







参考的文章为:
http://blog.csdn.net/ab198604/article/details/8250461
1)下载hadoop1.2.1源码
2)下载JDK,可以使用如下命令
sudo apt-get install cdt-eclipse
3)创建hadoop管理员帐号
sudo adduser hadoop
4)修改hostname文件
可以使用如下命令 vim /etc/hostname
以下是我对三个结点的ubuntu系统主机分别命名为:master

node1

node2

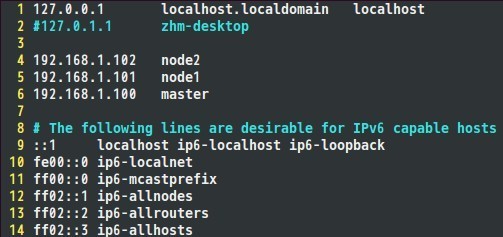
5)修改hosts文件,可以使用如下命令 vim /etc/hosts
6)安装ssh服务
sudo apt-get install ssh openssh-server
7)ssh单机无密码登录
ssh-keygen -t rsa -P “”
cd ~/.ssh
cp id_rsa.pub authorized_keys
ssh localhost
exit
8)让主结点(master)能通过SSH免密码登录两个子结点(slave)
在各个slave节点执行如下命令:
cd ~/.ssh
scp hadoop@master:~/.ssh/id_rsa.pub ./master_rsa.pub
cat master_rsa.pub >> authorized_keys
在master节点执行如下命令:
ssh node1
exit
ssh node2
exit
cd ~/.ssh
scp hadoop@master:~/.ssh/id_rsa.pub ./master_rsa.pub
cat master_rsa.pub >> authorized_keys
ssh master
exit
9)配置hadoop的conf下的hadoop-env.sh,core-site.xml,mapred-site.xml,hdfs-site.xml,masters,slavers
配置conf/hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-6-openjdk-amd64
配置conf/core-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://10.13.33.193:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop-1.2.1/hadoop_tmp</value>
<description>A base for other temporary directories.</description>
</property>
</configuration>
配置conf/mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>10.13.33.193:9001</value>
</property>
</configuration>
配置conf/hdfs-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
配置masters
master
配置slaves
node1
node210)格式话NameNode,命令为 ./hadoop namenode –format
11)启动hadoop,命令为 ./start-all.sh
12)用jps检验hadoop各节点是否启动成功
在主结点master上查看namenode,jobtracker,secondarynamenode进程是否启动。

在node1和node2结点了查看tasktracker和datanode进程是否启动。
先来node1的情况:

下面是node2的情况:

都启动成功了,分布式集群搭建成功了。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









