







所谓少数人的智慧,实际指是的作者提出的基于专家的协同过滤(CF)在某些方面要优胜于传统的CF算法。这是一个很丰满的工作,其要点如下:
- 专家用户与一般用户在行为模式上的差异;
- 设计基于专家的CF推荐算法;
- 通过两种评测方式,评估专家CF与传统CF在精度上的差异,最后还通过一个用户调查来作出用户体验层面的比较。
- 一个庞大的用户集合的偏好是否可以通过一个比较小的用户集合的偏好预测出来;
- 对于一个源数据集来说,另一个与之不同源的、无直接相关的数据集是否具有对它进行推荐的能力;
- 分析专家的收藏是否可以用作普通用户的推荐;
- 探讨专家CF是否能解决传统CF的一些难题。
数据集:
文章中大部分的分析都是基于两个数据集:1、来自netflix的一个庞大的电影打分集;2、如上所描述的从rottentomatoes.com爬取筛选 的专家用户打分集。专家数据集有169个经过筛选的用户,他们的打分记录都大于等于250个。经过两个数据集中电影的匹配,剩下8000部两个数据集中都 出现过的电影,占原netflix全集电影的50%左右。
专家用户与一般用户在收藏行为上的差异:
这是一个很具有参考价值的分析,虽然作者并没有提供给我们自动挑选专家的方法,但通过这些分析结论,你可以对你自己通过算法或者人工得到的专家数据集的质量进行评估。所有关于专家用户与一般用户差异的结论都可以通过如下几张图得到。
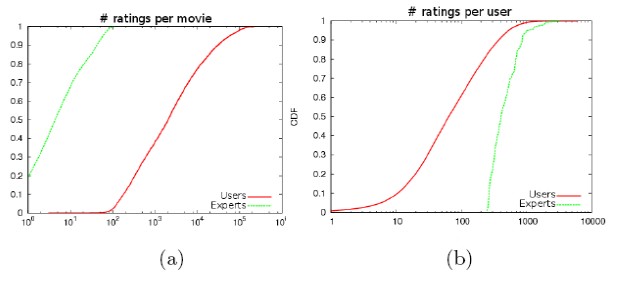
图1:打分数量与数据稀疏性
图的解释:这是一个累积分布图(CDF),对两个数据集各作一条线。图2a中的每一个点(x, y)表示打分人数<=x的电影占电影总数的比例;类似地,图2b中的每一个点(x, y)表示打分记录<=x的用户占用户总数的比例。
结论:专家用户的打分比一般用户要多得多,数据集也要稠密得多,实际上,数据集2的稀疏系数约为0.07(用户评分矩阵中非0元素的比例),而数据集1的稀疏系数约为0.01。图2a中专家曲线在y上的截距为0.2,表示有20%的电影其实只有一个人打过分。
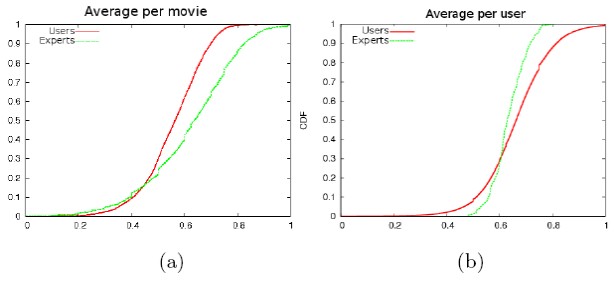
图2:平均评分的分布
结论1:图3a中,专家用户的曲线在高分段占有更多的电影,说明他们对好电影的认同更为一致;
结论2:图3b中,专家用户自己平均评分的变化范围不大,但对电影的覆盖面更广,即无论好片还是烂片,都有一定量的打分记录,而一般用户正好相反。说明专家用户的打分并不依赖于这是否好片,只是一个客观的评价,而一般用户并不倾向于收藏烂片。
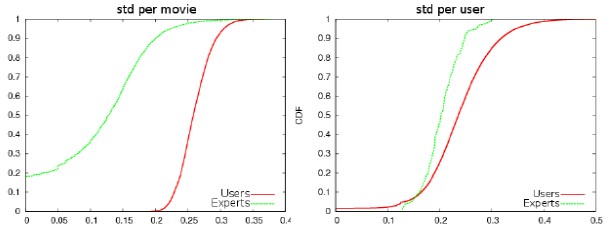
图3:评分的标准差
结论:跟图2a一样的道理,图4a在y有一个0.2的截距。
我觉得存在的一个问题:除非专家们的收藏差异比较大,否则专家对电影意见的更为一致的特性并不会带来一个我们希望的分众性的效果。有时需要人为地引入关于专家收藏的差异性。
专家CF算法:
专 家CF算法跟传统的基于用户的CF算法基本是一致的,只是由原来的计算user-user的距离从而找出相近的user这个思路,改为计算user- expert的距离从而找出相近的expert。相似度的计算公式跟一般的公式稍有点不一样。见原文公式1,主要是把余弦距离乘以一个共同收藏比的因子,以添加 共同收藏数量这个因素的影响。得到相似度之后,会计算与用户相邻的专家,其中会引入两个参数作为阈值以保持推荐的质量(这种质量保证机制也导致了无法针对 某些条目计算预测分值,也就有了下面要说的“覆盖率”这一评价指标),详情可以看原文,这里不过多介绍。得到相似邻居之后对条目的预测评分跟传统的CF也 一样,这里也不多说了。
本文我着重介绍的是两点:专家用户的特征与专家用户好处。最初已经说了特征,下面讲好处。
作者使用了两种评估方法,评估了三种推荐方式的效果
三种推荐方式分别是:
Critics’s Choice:专家平均算法,计算每个专家用户对每个条目评分的平均值,以此作为对所有用户的预测值。
Expert-CF:专家CF,见上文所述。
Neighbor-CF:传统CF,见上文所述。
第一种评估方式是常见的MAE(Mean Absolute Error)
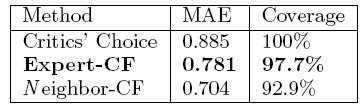
过 程大家应该很熟悉,把数据集分割成训练集与测试集,根据训练集计算的用户相似度,去预测测试集里的评分,得到误差的绝对值的平均,以及预测的覆盖程度(如 上所说,因为有质量保障机制,所以并非所有的user-item对都有预测评分)。结果如下表所示,专家CF比专家平均的MAE有很大的信息增益效果,虽然 比传统CF要差,但覆盖度却也比传统CF要大。
然而对每个用户的误差研究表明,专家CF逊于传统CF时通常集中于那些预测误差并不大的用户,而且差得也不多(0.1左右),可见对于预测准的用户来说,这点差别并不显著。而对于那些预测得并不那么准的用户,两者差别并不大,专家CF还稍稍好一点。
第二种评估方式是Top-N精度
跟 以往的计算Top-N推荐的精确度与召回率的方法不一样,这里把评估变成了一个分类问题,即根据一个设定的阈值delta,把计算出来的预测评分分成 recommendable(大于等于delta)与not-recommendable两个类别;同样把测试集里每个用户评分的条目根据delta分割 成两个类别,然后观察这个真实的类别划分与预测的类别划分之间的交叉情况(true positive与false positive),即可计算得到一个推荐精度的值。
当取delta=4时,专家CF的精度是0.76,传统CF的精度是0.85,两者有一定的差距,当取delta=3时,专家CF的精度是0.89,传统CF的精度是0.90,两者相差不远。即当认为大于等于平均水平(3分)的推荐为有效的话,两个算法的差别不大。
虽 然作为学术评测依据,大家都习惯用各种数字评测指标来说明自己的算法比起别人的有多大的优势,但这些数学上的指标到底跟用户体验有多大的关系实际上是没有 人知道的。为此作者又做了一个更现实的用户实验。这个实验是这样的,作者通过一个网站对招募来的57名用户进行预测与评价。首先要求这批用户对100部电 影按照自己的喜好进行打分,然后系统根据四种策略给每个人产生4组10个的推荐电影。这4种策略分别是:1.随机选取;2.根据专家打分平均从高往低 取;3.传统CF;4.专家CF。并要求用户对这给出的4组推荐分别作出评价,评价的问题是4个:1.对推荐结果的总体感觉;2.有没有你喜欢的推 荐;3.有没有你不喜欢的推荐;4.有没有惊喜。这4个问题的答案需以1-5(第一题)或1-4(其余三题)分值的形式给出。因为实际进行中每个用户在第 一步时评分的电影其实很少,平均每名用户评分14.5(虽然给出100部电影要求打分),这也正好切合了一个新用户面对推荐系统时的情况,也即冷启动。结 果令作者非常满意,几个问题里策略4专家CF都占有压倒性的优势,而策略3传统CF的表现只能跟策略2专家平均差不多,甚至更差。
最后的总结作者吹嘘了一番专家CF相比于传统CF的几大优势:
数据稀疏性:推荐数据集固有的数据稀疏问题会因为信息量不足而带来一些额外的问题,专家收藏的数据稀疏度要比全体用户收藏的稀疏程度要低,即有更多的可参考的信息。
噪声评分:数据集里面难免会存在一些噪声评分,无论用户是有意的还是无意的,甚至还有些故意捣乱的用户或spammer。而专家在这方面则可靠得多,而且个人意见也比较容易保持一致。
冷启动问题:这是专家CF的一大卖点。对于用户冷启动,由于数据稀疏性与噪声问题而造成的问题,在专家CF里得到了不错的解决。实验也证明了这一点。对于条目冷启动,由于专家更具有前瞻性,所以新条目更容易通过专家而进入到推荐池中。
可扩展性:如果直接使用基于用户相似度的CF算法进行推荐,在实际系统中几乎是不可行的,因为构造一个用户相似度矩阵是如此地庞大。而使用量要少得多的专家作为相似度矩阵的一个维度,矩阵的规模则现实得多。
隐私:这里还考虑了这样的一种可能性,即不需要你把数据传递到服务器,只需要把专家喜好传递到客户端,与你本地的收藏相匹配,然后服务器给你返回相应的推荐,避免了服务器记录你的收藏。
我补充一下,其实专家CF的对条目的覆盖面与多样性应该要更好一些,这跟专家收藏数量以及收藏的覆盖面更广这个特性有关。
看 这篇文章,更多的是看文中阐述的思想,虽然这可能并不是他们首创的,但毕竟他们作了一个很好的总结与分析。我一直在思索我们到底需要什么样的推荐,最近我觉得:至少在大部分的场合,我们需要的并不是与自己相似的用户的推荐,而是与自己相似的专家的推荐。无论是看书、看电影、买手机、买笔记本,那批“行内人 物”的观点往往是左右我们决定的主要因素。这个结论在个性化要求相对比较低的中国显得更为真实。















 1149
1149

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









