









Visual Prompt Tuning
Basic information
- Title: Visual Prompt Tuning
- Paper: arXiv
- Code: official code , unofficial code
- Slides: unofficial colalab , unofficial github
- Video: (unofficial) Bilibili 1, (unofficial) Bilibili 2
- Author: Menglin Jia, Luming Tang, Bor-Chun Chen, Claire Cardie, Serge Belongie, Bharath Hariharan, Ser-Nam Lim
- Time:ECCV 2022
The content
-
Background
- 目前调整预训练模型的方法是full fine-tuning,即完全微调。预训练好的模型利用full fine-tuning的方式迁移到下游任务上时,需要存储整个模型,而且在会对模型的所有参数都进行训练,造成计算量大的问题;
- 随着计算机视觉领域的发展,基于Transformer的模型相较于基于CNN的模型更大,导致模型参数急剧上升,也致使训练难度的增大;
- 近年来,NLP已经进入大模型阶段,对于如何迁移NLP预训练好的大模型到下游任务,相关人员提出了不同于Fine-tuning的方法,即Prompt-tuning,在保持预训练模型冻结的情况下,只需要训练少量额外的参数即可将该大模型迁移到下游任务,而且效果不错。
-
Motivation
如何更加有效地 adapt 预训练的Transformer 用于下游任务?
what is the best way to adapt large pre-trained Transformers to downstream tasks in terms of effectiveness and efficiency? -
Contribution
- 这篇文章的提出了一个简单、有效的方法调整预训练好的Transformer模型用于下游任务,即Visual-Prompt Tuning (VPT)。
- 对于本文所提出的VPT在多个下游任务上进行了实验,甚至在20个下游任务上都可以超过Fine-tuning的效果

-
Method
-
方法示意图
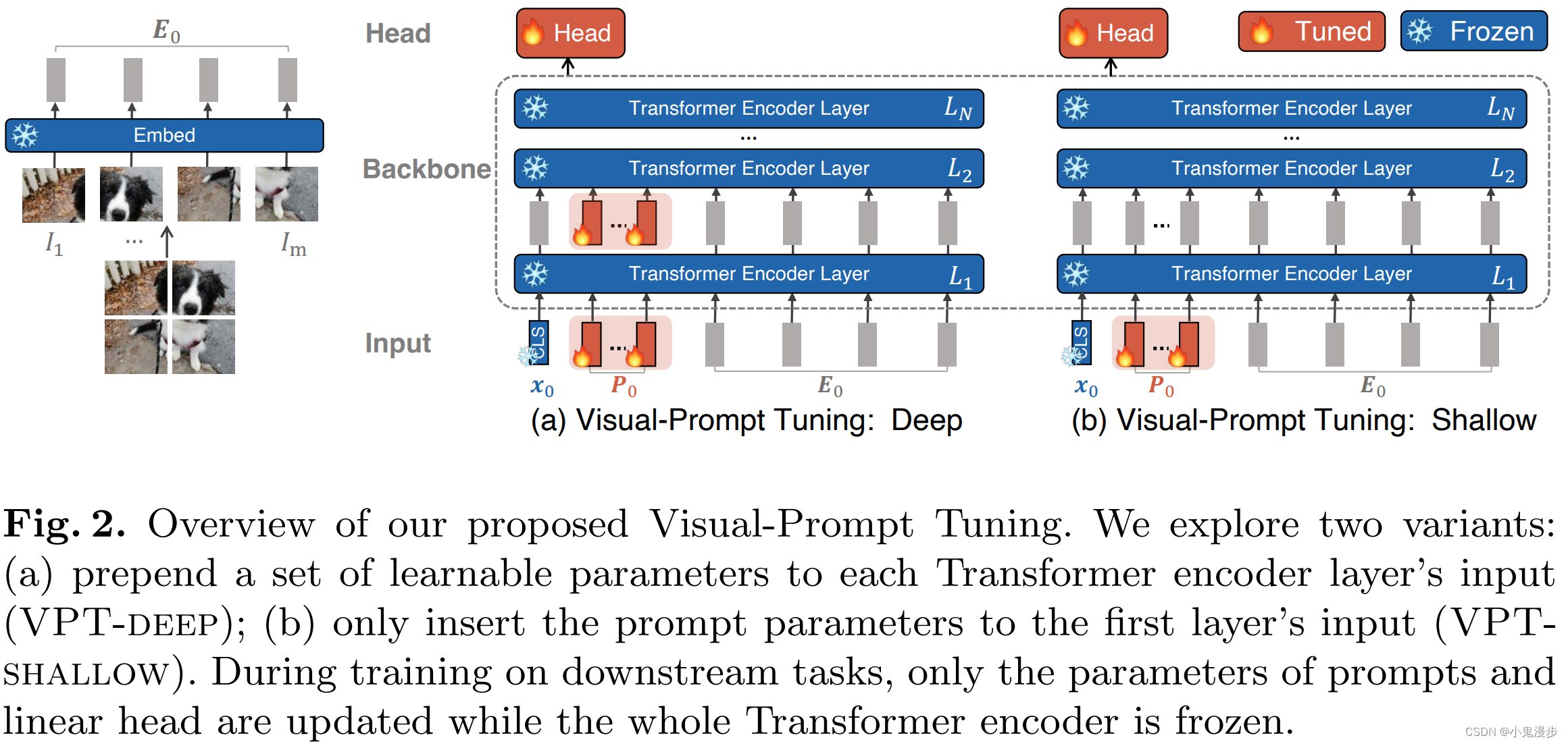
-
方法基础

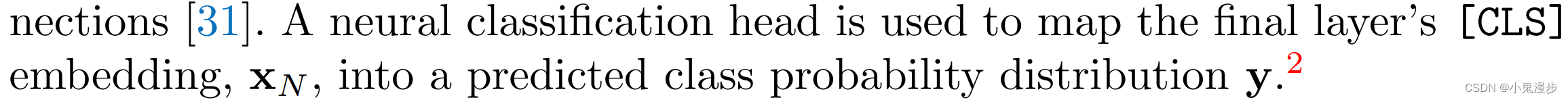
-
Visual-Prompt Tuning (VPT)

-
Storing Visual Prompts
VPT is beneficial in presence of multiple downstream tasks. We only need to store the learned prompts and classification head for each task and re-use the original copy of the pre-trained Transformer model, significantly reducing the storage cost. For instance, given a ViT-Base with 86 million (M) parameters and d = 768 d = 768 d=768, 50 shallow prompts and deep prompts yield additional p × d = 50 × 768 = 0.038 p × d = 50 × 768 = 0.038 p×d=50×768=0.038M, and N × p × d = 0.46 N × p × d = 0.46 N×p×d=0.46M parameters, amounting to only 0.04% and 0.53% of all ViT-Base parameters, respectively.
-
-
Experiment result
-
实验设置特别关注部分:
- Pre-trained Backbones.: All backbones in this section are pre-trained on ImageNet-21k.
- Baselines:
- Full: fully update all backbone and classification head parameters.
- Linear: only use a linear layer as the classification head.
- Partial- k k k: fine-tune the last k layers of backbone while freezing the others.
- Mlp- k k k: utilize a multilayer perceptron (MLP) with k layers, instead of a linear layer, as classification head.
- Sidetune : train a “side” network and linear interpolate between pretrained features and side-tuned features before being fed into the head.
- Bias: : fine-tune only the bias terms of a pre-trained backbone.
- Adapter: insert new MLP modules with residual connection inside Transformer layers.
-
实验结果
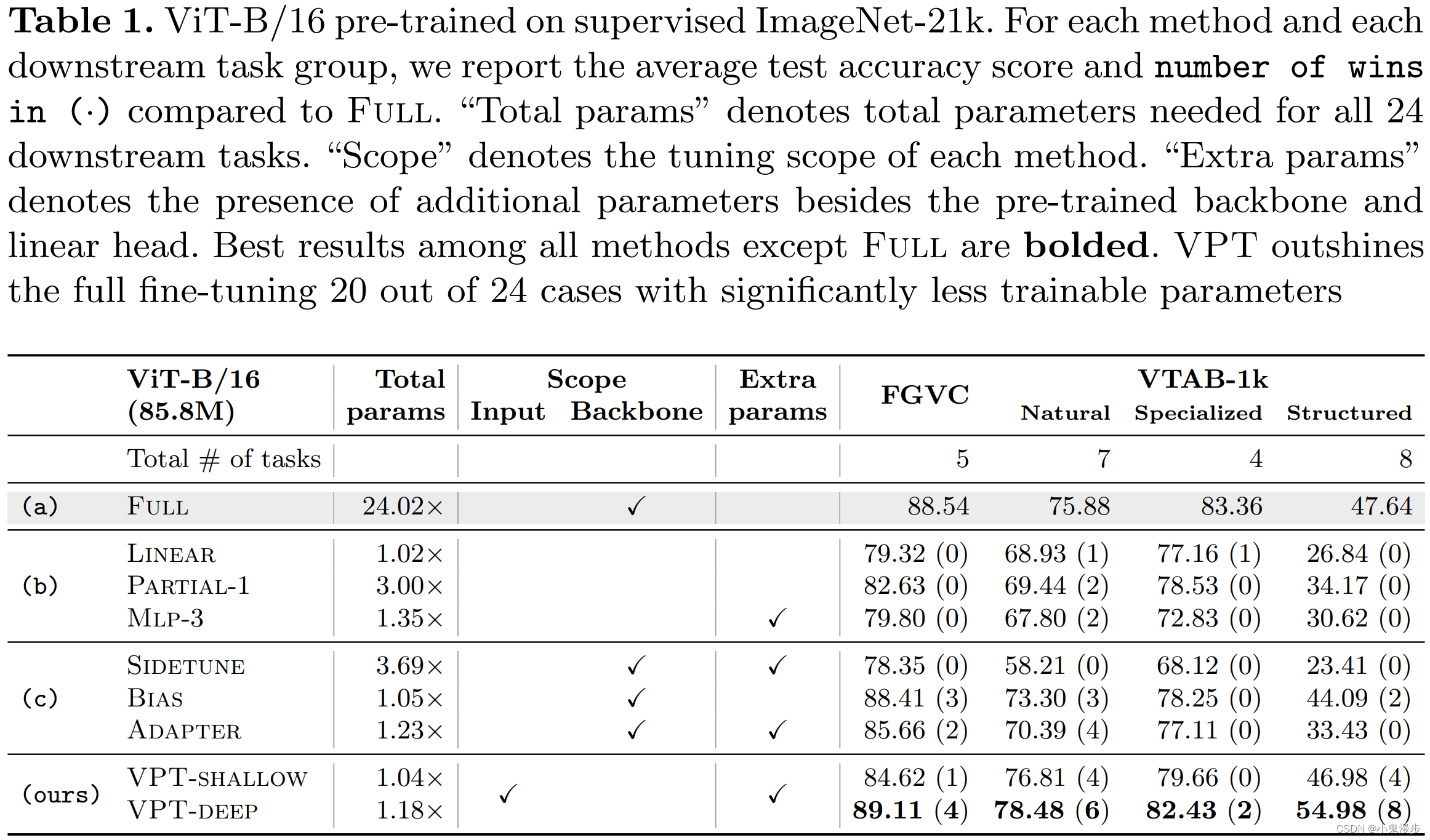
-
Even if storage is not a concern, VPT is a promising approach for adapting larger Transformers in vision. VPT-Deep outperforms all the other parameter-efficient tuning protocolsacross all task groups, indicating that VPTdeep is the best fine-tuning strategy in storage-constrained environments. Although sub-optimal than VPT-deep, VPT-shallow still offers non-trivial performance gain than head-oriented tuning methods, indicating that VPT-shallow is a worthwhile choice in deploying multi-task fine-tuned models if the storage constraint is severe.
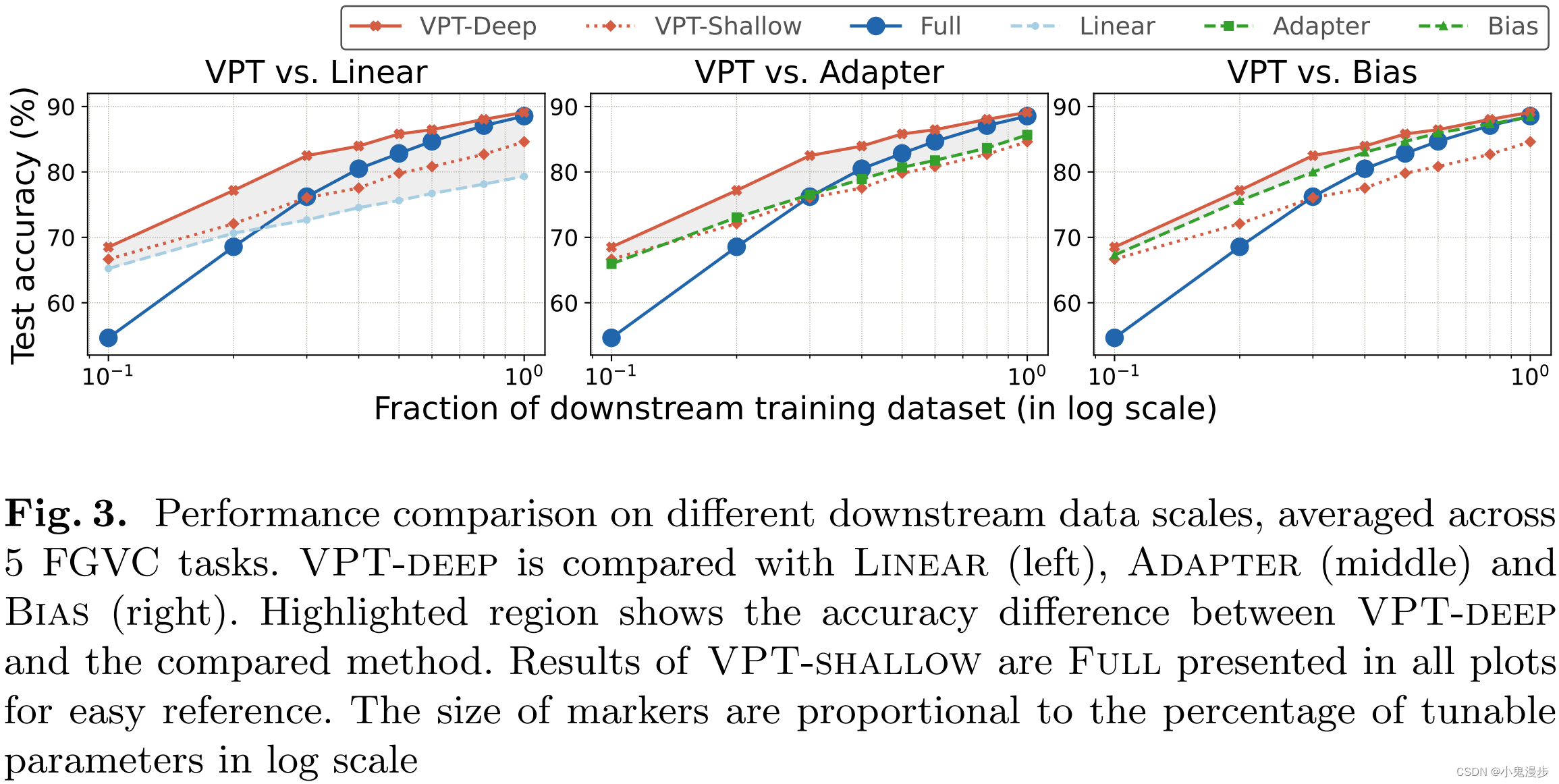
-
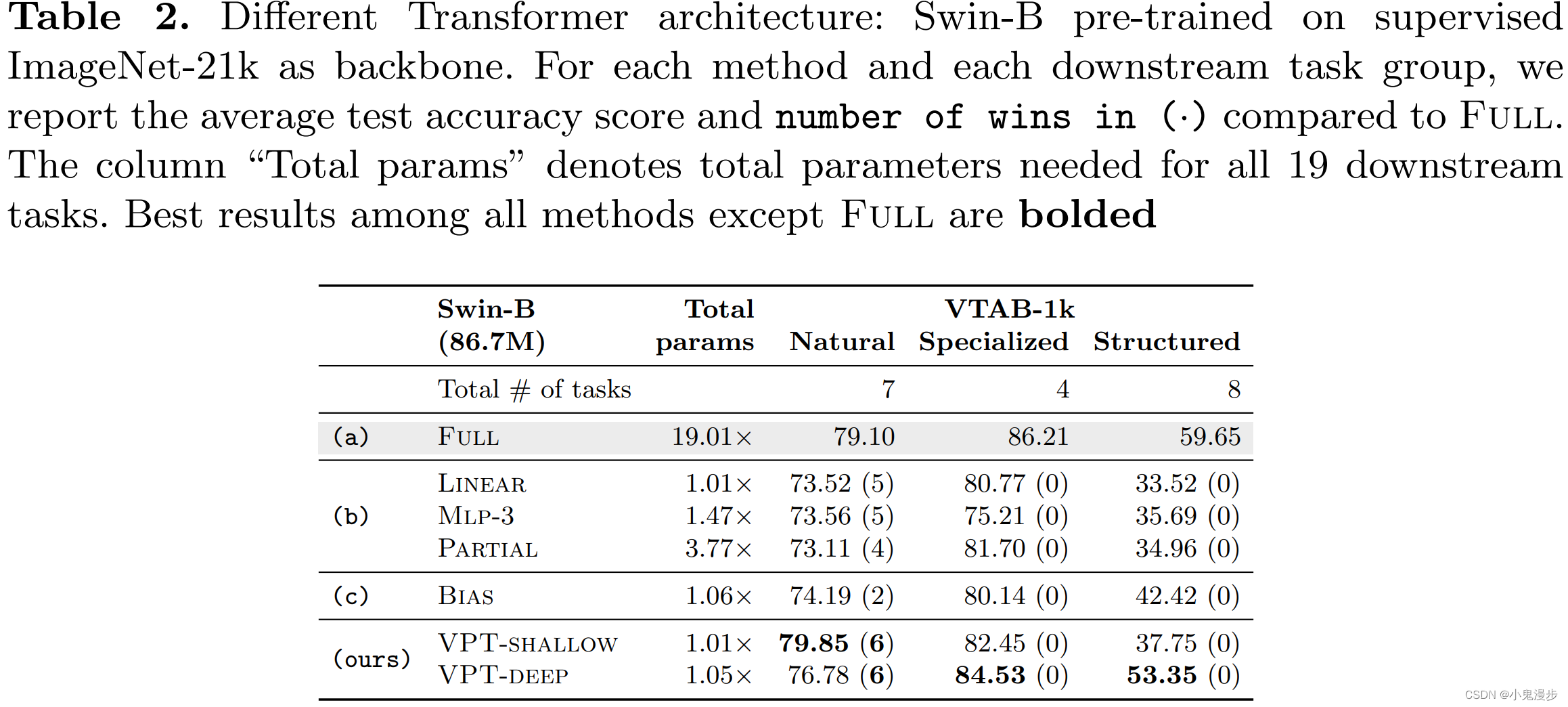
The experiments are conducted on the ImageNet-21k supervised pre-trained Swin-Base. VPT continues to outperform other parameter-efficient fine-tuning methods (b, c) for all three subgroups of VTAB, though in this case Full yields the highest accuracy scores overall (at a heavy cost in total parameters).


-
Yet the accuracy drops if we insert prompts from top to bottom, suggesting that prompts at earlier Transformer layers matter more than those at later layers.


-
In the case of MoCo v3, VPT no longer holds the best performance, though it is still competitive with the others. This suggests that these two self-supervised ViTs are
fundamentally different from the supervised ones in previous sections. Exactly why and how these differences arise remain open questions.
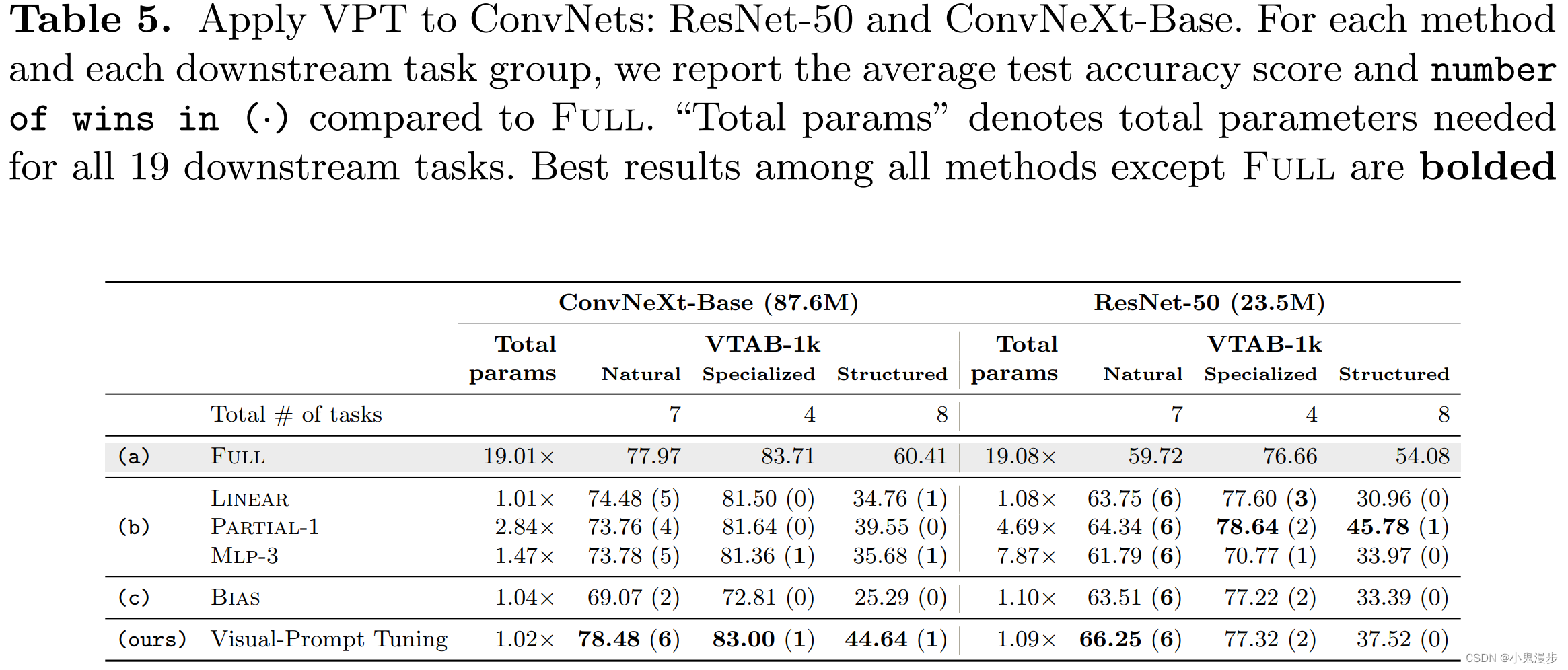
We examine the idea of adding trainable parameters in the input space of ConvNets: padding both height and width by p p p learnable prompt pixels for the input image. Though this operation seems unconventional, we implement VPT this way given there is no obvious solution to add location-invariant prompts similar to the Transformer counterparts. In fact this approach has been explored before in the adversarial attack literature. VPT works well in a larger ConvNet backbone, ConvNeXt-B, offering accuracy gains over other sparse tuning protocols (b, c), and outperforming Full on 8 out of 19 cases. The advantages of VPT, however, diminish with smaller ConvNet (ResNet50), as there is no clear winner for all 19 VTAB-1k tasks.
-
-
-
Conclusion
- We present Visual Prompt Tuning, a new parameter-efficient approach to leverage large vision Transformer models for a wide range of downstream tasks. VPT introduces task-specific learnable prompts in the input space, keeping the pretrained backbone fixed.
- We show that VPT can surpass other fine-tuning protocols (often including full fine-tuning) while dramatically reducing the storage cost.
- Our experiments also raise intriguing questions on fine-tuning dynamics of vision Transformers with different pre-training objectives, and how to transfer to broader vision recognition tasks in an efficient manner.















 1950
1950











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









