







三十一、解耦学习
78、GAN-Control: Explicitly Controllable GANs
提出一个训练 GAN 的框架,可以显式控制生成的人脸图像,通过设置确切的属性(例如年龄、姿势、表情等)来控制生成的图像。大多数控制 GAN 生成图像的方法是在标准 GAN 训练后隐式获得的潜在空间以解耦属性来实现部分控制的。这些方法能够改变某些属性的相对强度,但不能明确设置它们的值。还有一些方法利用可变形 3D 人脸模型 (3DMM) 来实现 GAN 中的细粒度控制能力。
与这些方法不同,本文方法不受 3DMM 参数限制,且可以扩展到人脸领域之外。使用对比学习获得具有明确解耦的潜在空间的GAN。在人脸领域,展示了对身份、年龄、姿势、表情、头发颜色和照明的控制。还展示了在绘画肖像和狗图像生成领域的控制能力。证明了方法在定性和定量上都实现了最先进的性能。

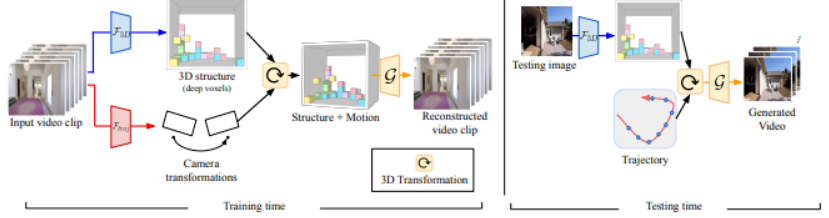
79、Video Autoencoder: self-supervised disentanglement of static 3D structure and motion
提出一种视频自动编码器,以自监督方式从视频中学习 3D 结构和相机姿态的解耦表示。
解耦的表征可以应用于一系列任务,包括新视图合成、相机姿态估计和通过运动跟踪生成视频。在几个大型自然视频数据集上评估方法,并在域外图像上显示泛化结果。
https://zlai0.github.io/VideoAutoencoder/
三十二、可解释性
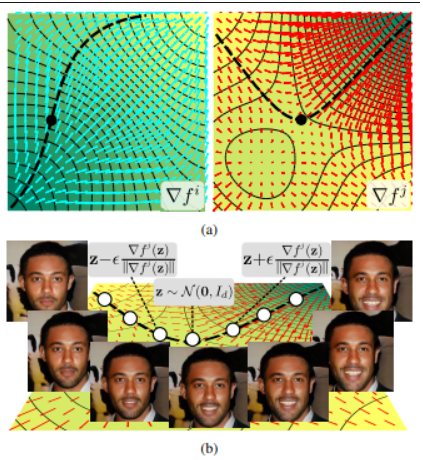
80、WarpedGANSpace: Finding non-linear RBF paths in GAN latent space
这项工作研究的是,以无监督方式在预训练 GAN 的潜在空间中发现可解释路径的问题,从而提供一种直观且简单的方法来控制潜在的生成因素。
代码和预训练模型https://github.com/chi0tzp/WarpedGANSpace
81、Toward a Visual Concept Vocabulary for GAN Latent Space
本文介绍了一种用于构建在 GAN 潜在空间中表示的视觉概念。方法由三个部分组成:(1)基于层选择性自动识别感知显著的方向;(2) 用自然语言描述对这些方向进行人工标记;(3) 将这些标记信息分解为词汇。实验表明,方法学习的概念词汇是可靠且可组合的,并能够对图像风格和内容进行细粒度操作。

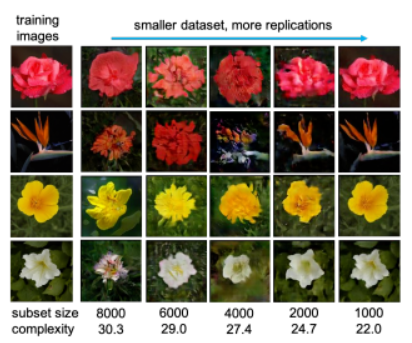
82、When do GANs replicate? On the choice of dataset size
GAN 的生成,有没有可能是直接去复制训练图像?
尽管已经在理论上或经验上确定了许多因素,但数据集大小和复杂性对 GAN 是否发生复制的影响仍然未知。借助 BigGAN 和 StyleGAN2 ,在数据集 CelebA、Flower 和 LSUN-bedroom 上,本文表明数据集大小及其复杂性在 GAN 复制和生成图像的感知质量中起着重要作用。
83、Explaining in Style: Training a GAN to explain a classifier in StyleSpace
图像分类模型可能取决于图像里多种不同的语义属性。对分类器决策的解释方面,需要发现和可视化这些属性。本文提出的StylEx,通过训练生成模型来具体解释构成分类器决策的多个属性。
关于StyleGAN 的 StyleSpace,众所周知,它可以在图像中生成具有语义意义的维度。然而,由于标准 GAN 训练不依赖于分类器,它可能无法表示那些对分类器决策很重要的属性,而 StyleSpace 的维度可能表示不相关的属性。为此提出了一个包含分类器模型的 StyleGAN 训练程序,以学习特定于分类器的 StyleSpace。然后从该空间中选择解释性属性。
将 StylEx 应用于多个领域,包括动物、树叶、面部和视网膜图像,展示了如何以不同的方式修改图像以更改其分类器输出。实验表明,该方法可以找到与语义匹配的属性。

猜您喜欢:

附下载 |《TensorFlow 2.0 深度学习算法实战》


















 1256
1256

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









