







由于直接爬取整个含有javascript的网页源代码,没办法处理分页的内容,所以这次换了种方式,就是利用Chrome浏览器工具抓取javacript文件get的网址,直接从源头入手。
1.打开谷歌开发工具 F12
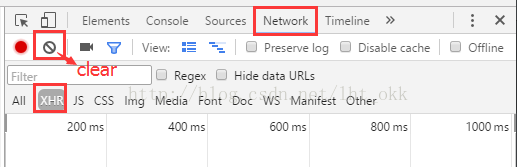
步骤:点击Network -- XHR(也有可能在JS,多尝试几遍) -- 接着点击clear
![]() 清空一下,按F5,接着点击页面中的
清空一下,按F5,接着点击页面中的
![]() 即可看到加载的javascript文件
即可看到加载的javascript文件
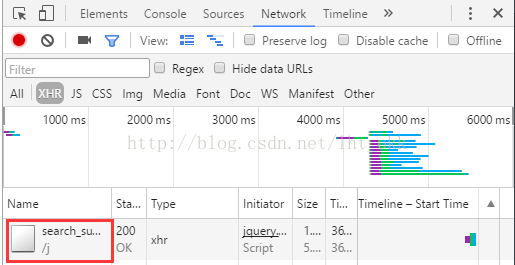
点开看看:
匹配下信息了,说明我们找对了文件。接着我们只要打开文件看看里面的内容有什么规律即可。
2.分析网址网页信息

https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=20
我们注意到里面的两个参数 page_limit 和 page_start ,我们尝试改变这两个参数看看有没有变化,结果发现page_limit表示一页中能显示多少个目标值,page_start表示从哪一个目标开始显示。
因此我们只要取一个足够大的值,让page_start从0开始便可以爬取所有豆瓣电影的链接。
3.实现代码
import sys import requests import json from bs4 import BeautifulSoup import re import pandas

因为链接存在subjects里面的url,因此我们要先去掉外面的subjects
json.loads(res.text)['subjects']
#获取子链接 def getSonurl(url): res = requests.get(url) content = json.loads(res.text)['subjects'] sonurl = [] for i in content: #获取链接 sonurl.append(i['url']) return sonurl
接着我们便能进入网址解析我们要内容了。
sonurl = getSonurl(url) #获取子链接
for i in sonurl: print sonurl
就这样结束了,成功解决分页的困难,当然各种各样的网站的网站解析可能不太一样,但抓取javascript文件一样的道理。
















 2551
2551

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











