






学习论文:ScreenAI: A Vision-Language Model for UI and Infographics Understanding
摘要部分介绍了作者的screenai,是一个专门用于UI和信息图形理解的视觉语言模型。模型利用pix2struct灵活的补丁策略改进了PaLI架构,并在独特的数据集混合上进行了训练。
他的主要任务是屏幕注释(识别UI的类别,位置),用这些注释交给大语言模型,并自动生成问答(QA)、UI导航和摘要训练数据集。最后还做了消融实验。
主要贡献如下:
我们提出ScreenAI,一种视觉语言模型(VLM),作为一种整体解决方案,专注于理解UI和信息图形,利用其常见的视觉语言和设计复杂性。
•我们介绍了UI的文本表示,用于教我们的模型如何在预训练阶段理解UI。
•我们利用这种新的UI表示和大型语言模型(LLM)自动大规模生成训练数据。
•我们定义了预训练和微调混合物,涵盖了UI和信息图理解中的广泛任务。
•我们为第4.2节中描述的任务发布了三个评估数据集:Screen Annotation、ScreenQA Short和Complex ScreenQA。这些数据集使研究界能够利用我们的文本表示和al low对基于屏幕的问答模型进行更全面的基准测试。
模型结构如图:
可以看到,这里的图像和文字是一起embed,一起自注意力的,因为他们都是输入。记住decoder那边永远只会有字典,不会有正儿八经的输入数据走那边的。
接下里是重量级:数据集怎么做的。
首先作者收集了大量的截图,然后给他们做注释。注释就是给图像上的各个元素加上框框,同时解释一下是什么东西。这个其实就是一个分类任务,有现成的模型可以用。
接下来,在大语言模型的帮助下,可以生成更高级的任务,例如QA……
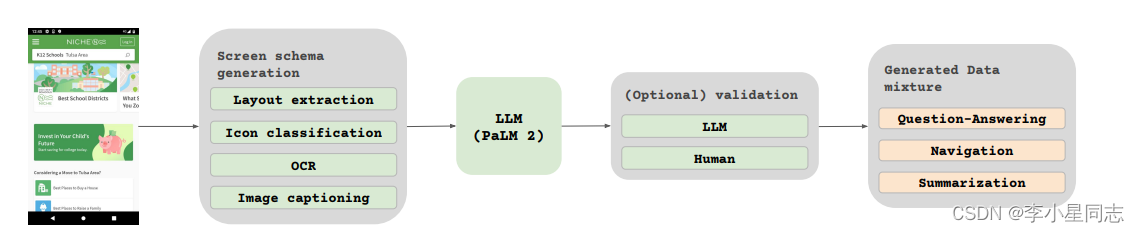
最后得到的数据集:

最后我们使用这个数据集训练模型,训练项目其实也就是注释,QA,Navigation(就是叫他‘返回’,他会知道要按哪个按钮),总结。
这样,在注释模型,常规多模态大语言模型的帮助下,我们做出了一个注重UI交互的数据集,并在此基础上训练出了一个重视理解UI能力的多模态大语言模型。
最后就是实验和收集数据。学习结束。














 160
160











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









