






首先要知道vit是啥东西。vit就是transformer模型在图像领域的运用。
transformer模型原本是用于自然语言的,encoder和decoder接受的都是文字。vit把图像分割成很多个小块,把各个小块拉长当成向量来用,接下来就是一样的。最后接一个全连接层做分类。

注意它只用了encoder部分哦
有些模型会把最后得到的tokens做一个平均作为输入给最后的全连接层的值(用这个平均作为这个图片上提炼出来的信息),有些模型会在后面加上一个cls 作为 token(bert饼干),最后拿这个cls对应的值作为图像的信息。albet使用的是后者的方法。
再来看albet部分:
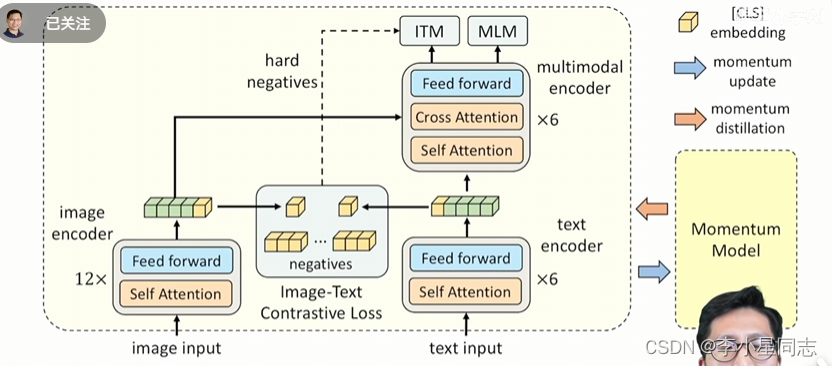
左边那一部分其实和vit一毛一样,(可能是图像进入transformer模型的通用方法)提出来的黄色方块就是上文提到的cls对应的token,是图像信息的精华。
右边的部分是bert模型的一部分。用这个已经预训练过的语言模型处理text信息,bert模型那当然cls不得不品,和隔壁cls图像信息门当户对
这里的特点在于他把bert模型拆开了,(不拆开那不就是clip吗)
首先要对刚刚拿到的两个token做简化(downsample , normalization,把向量变短)
得到了两个正样本,就要尽可能让他们两个更近,负样本存在下面的队列里(moco操作,没有梯度不用占一大堆内存)通过正样本和负样本的对比学习得到的loss让图像特征和文本特征尽量拉近。在这一步就要让图像和文本尽量配对
事实上,这个模型只需要下面半部分就已经可以通过正负样本的学习来学习哪些图像和文本可以配对了。
ITM(img text matching)loss是什么?判断文本和图片匹不匹配。这一步不给他上强度的话会很简单,所以会从一开始搞正负样本的地方找出一个与正样本相似度最高的样本作为负样本给它判断,强化其能力。
MLM就是bert的完型填空,但也运用了图像那一边传过来的信息。
主体部分就是这样,接下来是重量级:动量蒸馏
这个主要适用于对付从互联网上爬下来的垃圾数据。我们获得的图像和对应文本经常会牛头不对马嘴,别的文本却又刚好可以放进去,这样正样本和负样本对比学习就要学出史来了。
应对方法:不要one-hot而是multi-hot,从动量模型里得出一些可以的描述,让结果既要和正样本去靠拢,也要接近这些。
问题:动量模型是从哪来的?















 253
253











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









