









利用seq2seq-attention模型实现
写在前面
在前文介绍了项目的数据集构建:传送门
本文利用seq2seq-attention实现:实现细节请参考论文:《Attention-Based Recurrent Neural Network Models for Joint Intent Detection and Slot Filling》
1.意图识别是利用encoder中的最后一个时间步中的双向隐层 + encoder的attention,最后接一个全连接层进行分类;
2.槽位填充利用序列标注,基于attention的方法,最后接一个全连接层进行分类;
3.模型总体loss = 意图识别loss + 槽位填充loss
一、模型结构图
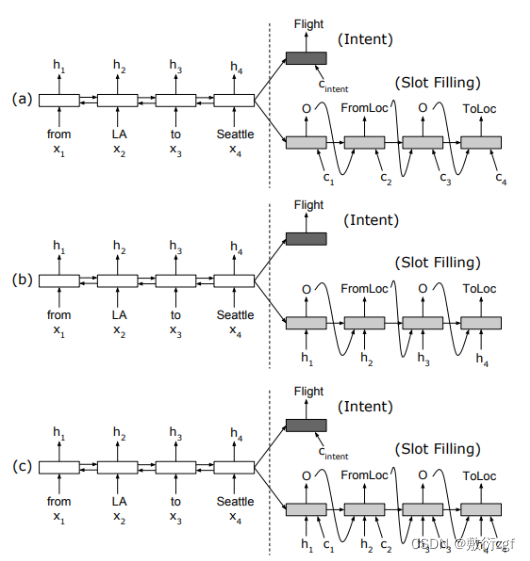
二、数据处理成.pkl文件
# save source words
# source_words_path 保存.pkl的文件路径
source_words_path = os.path.join(os.getcwd(), 'source_words.pkl')
with open(source_words_path, 'wb') as f_source_words:
# 使用pickle模块的dump函数,将SOURCE.vocab对象序列化并保存到已打开的文件f_source_words中。
pickle.dump(SOURCE.vocab, f_source_words)
# save target words
target_words_path = os.path.join(os.getcwd(), 'target_words.pkl')
with open(target_words_path, 'wb') as f_target_words:
pickle.dump(TARGET.vocab, f_target_words)
# save label words
label_words_path = os.path.join(os.getcwd(), 'label_words.pkl')
with open(label_words_path, 'wb') as f_label_words:
pickle.dump(LABEL.vocab, f_label_words)
将数据处理成.pkl文件有以下几个好处:
- 加速数据加载: 将数据保存为.pkl文件可以提高数据加载的速度。一旦数据被处理成.pkl文件,可以直接将文件加载到内存中,避免了每次训练时都需要重新读取和处理原始数据的时间消耗;
- 方便数据共享: 通过将数据保存为.pkl文件,可以方便地与他人或团队共享数据。.pkl文件是一种常见的文件格式,可以在不同的环境和平台上读取和使用;
- 保留数据处理结果: 当对数据进行复杂的预处理和特征工程时,将数据保存为.pkl文件可以保留处理后的结果。这样,在后续的模型训练或预测过程中,可以直接使用已经处理好的数据,无需再次进行繁琐的数据处理操作;
- 节省内存空间: 将数据保存为.pkl文件可以释放内存空间。对于大规模的数据集,保存为.pkl文件可以避免将所有数据同时加载到内存中造成的内存不足问题,只需要在需要使用数据时逐批加载即可。
总之,将数据处理成.pkl文件可以提高数据加载速度、方便数据共享、保留数据处理结果,并且节省内存空间。这对于模型训练和数据处理来说都是非常有益的。
三、构建模型
构建编码器
class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, hidden_dim, n_layers, dropout, pad_index):
super(Encoder, self).__init__()
self.pad_index = pad_index
self.hidden_dim = hidden_dim
self.n_layers = n_layers
self.embedding = nn.Embedding(input_dim, emb_dim, padding_idx=pad_index)
self.gru = nn.GRU(emb_dim, hidden_dim, n_layers, dropout=dropout, bidirectional=True, batch_first=True) #使用双向
self.dropout = nn.Dropout(dropout)
self.fc = nn.Linear(hidden_dim * 2, hidden_dim)
定义Encoder类,该类是一个继承自nn.Module的模型。它实现了一个编码器(Encoder)用于文本序列的特征提取。
构造函数__init__接受以下参数:
- input_dim:输入数据的词汇表大小(即词的个数);
- emb_dim:嵌入层的维度,用于将词索引转换为密集向量表示;
- hidden_dim:GRU(门控循环单元)的隐藏状态维度,也是编码后特征的维度;
- n_layers:GRU的层数;
- dropout:用于防止过拟合的丢失率;
- pad_index:填充索引,用于对输入进行填充;
将传入的参数赋值给类的对应属性。
创建一个Embedding层,用于将输入的词索引转换为密集向量表示;创建一个双向GRU层,接收嵌入向量作为输入,并输出隐藏状态;创建一个Dropout层,用于随机丢弃一部分神经元,以减少过拟合;创建一个全连接层(Linear层),用于将双向GRU层的输出减少维度;这段代码实现了Encoder模型的初始化过程,具体的前向计算在forward方法中实现。
前向传播函数
def forward(self, src, src_len):
# src: 输入序列的索引张量,形状为[batch_size, seq_len]
# src_len: 输入序列的真实长度列表,形状为[batch_size]。由于序列是可变长度的,以填充的元素为0进行对齐,因此需要该参数指示有效长度。
# 初始化
# h0 = torch.zeros(self.n_layers, src.size(1), self.hidden_dim).to(device)
# c0 = torch.zeros(self.n_layers, src.size(1), self.hidden_dim).to(device)
# nn.init.kaiming_normal_(h0)
# nn.init.kaiming_normal_(c0)
# src=[batch_size, seq_len]
# 将输入序列通过嵌入层进行向量化,并应用dropout进行正则化。
embedded = self.dropout(self.embedding(src))
# embedd=[batch_size,seq_len,embdim]
# 使用pack_padded_sequence函数将填充序列打包成压缩表示,以便在GRU层中进行处理
packed = torch.nn.utils.rnn.pack_padded_sequence(embedded, src_len, batch_first=True, enforce_sorted=True) #这里enfore_sotred=True要求数据根据词数排序
# 将打包后的序列输入到GRU层中,获取输出和最终隐藏状态。
output, hidden = self.gru(packed)
# output=[batch_size, seq_len, hidden_size*2]
# hidden=[n_layers*2, batch_size, hidden_size]
# 使用pad_packed_sequence函数将压缩的输出序列解压缩并恢复原始形状,同时进行填充,保证每个序列都具有相同的长度。
output, _ = torch.nn.utils.rnn.pad_packed_sequence(output, batch_first=True, padding_value=self.pad_index, total_length=len(src[0])) #这个会返回output以及压缩后的legnths
'''
hidden[-2,:,:]是gru最后一步的forward
hidden[-1,:,:]是gru最后一步的backward
利用最后前向和后向的hidden的隐状态作为decoder的初始状态
hidden:[batch_size, hidden_dim]
'''
# 通过将最后两个GRU层的隐藏状态拼接起来,使用全连接层进行维度变换,并应用tanh激活函数获得最终的隐藏特征。
hidden = torch.tanh(self.fc(torch.cat((hidden[-2,:,:], hidden[-1,:,:]), dim=1)))
return output, hidden
src: 输入序列的索引张量,形状为[batch_size, seq_len]
src_len: 输入序列的真实长度列表,形状为[batch_size]。由于序列是可变长度的,以填充的元素为0进行对齐。
- 将输入序列通过嵌入层进行向量化,并应用dropout进行正则化;
- 使用pack_padded_sequence函数将填充序列打包成压缩表示,以便在GRU层中进行处理。请注意,此处要求数据按照词数进行排序(enforce_sorted=True);
- 将打包后的序列输入到GRU层中,获取输出和最终隐藏状态;
- 使用pad_packed_sequence函数将压缩的输出序列解压缩并恢复原始形状,同时进行填充,保证每个序列都具有相同的长度;
- 通过将最后两个GRU层的隐藏状态拼接起来,使用全连接层进行维度变换,并应用tanh激活函数获得最终的隐藏特征;
- 返回解压缩的输出序列和最终隐藏特征作为编码器的输出。
构建Attention权重计算方式
class Attention(nn.Module):
def __init__(self, hidden_dim):
super(Attention, self).__init__()
self.attn = nn.Linear((hidden_dim * 2) + hidden_dim, hidden_dim)
self.v = nn.Linear(hidden_dim, 1, bias=False)
def concat_score(self, hidden, encoder_output):
seq_len = encoder_output.shape[1]
hidden = hidden.unsqueeze(1).repeat(1, seq_len, 1) # [batch_size, seq_len, hidden_size]
energy = torch.tanh(self.attn(torch.cat((hidden, encoder_output), dim=2))) # [batch_size, seq_len, hidden_dim]
attention = self.v(energy).squeeze(2) # [batch_size, seq_len]
return attention # [batch_size, seq_len]
def forward(self, hidden, encoder_output):
# hidden = [batch_size, hidden_size]
# #encoder_output=[batch_size, seq_len, hidden_dim*2]
attn_energies = self.concat_score(hidden, encoder_output)
return F.softmax(attn_energies, dim=1).unsqueeze(1) # softmax归一化,[batch_size, 1, seq_len]
实现注意力(Attention)机制,用于对编码器输出的特征进行加权聚合。
hidden_dim:输入特征的维度(编码器输出的隐藏状态维度)
- 调用父类nn.Module的构造函数进行初始化;
- 创建一个线性层(nn.Linear),用于将编码器输出的特征与解码器当前隐藏状态进行拼接,得到注意力权重;
- 创建一个线性层(nn.Linear),用于将注意力权重映射为一个标量,以便进行聚合。
# 计算注意力权重
def concat_score(self, hidden, encoder_output):
seq_len = encoder_output.shape[1]
hidden = hidden.unsqueeze(1).repeat(1, seq_len, 1) # [batch_size, seq_len, hidden_size]
energy = torch.tanh(self.attn(torch.cat((hidden, encoder_output), dim=2))) # [batch_size, seq_len, hidden_dim]
attention = self.v(energy).squeeze(2) # [batch_size, seq_len]
return attention # [batch_size, seq_len]
- 首先将解码器的隐藏状态 hidden 进行扩展,使其与编码器输出 encoder_output 在第二维上具有相同的长度(通过 unsqueeze(1).repeat(1, seq_len, 1));
- 将扩展后的 hidden 和 encoder_output 在第三维上进行拼接,得到 energy 张量;
- 通过一个线性层和tanh激活函数对 energy 进行变换,得到注意力权重;
- 通过另一个线性层对变换后的 energy 进行处理,将其映射为一个标量,并去除多余的维度,得到注意力权重张量 attention。维度为[batch_size, seq_len]
def forward(self, hidden, encoder_output):
# hidden = [batch_size, hidden_size]
# #encoder_output=[batch_size, seq_len, hidden_dim*2]
attn_energies = self.concat_score(hidden, encoder_output)
return F.softmax(attn_energies, dim=1).unsqueeze(1) # softmax归一化,[batch_size, 1, seq_len]
- 调用了concat_score方法,通过输入的隐藏状态和编码器输出计算了注意力权重 attn_energies;
- 使用F.softmax函数对注意力权重进行softmax归一化,将注意力权重所在的维度设为1,并增加一个维度;
- 返回softmax归一化后的注意力权重张量,形状为 [batch_size, 1, seq_len]。
构建解码器
# 构建解码器
class Decoder(nn.Module):
def __init__(self, output_dim, emb_dim, hidden_dim, n_layers, dropout):
super(Decoder, self).__init__()
self.output_dim = output_dim
self.hidden_dim = hidden_dim
self.n_layers = n_layers
self.embedding = nn.Embedding(output_dim, emb_dim)
self.gru = nn.GRU((hidden_dim * 2) + emb_dim + (hidden_dim * 2), hidden_dim, n_layers, dropout=dropout, batch_first=True)
self.attention = Attention(hidden_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, input, hidden, encoder_output, aligned):
input = input.unsqueeze(1)
# input=[batch_size, 1]
# hidden=[batch_size, hidden_size] 初始化为encoder的最后一层 [batch_size, hidden_size]
# encoder_output=[batch_size, seq_len, hidden_dim*2]
# aligned=[batch_size, 1, hidden_dim*2]
# embedded=[batch_sze, 1, emb_dim]
embedded = self.dropout(self.embedding(input))
# 利用利用上一步的hidden与encoder_output,计算attention权重
# attention_weights=[batch_size, 1, seq_len]
attention_weights = self.attention(hidden, encoder_output)
'''
以下是计算上下文:利用attention权重与encoder_output计算attention上下文向量
注意力权重分布用于产生编码器隐藏状态的加权和,加权平均的过程。得到的向量称为上下文向量
'''
context = attention_weights.bmm(encoder_output) # [batch_size, 1, seq_len]*[batch_size,seq_len,hidden_dim*2]=[batch_size, 1, hidden_dim*2]
#拼接注意力上下文和embedding向量,以及encoder输出的hidden对齐向量作为gru输入
# [batch_size, 1, hidden_dim*2+emb_dim+hidden_dim*2]
gru_input = torch.cat([context, embedded, aligned], 2)
# 将注意力向量,本次embedding以及上次的hidden输入到gru中
# decoder_output=[batch_size, seq_len, hidden_size]
# hidden=[n_layers, batch_size, hidden_size]
# decoder中的gru是单向,序列长度为1,层为1,
# 所以decoder_output=[batch_size, 1, hidden_size],hidden=[1, batch_size, hidden_size]
decoder_output, hidden = self.gru(gru_input, hidden.unsqueeze(0))
decoder_output_context = torch.cat([decoder_output, context], 2) # 连接context与decoder_output的hidden_dim =[batch_size, 1, 2 * hidden_dim + hidden_dim]
# prediction=[batch_size, output_dim],词汇表中所有词的概率分布,这里可以使用softmax进行归一化
return decoder_output_context.squeeze(1), hidden.squeeze(0), attention_weights.squeeze(1), context.squeeze(1)
利用Encoder与Decoder构建Seq2Seq模型
class Seq2Seq(nn.Module) :
def __init__(self, predict_flag, encoder, decoder, intent_size, output_dim):
'''
predict_flag:标注当前是训练阶段还是推理阶段
'''
super(Seq2Seq, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.predict_flag = predict_flag
# 意图分类
self.intent_out = nn.Linear((encoder.hidden_dim * 2) + encoder.hidden_dim, intent_size) # 该线性层用于对编码器输出和上下文向量进行分类得到意图分类结果
# 槽填充slot filling
self.slot_out = nn.Linear(encoder.hidden_dim * 2 + encoder.hidden_dim, output_dim) # 该线性层用于对编码器输出和上下文向量进行分类得到槽位分类结果
assert encoder.hidden_dim == decoder.hidden_dim, 'encoder与decoder的隐藏状态维度必须相等!'
assert encoder.n_layers == decoder.n_layers, 'encoder与decoder的层数必须相等!'
1.接收Source句子
2.利用编码器encoder生成上下文向量
3.利用解码器decoder生成预测target句子
4.每次迭代中:
传入input以及先前的hidden与cell状态给解码器decoder
从解码器decoder中接收一个prediction以及下一个hidden与下一个cell状态
保存这个prediction作为预测句子中的一部分
5.是否使用teacher force:
使用 : 解码器的下一次input是真实的token
不使用 : 解码器的下一次input是预测prediction(使用output tensor的argmax) 的token
def forward(self, src, src_lens, trg, teacher_forcing_ration=1.0):
'''
src=[batch_size, seq_len]
src_len=[batch_size]
trg=[batch_size, trg_len]
'''
# 预测,一次输入一句话
if self.predict_flag:
assert len(src) == 1, '预测时一次输入一句话'
src_len = len(src[0])
output_tokens = []
encoder_output, encoder_hidden = self.encoder(src, src_lens)
aligns = encoder_output.transpose(0, 1) # 对齐向量
hidden = encoder_hidden
input = torch.tensor(2).unsqueeze(0) # 预测阶段解码器输入第一个token-> <sos>
for s in range(src_len):
aligned = aligns[s].unsqueeze(1) # [batcg_size, 1, hidden_size*2]
if s == 0:
# context = [batch_size, hidden_dim*2]
decoder_output_context, hidden, _, context = self.decoder(input, hidden, encoder_output, aligned)
else:
decoder_output_context, hidden, _, _ = self.decoder(input, hidden, encoder_output, aligned)
# 槽,[batch_size, output_dim]
output = self.slot_out(decoder_output_context)
input = output.argmax(1)
output_token = input.squeeze().detach().item()
output_tokens.append(output_token)
concated = torch.cat((encoder_hidden, context), 1)
intent_outputs = self.intent_out(concated)
intent_outputs = intent_outputs.squeeze()
intent_outputs = intent_outputs.argmax()
return output_tokens, intent_outputs
# 训练
else:
'''
src=[batch_size, seq_len]
trg=[batch_size, trg_len]
teacher_forcing_ration是使用teacher forcing的概率,例如teacher_forcing_ration=0.8,则输入的时间步有80%的真实值。
'''
batch_size = trg.shape[0]
trg_len = trg.shape[1]
trg_vocab_size = self.decoder.output_dim
# 存储decoder outputs
slot_outputs = torch.zeros(batch_size, trg_len, trg_vocab_size).to(device)
# encoder的最后一层hidden state(前向+后向)作为decoder的初始隐状态,[batch_size, seq_len, hidden_size*2]
# hidden=[batch_size, hidden_size]
encoder_output, encoder_hidden = self.encoder(
src, src_lens)
hidden = encoder_hidden
# 输入到decoder的第一个是<sos>
input = trg[:, 0] # [batch_size]
aligns = encoder_output.transpose(0, 1) # 对齐向量
for t in range(1, trg_len):
'''
解码器输入的初始hidden为encoder的最后一步的hidden
接收输出即predictions和新的hidden状态
'''
aligned = aligns[t].unsqueeze(1) # [batcg_size, 1, hidden_size*2]
if t == 1:
# context = [batch_size, hidden_dim*2]
decoder_output_context, hidden, _, context = self.decoder(input, hidden, encoder_output, aligned)
else:
decoder_output_context, hidden, _, _ = self.decoder(input, hidden, encoder_output, aligned)
# 槽,[batch_size, output_dim]
output = self.slot_out(decoder_output_context)
# 存入decoder的预测值
slot_outputs[:, t, :] = output
# 是否使用teacher forcing
teacher_force = random.random() < teacher_forcing_ration
# 获取预测的最大概率的token
predict_max = output.argmax(1)
'''
如果是teacher forcing则下一步使用真实token作为解码的输入
否则使用decoder的预测值作为下一步的解码输入
'''
input = trg[:, t] if teacher_force else predict_max
# concated = [batch_size, hidden_dim * 2 + hidden_dim]
concated = torch.cat((encoder_hidden, context), 1)
intent_outputs = self.intent_out(concated)
# slot_outputs=[batch_size, trg_len, trg_vocab_size], intetn_outputs=[batch_size, intent_size]
return slot_outputs, intent_outputs
构建模型,优化函数,损失函数,学习率衰减函数
# 构建模型,优化函数,损失函数,学习率衰减函数
def build_model(source, target, label, encoder_embedding_dim, decoder_embedding_dim, hidden_dim, n_layers,
encoder_dropout,
decoder_dropout, lr, gamma, weight_decay):
'''
训练seq2seq model
input与output的维度是字典的大小。
encoder与decoder的embedding与dropout可以不同
网络的层数与hidden/cell状态的size必须相同
'''
input_dim = len(source.vocab) # source 词典大小(即词数量)
output_dim = len(target.vocab) # target 词典大小(即实体类型数量)
label_dim = len(label.vocab) # label 词典大小(即意图类别数量)
encoder = Encoder(input_dim, encoder_embedding_dim, hidden_dim, n_layers, encoder_dropout,
source.vocab.stoi[source.pad_token])
decoder = Decoder(output_dim, decoder_embedding_dim, hidden_dim, n_layers, decoder_dropout)
model = Seq2Seq(False, encoder, decoder, label_dim, output_dim).to(device)
model.apply(init_weights)
# 定义优化函数
# optimizer = optim.Adam(model.parameters(), lr=lr) #, weight_decay=weight_decay)
optimizer = torch.optim.SGD(model.parameters(), lr=lr) # , momentum=0.9, nesterov=True)
# 定义lr衰减
# scheduler = lr_scheduler.ExponentialLR(optimizer, gamma=gamma)
scheduler = lr_scheduler.ReduceLROnPlateau(optimizer=optimizer, mode='min', factor=0.1, patience=2, verbose=False)
# 这里忽略<pad>的损失。
target_pad_index = target.vocab.stoi[source.pad_token]
# 定义损失函数(实体识别)
loss_slot = nn.CrossEntropyLoss(ignore_index=target_pad_index)
# 定义损失函数(意图识别)
loss_intent = nn.CrossEntropyLoss()
return model, optimizer, scheduler, loss_slot, loss_intent
当网络的评价指标不在提升的时候,可以通过降低网络的学习率来提高网络性能:
- optimer指的是网络的优化器
- mode (str) ,可选择‘min’或者‘max’,min表示当监控量停止下降的时候,学习率将减小,max表示当监控量停止上升的时候,学习率将减小。默认值为‘min’
- factor 学习率每次降低多少,new_lr = old_lr * factor
- patience=10,容忍网路的性能不提升的次数,高于这个次数就降低学习率
- verbose(bool) - 如果为True,则为每次更新向stdout输出一条消息。 默认值:False
- threshold(float) - 测量新最佳值的阈值,仅关注重大变化。 默认值:1e-4
- cooldown(int): 冷却时间“,当调整学习率之后,让学习率调整策略冷静一下,让模型再训练一段时间,再重启监测模式。
- min_lr(float or list):学习率下限,可为 float,或者 list,当有多个参数组时,可用 list 进行设置。
- eps(float):学习率衰减的最小值,当学习率变化小于 eps 时,则不调整学习率。
scheduler = lr_scheduler.ReduceLROnPlateau(optimizer=optimizer, mode='min', factor=0.1, patience=2, verbose=False)学习率调度器 用于在训练过程中根据验证集上的表现自动调整学习率。设置学习率衰减因子为传入的 gamma 参数,当验证集上的性能连续 patience 次不改善时降低学习率。
四、训练
# 训练
def train(model, iterator, optimizer, loss_slot, loss_intent, clip):
model.train()
epoch_loss = 0
for i, batch in enumerate(iterator):
src, src_lens = batch.source # src=[batch_size, seq_len],这里batch.src返回src和src的长度,因为在使用torchtext.Field时设置include_lengths=True
trg, _ = batch.target # trg=[batch_size, seq_len]
label = batch.intent # [batch_size]
src = src.to(device)
trg = trg.to(device)
label = label.to(device)
# slot_outputs=[batch_size, trg_len, trg_vocab_size], intetn_outputs=[batch_size, intent_size]
slot_outputs, intent_outputs = model(src, src_lens, trg, teacher_forcing_ration=1.0)
# 以下在计算损失时,忽略了每个tensor的第一个元素及<sos>
output_dim = slot_outputs.shape[-1]
slot_outputs = slot_outputs[:, 1:, :].reshape(-1, output_dim) # output=[batch_size * (seq_len - 1), output_dim]
trg = trg[:, 1:].reshape(-1) # trg=[batch_size * (seq_len - 1)]
loss1 = loss_slot(slot_outputs, trg)
loss2 = loss_intent(intent_outputs, label)
loss = loss1 + loss2
开始训练:
1.得到source与target句子
2.上一批batch的计算梯度归0
3.给模型喂source与target,并得到输出output
4.由于损失函数只适用于带有1维target和2维的input,我们需要用view进行flatten(在计算损失时,从output与target中忽略了第一列)
5.反向传播计算梯度loss.backward()
6.梯度裁剪,防止梯度爆炸
7.更新模型参数
8.损失值求和(返回所有batch的损失的均值)
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), clip)
optimizer.step()
optimizer.zero_grad()
epoch_loss += float(loss.item())
# print('epoch_loss:{}'.format(float(loss.item())))
return epoch_loss / len(iterator)
调用amp.scale_loss(loss, optimizer) 来对损失进行缩放处理。
评估
def evaluate(model, iterator, loss_slot, loss_intent):
model.eval() # 评估模型,切断dropout与batchnorm
epoch_loss = 0
with torch.no_grad(): # 不更新梯度
for i, batch in enumerate(iterator):
src, src_len = batch.source # src=[batch_size, seq_len]
trg, _ = batch.target # trg=[batch_size, seq_len]
label = batch.intent
src = src.to(device)
trg = trg.to(device)
label = label.to(device)
# output=[batch_size, seq_len, output_dim]
slot_outputs, intent_outputs = model(src, src_len, trg,
teacher_forcing_ration=0) # 评估的时候不使用teacher force,使用预测作为每一步的输入
output_dim = slot_outputs.shape[-1]
slot_outputs = slot_outputs[:, 1:, :].reshape(-1,
output_dim) # output=[batch_size * (seq_len - 1), output_dim]
trg = trg[:, 1:].reshape(-1) # trg=[batch_size * (seq_len - 1)]
loss1 = loss_slot(slot_outputs, trg)
loss2 = loss_intent(intent_outputs, label)
loss = loss1 + loss2
epoch_loss += float(loss.item()) # 累计总损失
return epoch_loss / len(iterator) # 返回平均损失,即将总损失除以迭代器的长度
训练模型
def train_model(model, train_iterator, val_iterator, optimizer, scheduler, loss_slot, loss_intent, n_epochs, clip,
model_path, writer):
'''
开始训练我们的模型:
1.每一次epoch,都会检查模型是否达到的最佳的validation loss,如果达到了,就更新
最好的validation loss以及保存模型参数
2.打印每个epoch的loss以及困惑度。
'''
best_valid_loss = float('inf')
for epoch in range(n_epochs):
start_time = time.time()
train_loss = train(model, train_iterator, optimizer, loss_slot, loss_intent, clip)
writer.add_scalar('loss', train_loss, global_step=epoch + 1)
valid_loss = evaluate(model, val_iterator, loss_slot, loss_intent)
end_time = time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), model_path)
scheduler.step(valid_loss)
print('epoch:{},time-mins:{},time-secs:{}'.format(epoch + 1, epoch_mins, epoch_secs))
print('train loss:{},train perplexity:{}'.format(train_loss, math.exp(train_loss)))
print('val loss:{}, val perplexity:{}'.format(valid_loss, math.exp(valid_loss)))
writer.flush()
writer.close()
- 初始化最佳验证损失best_valid_loss为正无穷大;
- 对于每个epoch循环: a. 记录当前时间为start_time。 b. 调用train函数,在训练集上训练模型并返回训练损失。 c. 使用writer.add_scalar()将训练损失写入TensorBoard日志。 d. 调用evaluate函数,在验证集上评估模型并返回验证损失。 e. 记录当前时间作为end_time,计算该epoch的持续时间(epoch_mins和epoch_secs)。 f. 如果验证损失低于之前记录的最佳验证损失best_valid_loss,则更新best_valid_loss为当前验证损失,并保存模型参数到指定路径model_path中。 g. 调用scheduler.step(),传入验证损失,根据验证损失的变化调整优化器的学习率。 h. 打印当前epoch的信息,包括epoch数、时长、训练损失和验证损失;
- 调用writer.flush()将缓存的写操作刷新到TensorBoard日志中;
- 调用writer.close()关闭TensorBoard日志的写操作。
训练参数配置,开始训练
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter(os.getcwd()+'/log', comment='intent_slot')
encoder_embedding_dim = 128
decoder_embedding_dim = 128
hidden_dim = 256
n_layers = 1
encoder_dropout = 0.5
decoder_dropout = 0.5
lr = 0.1
gamma = 0.1
weight_decay = 0.1
n_epochs = 50
clip = 5.0
model_path = os.path.join(os.getcwd(), "model.h5")
model, optimizer, scheduler, loss_slot, loss_intent = build_model(SOURCE,
TARGET,
LABEL,
encoder_embedding_dim,
decoder_embedding_dim,
hidden_dim,
n_layers,
encoder_dropout,
decoder_dropout,
lr,
gamma,
weight_decay)
model, optimizer = amp.initialize(model, optimizer, opt_level='O1')
train_model(model,
train_iter,
val_iter,
optimizer,
scheduler,
loss_slot,
loss_intent,
n_epochs,
clip,
model_path,
writer)
五、运行结果

















 1670
1670











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











