







本文详解paper “A Tutorial on HMMs and Selected Applications in Speech Recognition"并进行matlab实现(尽量用其他编程语言通用的实现)
**为方便阅读代码,注释部分用python的”#"
实现HMM模型用于简单的曲线分类
先定义HMM变量
曲线在T个时刻取值
observation定义为曲线可以取的值,这里先把曲线做归一化,然后从0到1之间以0.1为间隔切为10个区间,依次标号1到10,那么observation就有10个,为1到10的值
train_data定义为训练的曲线集,集中到一个矩阵,每行为一个observation序列,行数为train_data的数量
N为state数,这里设为5
maxIter = 100; #迭代次数
N = 5; #number of states
M = 10; #number of observations
T = size(train_data, 2); #training data列数应一致
初始化HMM参数,可以用均匀分布,也可以用随机数



这里pai和A用均匀分布,B用随机分布
pai = 1/N * ones(N,1);
A = 1/N * ones(N,N); #state transition matrix
B = rand(N,M); #row: states, col: observations
初始化计算过程中的变量alpha, beta, gamma, xi
xi的size本来应该是state * state * T
但注意在计算aij时只用到了xi的1到T-1时刻求和,因此减掉一个维度T,直接定义为1到T-1时刻求和的xi, 变量定义为xi_sumT_1

alpha = zeros([N, T]); #row: states, col: time, for calculating problem 1
beta = zeros([N, T]); #row: states, col: time, for calculating problem 1
gamma = zeros([N, T]); #row: states, col: time, for calculating problem 2
#xi = zeros([N*N, T-1]); #row: state*state, col:time-1, for calculating problem 3
xi_sumT_1 = zeros(N, N); #直接对t时刻求和 row:states, col:states, for calculating problem 3
trainNum = size(train_data, 1);
另外一些辅助变量
iter = 1; #迭代次数计数器
converged = 0; #0:未收敛 1:收敛
previous_loglik = -inf; #记录前一次likelihood
converge_thres = 1e-4; #判断收敛的阈值
HMM设计的3个基本问题:
- 给定一个HMM模型,一个观测信号序列,估计出序列的概率
给出observation序列, 模型lambda=(A,B,pi), 计算P(O | lambda)
即模型与Observation有多匹配 - 决定最好的模型states
给出observation序列,模型lambda=(A,B,pi), 选择state序列Q=q1q2…qT
即探索隐性状态 - 调整模型参数来最好地解释观测到的信号
调整lamba=(A,B,pi)使P(O | lambda)最大
即用observation进行训练
这里要训练的HMM模型是用来识别曲线的,每个曲线类型都要训练一个模型(problem3),而后输入测试曲线,计算在每个模型下的概率(problem1),概率最大的为匹配类型,达到分类效果
每个类型的模型训练都是相同的方法,因此具体写一个类型的train_data
problem3中需要用到的变量为xi
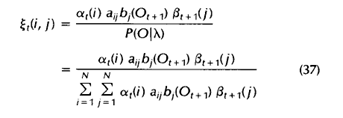
而计算xi需要用到状态转移矩阵A,state下observation概率矩阵b, problem1中的alpha和beta
state下observation概率矩阵b的计算:
根据state下observation概率矩阵B
给定一个训练曲线,这个曲线在1到T时刻有值,取值范围在observation内
那么根据每个时刻t处的observation, 和指定的state,可以在B矩阵中查找到概率,可以知道b的size为state * T, 例如state为j, 时刻t时的值为bj(Ot)
for t=1:T
b(:,t) = B(:, train_data(t));
end
计算alpha:

alpha(:, 1) = pai(:).*b(:,1);
#for j = 1:N #loop j:state
for t = 1:T-1
#alpha(j, t+1) = (A(:,j)'*alpha(:,t)).*B(j,tCurve(t)); #论文中公式
#A的每一行是Sj->S1~SN的概率,转置后每行是S1~SN->Sj的概率
alpha(:, t+1) = A' * alpha(:,t).* b(:,t+1); #简化版
end
#end
loglik = log(sum(alpha(:,T))); #公式中没有log
beta:
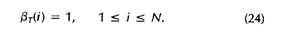
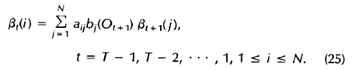
beta = zeros(N, T);
beta(:,T) = ones(N,1); #时刻T的beta初始化为1
for t = T-1:-1:1
#注释部分为论文中公式
#for i = 1:N
#tmp_sum = 0;
#for j = 1:N
#tmp_sum = A(i,j) * (b(j, t+1) .* beta(j, t+1));
#end
#beta(i, t) = tmp_sum;
beta(:, t) = A * (b(:, t+1).*beta(:,t+1));
beta(:,t) = normalise(beta(:,t)); #归一化
#end
end
计算xi
xi的size本来应该是state * state * T
但注意在计算aij时只用到了xi的1到T-1时刻求和,因此减掉一个维度T,直接定义为1到T-1时刻求和的xi, 变量定义为xi_sumT_1
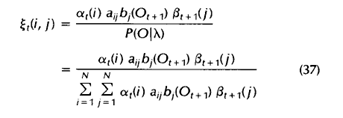
xi_sumT_1 = zeros(N, N);
for t = 1:T-1
pro = 0;
tmp = zeros(N, N);
for i = 1:N
for j = 1:N
tmp(i, j) = alpha(i, t) * A(i,j) * b(j,t+1) * beta(j, t+1);
pro = pro + tmp(i, j);
end
end
xi_sumT_1 = xi_sumT_1 + tmp./pro;
end
简化为矩阵计算
for t = 1:T-1
tmp = beta(:,t+1) .* b(:,t+1);
xi_sumT_1 = xi_sumT_1 + normalise((A .* (alpha(:,t) * tmp')));
end
计算gamma
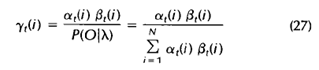
且

for t = 1:T
#归一化满足概率条件
gamma(:,t) = normalise(alpha(:,t) .* beta(:,t));
end
都计算完以后,可以为更新参数做准备,为什么说是做准备,因为如下公式中都是期望值,就是要遍历完一次所有的train_data后求出期望值,然后更新参数供下一次迭代使用
先求期望值,每做完一个train_data(i)求一次
exp_num_pai = exp_num_pai + gamma(:,1); #更新pai(初始状态概率)
gamma_sumT_1 = sum(gamma(:,1:T-1), 2); #按行求和,即1:T-1的gamma求和
exp_num_A = exp_num_A + xi_sumT_1 ./repmat(gamma_sumT_1, [1,5]);
gamma_sumT = sum(gamma, 2); #按行求和,即1:T的gamma求和
#更新B矩阵(state对应的observation的概率矩阵)
for obs=1:M #每个observation
ndx = find(train_data(i)==obs);
if ~isempty(ndx)
exp_num_B(:,obs) = exp_num_B(:,obs) + sum(gamma(:, ndx), 2)./gamma_sumT;
end
end
当遍历完一次所有的train_data后,更新HMM参数,为满足概率和为1的条件,要归一化
pai = normalise(exp_num_pai);
A = mk_stochastic(exp_num_A); #每行归一化
B = mk_stochastic(exp_num_B); #每行归一化
这样细节部分完成了,再完成整体训练流程如下
#Training process..
while(iter <= maxIter && ~converged)
disp(['iteration ', num2str(iter)]);
exp_num_A = zeros(N,N); #用于求A的期望值 M step
exp_num_pai = zeros(N,1); #求gamma(1)的期望值 M step
exp_num_B = zeros(N,M); #用于求bj(k)矩阵的M step
loglik = 0;
for i = 1 : trainNum
#read one curve from train_data..
tCurve = train_data(i, :);
#calculate bj(k) from B
b = calObsLik(tCurve, B);
#calculate alpha..
[alpha, currLik] = calAlpha(alpha, pai, A, b, tCurve);
#calculate beta..
beta = calBeta(beta, A, b, T, N, tCurve);
#calculate xi..
xi_sumT_1 = calXi(xi_sumT_1, alpha, beta, A, b, N, T);
#calculate gamma..
gamma = calGamma(gamma, alpha, beta, N, T);
gamma_sumT_1 = sum(gamma(:,1:T-1), 2); #按行求和,即1:T-1的gamma求和
gamma_sumT = sum(gamma, 2); #按行求和,即1:T的gamma求和
loglik = loglik + currLik;
exp_num_pai = exp_num_pai + gamma(:,1); #更新pai(初始状态概率)
exp_num_A = exp_num_A + xi_sumT_1 ./repmat(gamma_sumT_1, [1,5]);
#更新B矩阵(state对应的observation的概率矩阵)
for o=1:M
ndx = find(tCurve==o);
if ~isempty(ndx)
exp_num_B(:,o) = exp_num_B(:,o) + sum(gamma(:, ndx), 2)./gamma_sumT; %按论文公式
end
end
end
#归一化参数,使满足概率和为1的条件..
pai = normalise(exp_num_pai);
A = mk_stochastic(exp_num_A); #每行归一化
B = mk_stochastic(exp_num_B); #每行归一化
disp(['log likelihood: ', num2str(loglik)]);
#判断是否收敛,收敛则停止迭代
delta_loglik = abs(loglik - previous_loglik);
avg_loglik = (abs(loglik) + abs(previous_loglik))/2;
if (delta_loglik / avg_loglik) < converge_thres
converged = 1;
end
previous_loglik = loglik;
iter = iter + 1; #迭代次数+1
end
最后把每个类别训练好的参数保存,测试时只需要load参数,然后计算
loglik = log(sum(alpha(:,T))); #公式中没有log
看哪个类别的likelihood最大,就分到哪类
















 837
837











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











