







Anconda初步使用–鸢尾花lris数据集的SVM线性分类
文章目录
壹. Python3.7、Anaconda、jupyter、spyder的下载与安装。
(1). 下载
一般只需要下载Anconda就行,它会自带一个默认的python/jupyter/spyder软件,如果没有后面连个软件可以安装Anconda之后再另行安装,建议国内镜像源下载。
本人的百度网盘资源
提取码:c2cs
(2). 安装
双击安装文件即可安装。
安装完成后

贰. 创建虚拟环境exam1,并在虚拟环境下安装numpy、pandas、sklearn包。
-
开始–>打开 Aconda Navigator。

-
创建环境(也可以使用命令
conda create -n exam1 python=3.7)

3. 安装需要的包,这里由于网络环境的原因经常会下载失败,建议使用国内镜像源。开始–>进入命令行窗口

4. 使用命令conda info -e或conda env list查看当前已有的aconada环境
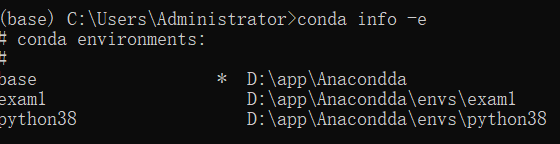
- 使用命令
conda activate exam1切换环境,conda list列出已安装的包

- 使用命令
-
使用命令
conda install -n exam1 pandas;conda install -n exam1 numpy;pip install sklearn -i "https://pypi.doubanio.com/simple";pip install matplotlib -i "https://pypi.douban.com/simple".




叁.对鸢尾花数据集的SVM线性分类
SVM介绍
SVM是一个二类分类器,它的目标是找到一个超平面,使用两类数据离超平面越远越好,从而对新的数据分类更准确,即使分类器更加健壮。
使用环境:jupyter notebook
- 原始数据的制作
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
from sklearn.svm import LinearSVC
iris = datasets.load_iris()
X = iris.data
y = iris.target
X = X [y<2,:2] # 只取y<2的类别,也就是0 1 并且只取前两个特征
y = y[y<2] # 只取y<2的类别
# 分别画出类别 0 和 1 的点
plt.scatter(X[y==0,0],X[y==0,1],color='red')
plt.scatter(X[y==1,0],X[y==1,1],color='blue')
plt.show()
运行结果——未经标准化的原始数据点分布:

2.训练模型
# 标准化
standardScaler = StandardScaler()
standardScaler.fit(X)
# 计算训练数据的均值和方差
X_standard = standardScaler.transform(X) # 再用 scaler 中的均值和方差来转换 X ,使 X 标准化
svc = LinearSVC(C=1e9) # 线性 SVM 分类器
svc.fit(X_standard,y) # 训练svm
结果

3.训练好之后,绘制决策边界:代码中再导入一个ListedColormap包
from matplotlib.colors import ListedColormap # 导入 ListedColormap 包
def plot_decision_boundary(model, axis):
x0, x1 = np.meshgrid( np.linspace(axis[0], axis[1], int((axis[1]-axis[0])*100)).reshape(-1,1),
np.linspace(axis[2], axis[3], int((axis[3]-axis[2])*100)).reshape(-1,1)
)
X_new = np.c_[x0.ravel(), x1.ravel()]
y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape)
custom_cmap = ListedColormap(['#EF9A9A','#FFF59D','#90CAF9'])
plt.contourf(x0, x1, zz, cmap=custom_cmap) #绘制决策边界
plot_decision_boundary(svc,axis=[-3,3,-3,3]) # x,y轴都在-3到3之间
# 绘制原始数据
plt.scatter(X_standard[y==0,0],X_standard[y==0,1],color='red')
plt.scatter(X_standard[y==1,0],X_standard[y==1,1],color='blue')
plt.show()
运行结果:

4. CC是控制正则项的重要程度,这里我们在实例化一个svc,并传入较小的CC。
svc2 = LinearSVC(C=0.01)
svc2.fit(X_standard,y)
plot_decision_boundary(svc2,axis=[-3,3,-3,3]) # x,y轴都在-3到3之间
# 绘制原始数据
plt.scatter(X_standard[y==0,0],X_standard[y==0,1],color='red')
plt.scatter(X_standard[y==1,0],X_standard[y==1,1],color='blue')
plt.show()
运行结果:

可以很明显的看到和第一个决策边界的不同,在这个决策边界汇总,有一个红点时分类错误的。CC越小容错空间越大。可以通过svc.coef_来获取学习到的权重系数,svc.intercept_获取偏差。
使用多项式特征和核函数
- 处理非线性数据。
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
X, y = datasets.make_moons() #使用生成的数据
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()
结果:

2.增加噪声点
X,y = datasets.make_moons(noise=0.15,random_state=777)
#随机生成噪声点,random_state是随机种子,noise是方差
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()
结果

3. 通过多项式特征的SVM来对它进行分类
from sklearn.preprocessing import PolynomialFeatures,StandardScaler
from sklearn.svm import LinearSVC
from sklearn.pipeline import Pipeline
def PolynomialSVC(degree,C=1.0):
return Pipeline([ ("poly",PolynomialFeatures(degree=degree)),#生成多项式
("std_scaler",StandardScaler()),#标准化
("linearSVC",LinearSVC(C=C))#最后生成svm
])
poly_svc = PolynomialSVC(degree=3)
poly_svc.fit(X,y)
plot_decision_boundary(poly_svc,axis=[-1.5,2.5,-1.0,1.5])
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()
运行结果:

使用核技巧对数据进行处理,使其维度提升,使原本线性不可分的数据,在高维空间变成线性可分的。再用线性SVM来进行处理。
from sklearn.svm import SVC
def PolynomialKernelSVC(degree,C=1.0):
return Pipeline([ ("std_scaler",StandardScaler()),
("kernelSVC",SVC(kernel="poly")) # poly代表多项式特征
])
poly_kernel_svc = PolynomialKernelSVC(degree=3)
poly_kernel_svc.fit(X,y)
plot_decision_boundary(poly_kernel_svc,axis=[-1.5,2.5,-1.0,1.5])
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()
运行结果:

可以看到这种方式也生成了一个非线性的边界。这里的SVC(kernel=“poly”)有个参数是kernel,就是核函数。














 1220
1220











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









