







 文章介绍了近期图像处理领域的进展,包括基于MAT的精确图像转换、LANIT的无监督语言驱动图像转换、交互式卡通化控制、LightPainter的人像重打光系统、从抽象草图生成逼真图像的方法以及少样本语义图像合成的类亲和力转移技术。这些研究展示了在图像生成和编辑方面的创新和进步。
文章介绍了近期图像处理领域的进展,包括基于MAT的精确图像转换、LANIT的无监督语言驱动图像转换、交互式卡通化控制、LightPainter的人像重打光系统、从抽象草图生成逼真图像的方法以及少样本语义图像合成的类亲和力转移技术。这些研究展示了在图像生成和编辑方面的创新和进步。
1、Masked and Adaptive Transformer for Exemplar Based Image Translation
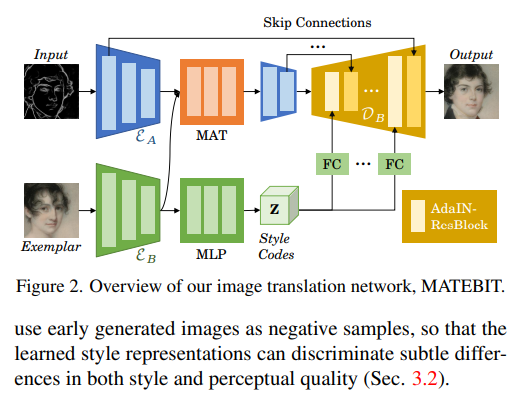
提出了一个基于样本的图像转换新方法。最近用于此任务的先进方法主要集中在建立跨域语义对应上,它以局部风格控制的方式顺序控制图像生成。但跨域语义匹配具有挑战性,匹配错误最终会降低生成图像的质量。
为了克服这一挑战,一方面提高了匹配的准确性,另一方面削弱了匹配在图像生成中的作用。为了实现前者,提出了一种掩码和自适应变换器 (MAT),用于学习准确的跨域对应关系,并执行上下文感知特征增强。为了实现后者,使用样本的输入源特征和全局样式代码作为补充信息来解码图像。
此外,设计了一种新的对比风格学习方法,用于获取质量区分风格表示,这反过来有利于高质量图像的生成。实验结果表明在各种图像转换任务中表现更好。代码可在 https://github.com/AiArt-HDU/MATEBIT
2、LANIT: Language-Driven Image-to-Image Translation for Unlabeled Data
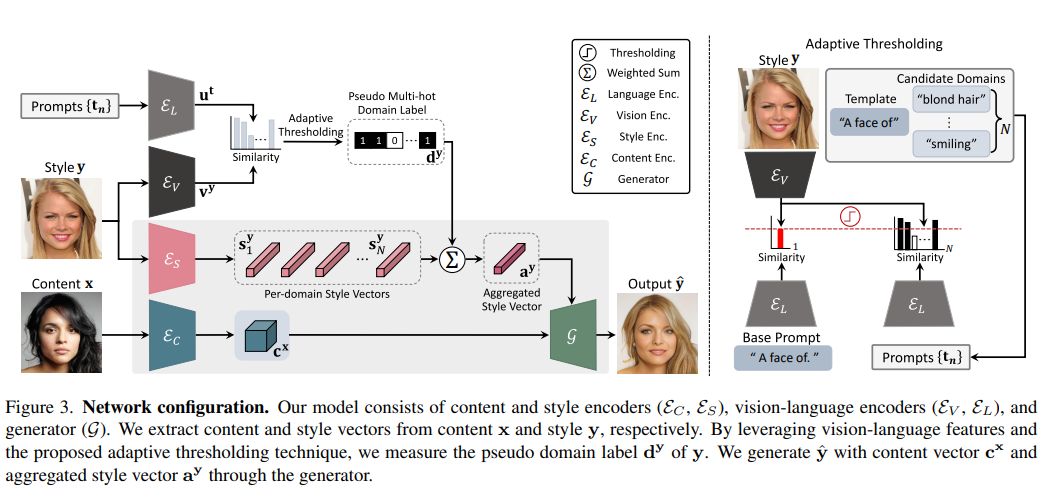
现有的图像转换技术通常存在两个关键问题:严重依赖每个样本域标注,或无法处理每个图像的多个属性。最近的真正无监督方法采用聚类方法来提供每个样本的域标签。然而,它们无法解释现实世界的设置:一个样本可能具有多个属性。此外,集群的语义不容易与人类理解相结合。
为了克服这些问题,提出了语言驱动的图像转换模型,称为 LANIT。利用数据集文本中给出的易于获取的候选属性:图像和属性之间的相似性表示每个样本域标签。用户可以使用语言中的一组属性指定目标域。为了解决初始提示文本不准确的情况,还提供提示学习。
进一步提出域正则化损失,强制将转换后的图像映射到相应的域。几个标准基准的实验表明,LANIT 实现了与现有模型相当或更优的性能。
3、Interactive Cartoonization with Controllable Perceptual Factors
图像卡通化,即将自然照片渲染成卡通风格。以前的卡通化方法只关注端到端的转换,这可能会阻碍可编辑性。相反,本文提出了一种基于卡通创作过程的纹理和颜色编辑特征的新解决方案。
设计了一个模型架构,具有独立的解码器、纹理和颜色,以解耦这些属性。在纹理解码器中,提出了一个纹理控制器,它使用户能够控制笔触样式和抽象以生成不同的卡通纹理。还引入了 HSV 颜色增强来诱导网络生成多样且可控的颜色转换。作者声称,该工作是第一个在推理时控制卡通化的深度学习方法,同时比基线有明显的质量改进。

4、LightPainter: Interactive Portrait Relighting with Freehand Scribble
给定所需的照明表示(例如环境贴图),最近的人像重新打光/照明(portrait relighting)方法已经实现了人像照明效果的逼真效果。然而,这些方法对于用户交互来说并不直观,并且缺乏精确的照明控制。
本文推出了 LightPainter,一种基于涂鸦的重打光系统,允许用户轻松地以交互方式操纵人像照明效果。通过两个条件神经网络实现的,一个模块根据肤色恢复几何形状和反照率,以及一个用于重新照明的基于涂鸦的模块。为了训练重新照明模块,提出了一种新的涂鸦模拟程序来模拟真实用户的涂鸦,可以在没有任何人工注释的情况下进行训练。
通过定量和定性实验展示了高质量和灵活的肖像照明编辑能力。用户研究与商业照明编辑工具的比较也证明了用户对方法的一致偏好。

5、Picture that Sketch: Photorealistic Image Generation from Abstract Sketches
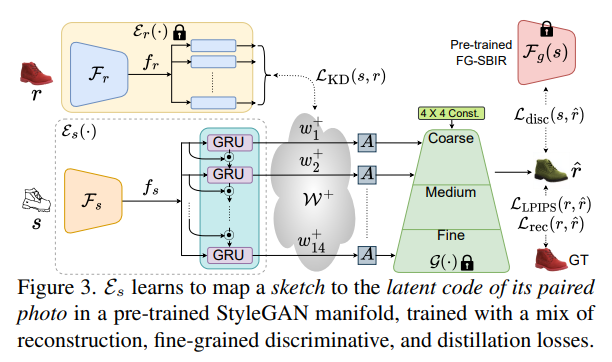
给定一个抽象的、变形的、普通的草图,这些草图来自像你我这样未经训练的业余爱好者,本文将它变成了一个逼真的图像。
与现有技术有很大的不同,因为一开始并不规定类似边缘图的草图,而是旨在使用抽象的徒手人体草图。首先,提出一个解耦的编码器-解码器训练范例,其中解码器是仅在照片上训练的 StyleGAN。这可确保生成的结果始终逼真。
剩下的就是如何最好地处理素描和照片之间的抽象差距。为此,提出了一个在草图-照片对上训练的自回归草图映射器,将草图映射到 StyleGAN 潜在空间。进一步介绍了具体的设计来解决人体草图的抽象性质,包括在经过训练的草图照片检索模型背后的细粒度判别损失,以及部分感知的草图增强策略。
最后,展示了我们的生成模型支持的一些下游任务,其中展示了如何将基于细粒度草图的图像检索简化为图像(生成)到图像检索任务。
项目页面:https://subhadeepkoley.github.io/PictureThatSketch
6、Few-shot Semantic Image Synthesis with Class Affinity Transfer
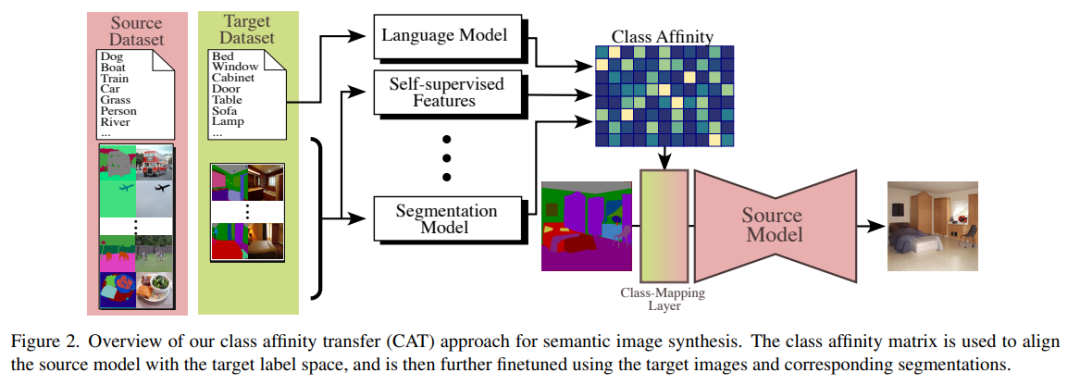
语义图像合成,旨在在给定语义分割图的情况下生成照片般逼真的图像。尽管最近取得了很大进展,但训练它们仍然需要大量图像数据集,这些图像数据集用像素标签图进行标注,获取起来非常繁琐。
为了减轻标注成本,提出了一种迁移方法,该方法利用在大型源数据集上训练的模型,通过估计源类和目标类之间的成对关系来提高小型目标数据集的学习能力。类亲和矩阵( class affinity matrix )作为源模型的第一层引入,使其与目标标签映射兼容,然后针对目标域进一步微调源模型。为了估计类亲和力,考虑利用先验知识的不同方法:源域语义分割、文本标签嵌入和自监督视觉特征。
将方法应用于基于 GAN 和基于扩散的语义合成架构。实验表明,可以有效地组合估计类亲和力的不同方法,并且改进了生成图像模型的现有最先进的转换方法。
猜您喜欢:
深入浅出stable diffusion:AI作画技术背后的潜在扩散模型论文解读
深入浅出ControlNet,一种可控生成的AIGC绘画生成算法!

最新最全100篇汇总!生成扩散模型Diffusion Models
附下载 |《TensorFlow 2.0 深度学习算法实战》
《礼记·学记》有云:独学而无友,则孤陋而寡闻

点击 一顿午饭外卖,成为CV视觉的前沿弄潮儿!,领取优惠券,加入 AI生成创作与计算机视觉 知识星球!

















 3764
3764

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









