







论文名
TVSum: Summarizing Web Videos Using Titles
《基于标题的视频摘要》
会议名称&时间
2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
数据集
研究问题
基于视频标题生成视频摘要
研究方法/相关技术
研究框架:镜头分割-》规范的视觉概念学习-》镜头重要性评分-》摘要生成
摘要生成流程:
视频镜头获取(均匀分割视频段),镜头分帧。人工对每镜头的帧做重要性打分
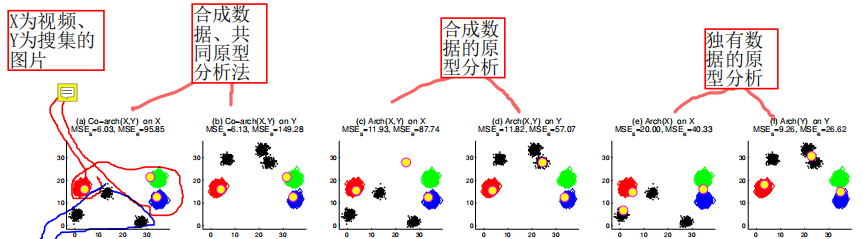
基于视频标题执行搜集相关网络图片,用提出的基于共原分析方法对视频帧重要性打分。
两者得分高的作为选择的原型(比如飞机、西瓜等代表性物体)。基于选取的原型,选择相关镜头。完成视频摘要。
共原分析:视频和图像之间共享的规范模式。
创新点
1、 在镜头长度选取无监督学习方法
2、通过搜集与视频标题相关的图片与原视频帧,通过重要性评估得分选取原型,原型分析获取视频代表性镜头
思考
基于视频标题搜集的图片样本少,会不会存在不能满足共享原型的原型选择标准?
提出的共享原型聚焦在某一物体,忽略了同一场景下其他与之相关的物体,有可能造成语义分割。














 680
680











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









