






概述
微调 LLM 是一个能高效改善模型性能的方法,通过微调能使模型多一些人们期望的行为,少一些不期望的行为。然而微调 LLM 是非常昂贵的,例如微调一个常规 16-bit 65B 的LLaMA需要至少 780GB 的 GPU 显存。
QLoRA 是一个有效的对已量化 4-bit 模型进行微调而模型性能不降低的方法,例如通过 QLoRA 可以在一个 48GB 的 GPU 上对参数量为 65B 的 4-bit 量化模型进行微调,微调后模型的性能不比用16-bit进行微调的性能差。
QLoRA 引入了 3 个新颖的设计,能够在不牺牲性能的前提下降低内存。
4-bit NormalFloat: 对正态分布的数据来说,是信息理论上最优的量化数据类型,优于 4-bit 整型和 4-bit 浮点型
Double Quantization:不仅量化权重,还是量化了量化常数,每个参数大概能节省平均 0.37bits
Paged Optimizers:使用 NVIDIA 统一内存(unified memory)技术去避免处理长序列小批量数据时,梯度检查点的内存尖峰
下图对比了不同微调技术和各自内存的使用情况。QLoRA 对 LoRA 的改进在于 Transformer 类模型采用了 4-bit 精度加载,使用了 paged optimizer 去处理内存尖峰。
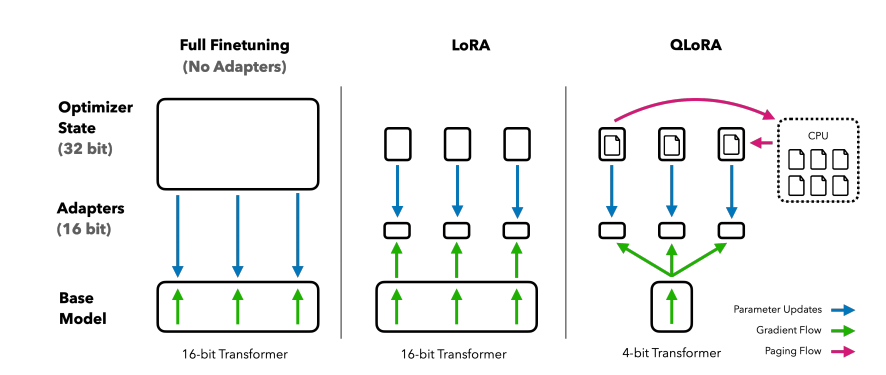
QLoRA基础知识
先介绍几个基础技术,他们是 QLoRA 构建的基石。
Block-wise k-bit 量化
所有的量化 bins 是否被均匀的使用,从某个角度来说,决定了量化精度。例如一个 4-bit 的数据类型有 16 个 bins,但是如果只有 8 个 bins 被使用,它就等价于 3-bit 的数据类型。那么能够增加所有量化 bins 的平均使用率的方法就能增加量化的精度。使用 block-wise/group-wise 的方式把张量切成小块,每个小块独立量化,这能把异常点限制在特定的小块中,这样就能增加其他块量化 bins 的平均使用率从而增加整体的量化精度。
group-wise[4] 量化,是把密集矩按其输出的网元进行切分,切分后的每一块是一个 group,这个 group 的大小是依赖于隐层的维度的。
block-wise 量化是把输入的张量展平成 1 维的,然后进行分块量化。
对 -bit, block-size 为 的 block-wise 量化,假设输入张量 有 个元素,展平后有 个 blocks, 是 block 的索引,取值范围 。 代表整数到浮点数的一个映射。 是第 个 block 的归一化常数, , block-wise 量化可以按下面的公式进行定义,找出和量化映射的最小距离,此时的 就是该数据类型的整型表示。 表示块中的第 个元素。
例如对于一个 32-bit 的浮点数block, 量化成范围是 [-127, 127] 的 Int8, 是一个线性映射,遵循如下量化公式:
其中, 是量化常数(quantization constant)或量化尺度(quantization scale)。反量化是相反的过程:
Low-rank Adapters(LoRA)
LoRA 是一个减小内存需求的微调方法,它冻结整个模型的参数,通过往模型中加入额外的网络层,并只训练这些新增的网络层参数。由于这些新增参数数量较少,使得微调的成本显著下降,还能获得和 16-bit 全模型微调类似的效果。这些新增的网络层叫做适配器(adapter)。假设模型对应 这样的映射, ,对模型进行LoRA进行如下计算:
其中 是一个标量,是 LoRA 的缩放因子(scaling factor)。LoRA 过程的示意图见下图,蓝色部分是 LoRA 微调过程中冻结的模型权重,对应于公式(4)中的 ,橘色部分是 adapter,对应于公式(4)中 .
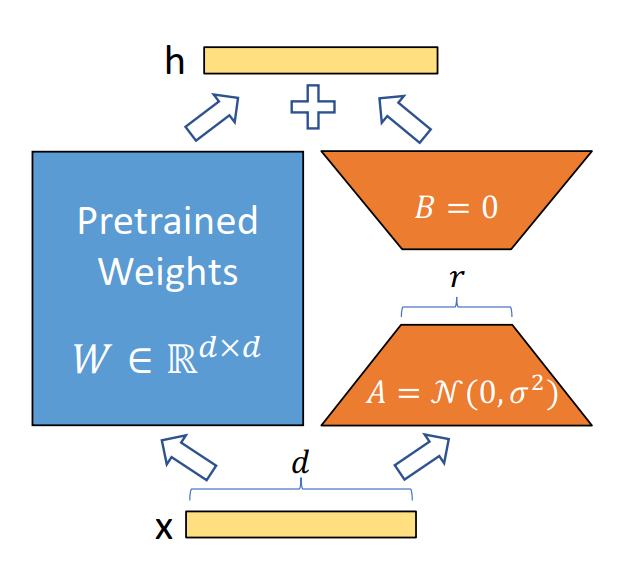
QLoRA微调
QLoRA 能进行高保真的 4-bit 微调,得益于 2 个技术:4-bit NormalFloat(NF4)量化和 Double Quantization。此外,通过 Paged Optimizers,可以防止梯度检查点带来内存尖峰(memory spikes)从而导致 out-of-memory 错误,这种错误常常在大模型单节点微调时出现。
QLoRA 微调时,用到 2 种数据类型:一种是存储数据类型,即 4-bit 已压缩权重;一种是计算数据类型,通常是 BFloat16。这意味着在进行 QLoRA 时,模型权重是 4-bit 存储,并且是冻结的,不进行权重更新,推理时需要把模型权重反量化为 BFloat16,然后进行 16-bit 矩阵乘法计算。adapter 中的权重是真正需要微调的权重,本来就是 16-bit 表示。
4-bit NormalFloat Quantization
NormalFloat(NF) 数据类型构建在分位点量化(Quantile Quantization)[1]的基础上。Quantile Quantization 是一种信息理论上最优的量化数据类型,能够确保每个quantization bin中有相同数量的输入张量。Quantile quantization 是通过经验累积概率分布函数来估计输入张量的分位点。所谓分位点就是对输入张量进行划分的点q,这样的点一共 个。这和 histogram 有 个 bins,每个 bin 里有相同数量的值分布是等效的。每个 bin 的的中点就相当于找 个不重叠的值 , 的累积概率分布函数是 ,分位点之间有着相等的概率质量。这些值可以通过它的反函数,分位点函数获得: 。这样 个分位点之间的中点可以按如下公式计算,输入概率均匀分布,在[0, 1]之间:
通过输入张量 T 的累积概率分布函数来找分位点,分位点之间的样本均匀分布,这样的量化就是 Quantile Quantization。
预训练网络的权重基本都是 0 均值的正态分布,我们可以把所有权重通过方差都转为一个统一的固定分布。对于数据类型的分位点和网络权重,都需要归一化到[-1,1]的范围。那对于数据类型在[-1,1]的范围内,进行 -bit NF 量化,需要进行如下操作:
(1)为了进行 -bit 分位点量化,通过理论上的[0,1]正态分布估计分位点,获取正态分布的 -bit数据类型
(2)将该数据类型归一化到[-1,1]的范围
(3)通过绝对值最大值进行调整,把输入权重归一化到[-1,1]的范围,而后进行量化
通过这个思想获得的4-bit NF的数据类型如下:
[-1.0, -0.6961928009986877, -0.5250730514526367,
-0.39491748809814453, -0.28444138169288635, -0.18477343022823334,
-0.09105003625154495, 0.0, 0.07958029955625534, 0.16093020141124725,
0.24611230194568634, 0.33791524171829224, 0.44070982933044434,
0.5626170039176941, 0.7229568362236023, 1.0]NF量化在实现的时候,结合公式(1)进行 block-wise 量化,需要使用到 lookup table,硬件效率比较低,是一种非均匀量化。
Double Quantization
双重量化(Double Quantization),是针对量化常数的一种量化,能够节省额外的内存。对于 block-wise 的 4-bit 量化,除了权重还需要存储量化常数,这也是可观的开销。例如对于大小为64的块进行量化,量化常数(scale)使用 32-bit 存储,那对于每个参数,平均需要增加 32/64 = 0.5 bit的存储开销。
双重量化是把第一次量化的量化常数 作为第二次量化的输入。第二次量化后产生了量化后的量化常数 和与之对应的第二级量化的量化常数 。第二次量化采用 8-bit Float 量化,块大小是 256。由于 是正数,在量化前,从 减去均值,这样就会变成以0为中心的值,可以采用对称量化的方式。对于块为64的权重进行量化,本来每个参数平均需要 32/64 = 0.5 bits的内存,采用双重量化后,只需要 8/64 + 32/(64*256) = 0.127 bits,每个参数减少了0.373 bits。
Paged Optimizers
NVIDIA的统一内存(unified memory)特性能在 GPU 偶尔 out-of-memory 的时候避免错误的发生,在 CPU 和 GPU 之间自动进行数据的分页传送。这个技术工作起来像 CPU RAM 和硬盘之间进行的常规的内存分页。QLoRA 利用这个技术为优化器的状态分配分页内存,这样当 GPU在运行时 out-of-memory 时,会自动激发 CPU RAM, 当优化器的状态需要更新时,又会自动分页切回 GPU 内存。
QloRA
结合上文描述的 3 种技术,对一个线性层,如果使用一个 LORA adapter, QLoRA的过程可以用下面的公式表示:
其中, 定义如下:
对于 使用NF4,对 使用FP8,对 使用的块大小是64,对 使用的块大小是256。
由此可见, QLoRA 有一个存储数据类型(通常是 4-bit NormalFloat)和一个计算数据类型(16-bit BrainFloat)。我们把存储类型反量化为计算类型后,进行前向反向的数据传播,但是我们只使用 16-bit BrainFloat 计算 LoRA 参数的梯度。
QLoRA 与标准微调对比
在所有的 transformer 层上使用 LoRA 技术对于 LoRA 微调的精度是否能和标准的 16-bit 微调的精度相匹配非常重要,具体见下图。
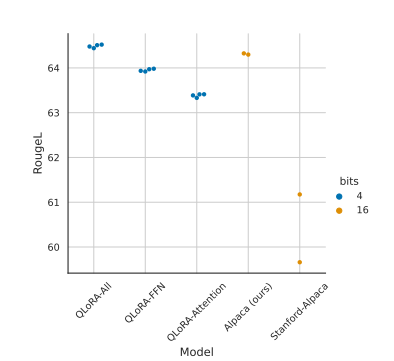
上图中是 LLaMA 7B 模型在 Alpaca 数据集上的测试结果。Stanford-Alpaca 采用 Stranford Alpaca 官方默认的 16-bit 标准微调参数,Alpaca(ours) 是作者对官方微调参数的改进,QLoRA-Attention 是只对 Attention 部分进行 QLoRA 微调,QLoRA-FFN 是只对 FFN 进行 QLoRA,QLoRA 是对所有的线性 transformer 块进行微调。从上图可见,对所有的线性 transformer 块进行微调, 对 LoRA 微调性能是否能匹配 16-bit 标准微调非常重要。在测试中,均使用了 16 个 LoRA adapter,这个超参也很重要。
下图表明, 4-bit NormalFloat 能比 4-bit Float 带来更好的精度。DQ 表示双重量化。
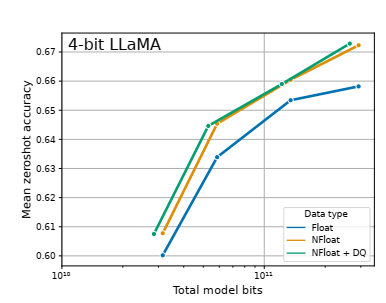
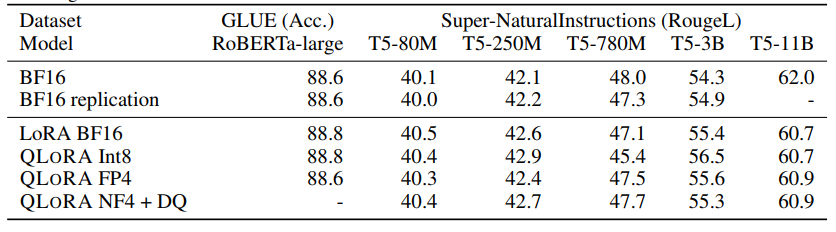
近期研究发现,4-bit 的量化推理是可能的,但是相比 16-bit,会有一定的性能降低,这主要是由于精度降低后,量化误差增大带来的。这样的精度损失可以由量化后对 adapter 的微调来弥补。见下表。表中对比了 RoBERTA 和 T5 模型在 GLUE 和 the Super-NaturalInstructions 数据集下,BF16 的标准微调、LoRA 微调和各种精度下的 QLoRA 微调。从表中可见, 各种精度下对 adapter 的微调,都能够复现标准微调下的精度。
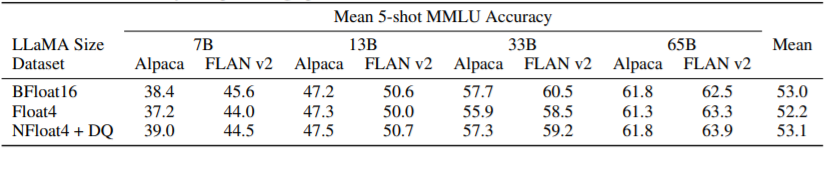
QLoRA 技术不仅适用于上图所示的 11B 规模的模型, 也能扩展到 7B - 65B的规模,见下表。下表使用了2种数据集, Alpaca 和 FLAN v2。精度是 5 次 平均的 MMLU 精度。由表可见 NF4 配合上双重量化(DQ)能够完全媲美 16-bit LoRA 的精度。同时 FP4 的 QLoRA 比 16-bit 的 LoRA 精度平均低 1 个 百分点,这说明了 (1)NF4 + DQ 的 QLoRA 能复制 16-bit 标准微调和 16-bit LoRA 微调的性能 (2)NF4的数据类型就量化精度而言是优于 FP4 的。
总结
QLoRA 是一种有效的微调方式,它主要由 3 种创新的技术组成。采用 QLoRA 能显著的减小微调时对内存的需求,使得一个 65B 参数量的模型能够在一个 48G 的单卡 GPU 上进行微调,同时提供和 16-bit 微调相当的模型性能。QLoRA 降低了微调时对资源的需求,使得对 LLM 的微调更加普遍通用和平民化。
参考资料
参考文献
[1]8-BIT OPTIMIZERS VIA BLOCK-WISE QUANTIZATION8-BIT OPTIMIZERS VIA BLOCK-WISE QUANTIZATION
[2]The case for 4-bit precision: k-bit inference scaling laws
[3]8-bit approximations for parallelism in deep learning
[4]Q-BERT: Hessian Based Ultra Low Precision Quantization of BERT















 2957
2957

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









