









Seq2Seq案例
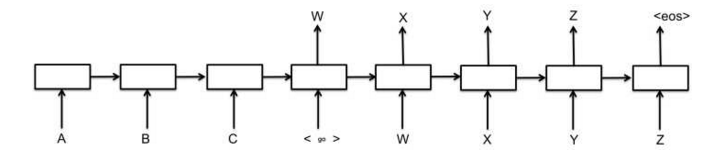
最基础的Seq2Seq模型包含了三个部分,即Encoder、Decoder以及连接两者的中间状态向量,Encoder通过学习输入,将其编码成一个固定大小的状态向量S,继而将S传给Decoder,Decoder再通过对状态向量S的学习来进行输出。
import tensorflow as tf
import data_utils
import os
import math
import sys
import time
class Seq2SeqModel(object):
def __init__(self, learning_rate, learning_rate_decay_factor, source_vocab_size=40000, \
target_vocab_size=40000, num_steps=100, num_epochs=10,
is_training=True):
self.min_loss = float(sys.maxint)
self.batch_size = 100
self.dropout_rate = 0.5
self.max_gradient_norm = 5
self.learning_rate = tf.Variable(float(learning_rate), trainable=False)
self.learning_rate_decay_op = self.learning_rate.assign(self.learning_rate * learning_rate_decay_factor)
self.num_layers = 1
self.emb_dim = 100
self.hidden_dim = 100
self.attention_hidden_dim = 100
self.num_epochs = num_epochs
self.num_steps = num_steps
self.source_vocab_size = source_vocab_size
self.target_vocab_size = target_vocab_size
self.global_step = tf.Variable(0, trainable=False)
# placeholder of encoder_inputs, decoder_inputs, y_outputs
self.encoder_inputs, self.decoder_inputs, self.y_outputs, self.target_weights = self.create_placeholder()
# source and target word embedding
self.source_embedding = tf.Variable(tf.random_uniform([self.source_vocab_size, self.emb_dim], 0.0, 1.0), name="source_emb")
self.target_embedding = tf.Variable(tf.random_uniform([self.target_vocab_size, self.emb_dim], 0.0, 1.0), name="target_emb")
self.softmax_w = tf.Variable(tf.random_uniform([self.hidden_dim * 2, self.target_vocab_size], 0.0, 1.0), name="softmax_w", dtype=tf.float32)
self.softmax_b = tf.Variable(tf.random_uniform([self.target_vocab_size], 0.0, 1.0), name="softmax_b", dtype=tf.float32)
self.attention_W = tf.Variable(tf.random_uniform([self.hidden_dim * 4, self.attention_hidden_dim], 0.0, 1.0), name="attention_W")
self.attention_U = tf.Variable(tf.random_uniform([self.hidden_dim * 2, self.attention_hidden_dim], 0.0, 1.0), name="attention_U")
self.attention_V = tf.Variable(tf.random_uniform([self.attention_hidden_dim, 1], 0.0, 1.0), name="attention_V")
self.encoder_inputs_emb = tf.nn.embedding_lookup(self.source_embedding, self.encoder_inputs)
self.encoder_inputs_emb = tf.transpose(self.encoder_inputs_emb, [1, 0, 2])
# self.encoder_inputs_emb = tf.reshape(self.encoder_inputs_emb, [-1, self.emb_dim])
# self.encoder_inputs_emb = tf.split(0, self.num_steps, self.encoder_inputs_emb)
self.decoder_inputs_emb = tf.nn.embedding_lookup(self.target_embedding, self.decoder_inputs)
self.decoder_inputs_emb = tf.transpose(self.decoder_inputs_emb, [1, 0, 2])
self.decoder_inputs_emb = tf.reshape(self.decoder_inputs_emb, [-1, self.emb_dim])
self.decoder_inputs_emb = tf.split(self.decoder_inputs_emb, self.num_steps, 0)
# lstm cell
self.enc_lstm_cell_fw = tf.contrib.rnn.BasicLSTMCell(self.hidden_dim, state_is_tuple=False)
self.enc_lstm_cell_bw = tf.contrib.rnn.BasicLSTMCell(self.hidden_dim, state_is_tuple=False)
self.dec_lstm_cell = tf.contrib.rnn.BasicLSTMCell(self.hidden_dim * 2, state_is_tuple=False)
# dropout
if is_training:
# self.enc_lstm_cell_fw = tf.nn.rnn_cell.DropoutWrapper(self.enc_lstm_cell_fw, output_keep_prob=(1 - self.dropout_rate))
# self.enc_lstm_cell_bw = tf.nn.rnn_cell.DropoutWrapper(self.enc_lstm_cell_bw, output_keep_prob=(1 - self.dropout_rate))
self.dec_lstm_cell = tf.contrib.rnn.DropoutWrapper(self.dec_lstm_cell, output_keep_prob=(1 - self.dropout_rate))
# get the length of each sample
self.source_length = tf.reduce_sum(tf.sign(self.encoder_inputs), reduction_indices=1)
self.source_length = tf.cast(self.source_length, tf.int32)
self.target_length = tf.reduce_sum(tf.sign(self.decoder_inputs), reduction_indices=1)
self.target_length = tf.cast(self.target_length, tf.int32)
# encode and decode
enc_outputs, enc_state = self.encode(self.enc_lstm_cell_fw, self.enc_lstm_cell_bw)
if is_training:
self.dec_outputs = self.decode(self.dec_lstm_cell, enc_state, enc_outputs)
else:
self.dec_outputs = self.decode(self.dec_lstm_cell, enc_state, enc_outputs, self.loop_function)
# softmax
self.outputs = tf.reshape(tf.concat(self.dec_outputs, axis=1), [-1, self.hidden_dim * 2])
self.logits = tf.add(tf.matmul(self.outputs, self.softmax_w), self.softmax_b)
self.prediction = tf.nn.softmax(self.logits)
self.y_output = tf.reshape(self.y_outputs, [-1])
self.y_output = tf.one_hot(self.y_output, depth=self.target_vocab_size, on_value=1.0, off_value=0.0)
self.target_weight = tf.reshape(self.target_weights, [-1])
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=self.logits, labels=self.y_output)
self.cross_entropy_loss = tf.reduce_mean(tf.multiply(self.target_weight, cross_entropy))
# Gradients and SGD update operation for training the model.
params = tf.trainable_variables()
self.optimizer = tf.train.GradientDescentOptimizer(self.learning_rate)
gradients = tf.gradients(self.cross_entropy_loss, params)
clipped_gradients, _ = tf.clip_by_global_norm(gradients, self.max_gradient_norm)
self.updates = self.optimizer.apply_gradients(zip(clipped_gradients, params), global_step=self.global_step)
self.saver = tf.train.Saver(tf.global_variables())
def create_placeholder(self):
encoder_input_pl = tf.placeholder(tf.int64, [None, self.num_steps])
decoder_input_pl = tf.placeholder(tf.int64, [None, self.num_steps])
y_output_pl = tf.placeholder(tf.int64, [None, self.num_steps])
target_weight = tf.placeholder(tf.float32, [None, self.num_steps])
return encoder_input_pl, decoder_input_pl, y_output_pl, target_weight
def encode(self, cell_fw, cell_bw):
enc_outputs, (output_state_fw, output_state_bw) = tf.nn.bidirectional_dynamic_rnn(
cell_fw,
cell_bw,
self.encoder_inputs_emb,
dtype=tf.float32,
sequence_length=self.source_length,
time_major=True
)
enc_state = tf.concat([output_state_fw, output_state_bw], axis=1)
enc_outputs = tf.concat(enc_outputs, axis=2)
enc_outputs = tf.reshape(enc_outputs, [-1, self.emb_dim * 2])
enc_outputs = tf.split(enc_outputs, self.num_steps, 0)
return enc_outputs, enc_state
def attention(self, prev_state, enc_outputs):
"""
Attention model for Neural Machine Translation
:param prev_state: the decoder hidden state at time i-1
:param enc_outputs: the encoder outputs, a length 'T' list.
"""
#enc_outputs编码器每个时刻输出的状态向量list
e_i = []
c_i = []
for output in enc_outputs:#
atten_hidden = tf.tanh(tf.add(tf.matmul(prev_state, self.attention_W), tf.matmul(output, self.attention_U)))
e_i_j = tf.matmul(atten_hidden, self.attention_V)
e_i.append(e_i_j)#e_i=[[1,1,1],[2,2,2]]
e_i = tf.concat(e_i, axis=1)#e_i=
# e_i = tf.exp(e_i)
alpha_i = tf.nn.softmax(e_i)
alpha_i = tf.split(alpha_i, self.num_steps, 1)
for alpha_i_j, output in zip(alpha_i, enc_outputs):
c_i_j = tf.multiply(alpha_i_j, output)
c_i.append(c_i_j)
c_i = tf.reshape(tf.concat(c_i, axis=1), [-1, self.num_steps, self.hidden_dim * 2])
c_i = tf.reduce_sum(c_i, 1)
return c_i
def decode(self, cell, init_state, enc_outputs, loop_function=None):
outputs = []
prev = None
state = init_state
for i, inp in enumerate(self.decoder_inputs_emb):
if loop_function is not None and prev is not None:
with tf.variable_scope("loop_function", reuse=True):
inp = loop_function(prev, i)
if i > 0:
tf.get_variable_scope().reuse_variables()
c_i = self.attention(state, enc_outputs)
inp = tf.concat([inp, c_i], axis=1)
output, state = cell(inp, state)
# print output.eval()
outputs.append(output)
if loop_function is not None:
prev = output
return outputs
def loop_function(self, prev, _):
"""
:param prev: the output of t-1 time
:param _:
:return: the embedding of t-1 output
"""
prev = tf.add(tf.matmul(prev, self.softmax_w), self.softmax_b)
prev_sympol = tf.arg_max(prev, 1)
emb_prev = tf.nn.embedding_lookup(self.target_embedding, prev_sympol)
return emb_prev
def train(self, sess, save_path, train_set, val_set, steps_per_checkpoint, train_log):
num_iterations = int(math.ceil(1.0 * len(train_set) / self.batch_size))
print("Number of iterations: %d" % num_iterations)
step_time, loss = 0.0, 0.0
current_step = 0
previous_losses = []
while True:
log_file = open(train_log, 'a')
start_time = time.time()
batch_encoder_inputs, batch_decoder_inputs, batch_y_outputs, batch_target_weights = \
data_utils.nextRandomBatch(train_set, batch_size=self.batch_size)
_, step_loss = \
sess.run(
[
self.updates,
self.cross_entropy_loss,
],
feed_dict={
self.encoder_inputs: batch_encoder_inputs,
self.decoder_inputs: batch_decoder_inputs,
self.y_outputs: batch_y_outputs
})
step_time += (time.time() - start_time) / steps_per_checkpoint
loss += step_loss / steps_per_checkpoint
current_step += 1
# Once in a while, we save checkpoint, print statistics, and run evals.
if current_step % steps_per_checkpoint == 0:
perplexity = math.exp(float(loss)) if loss < 300 else float("inf")
log_file.write("global step %d learning rate %.4f step-time %.2f perplexity "
"%.2f" % (self.global_step.eval(), self.learning_rate.eval(),
step_time, perplexity))
log_file.write("\n")
if len(previous_losses) > 2 and loss > max(previous_losses[-3:]):
sess.run(self.learning_rate_decay_op)
previous_losses.append(loss)
checkpoint_path = os.path.join(save_path, "translate.ckpt")
self.saver.save(sess, checkpoint_path, global_step=self.global_step)
step_time, loss = 0.0, 0.0
if current_step % 1000 == 0:
batch_encoder_val, batch_decoder_val, batch_y_val, batch_target_weights_val = \
data_utils.nextRandomBatch(val_set, batch_size=self.batch_size)
loss_val = \
sess.run(
self.cross_entropy_loss,
feed_dict={
self.encoder_inputs: batch_encoder_val,
self.decoder_inputs: batch_decoder_val,
self.y_outputs: batch_y_val,
self.target_weights: batch_target_weights_val
})
eval_ppl = math.exp(float(loss_val)) if loss_val < 300 else float("inf")
log_file.write("global step %d eval: perplexity %.2f" % (self.global_step.eval(), eval_ppl))
log_file.write("\n")
sys.stdout.flush()
log_file.close()
def test(self, sess, token_ids):
# We decode one sentence at a time.
token_ids = data_utils.padding(token_ids)
target_ids = data_utils.padding([data_utils.GO_ID])
y_ids = data_utils.padding([data_utils.EOS_ID])
encoder_inputs, decoder_inputs, _ = data_utils.nextRandomBatch([(token_ids, target_ids, y_ids)], batch_size=1)
prediction = sess.run(self.prediction, feed_dict={
self.encoder_inputs: encoder_inputs,
self.decoder_inputs: decoder_inputs
})
pred_max = tf.arg_max(prediction, 1)
# prediction = tf.split(0, self.num_steps, prediction)
# # This is a greedy decoder - outputs are just argmaxes of output_logits.
# outputs = [int(np.argmax(predict)) for predict in prediction]
# # If there is an EOS symbol in outputs, cut them at that point.
# if data_utils.EOS_ID in outputs:
# outputs = outputs[:outputs.index(data_utils.EOS_ID)]
return pred_max.eval()
















 372
372











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











