅析https://blog.csdn.net/letsgogo7/article/details/138197137
Agent系列之ReAct: Reasoning and Acting in LLM 论文解析https://blog.csdn.net/letsgogo7/article/details/138259590Agent 系列之 LLM Compiler框架解析https://blog.csdn.net/letsgogo7/article/details/138284351

















 3258
3258

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









