PyTorch是一款基于Python的科学计算库,主要用于机器学习和深度学习的研究。在PyTorch中,线性回归是最基本的机器学习模型之一,以下是PyTorch实现线性回归的示例代码。
首先,我们需要导入PyTorch库和一些必要的包:
``` python
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
```
接下来,我们需要定义一些超参数:
``` python
input_size = 1
output_size = 1
num_epochs = 60
learning_rate = 0.001
```
这里,我们定义了输入和输出的维度,训练的轮数和学习率。
然后,我们需要准备训练数据和测试数据。在这个例子中,我们使用一个简单的数据集,包含了一些关于人口和收入的信息。我们的目标是根据人口预测收入。我们可以使用NumPy来生成数据集:
``` python
x_train = np.array([[1.2], [2.4], [3.6], [4.8], [6.0], [7.2], [8.4], [9.6], [10.8], [12.0]])
y_train = np.array([[2.5], [4.8], [7.1], [9.4], [11.7], [14.0], [16.3], [18.6], [20.9], [23.2]])
x_test = np.array([[1.5], [3.0], [4.5], [6.0], [7.5], [9.0], [10.5], [12.0], [13.5], [15.0]])
y_test = np.array([[3.2], [6.4], [9.6], [12.8], [16.0], [19.2], [22.4], [25.6], [28.8], [32.0]])
```
接下来,我们需要将数据转换为张量,并且创建一个线性回归模型。在这个例子中,我们使用PyTorch的nn.Linear模块来实现线性回归模型:
``` python
# Convert numpy arrays to torch tensors
x_train = torch.from_numpy(x_train).float()
y_train = torch.from_numpy(y_train).float()
x_test = torch.from_numpy(x_test).float()
y_test = torch.from_numpy(y_test).float()
# Create linear regression model
model = nn.Linear(input_size, output_size)
```
然后,我们需要定义损失函数和优化器。在这个例子中,我们使用均方误差(MSE)作为损失函数,使用随机梯度下降(SGD)作为优化器:
``` python
# Define loss function and optimizer
criterion = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
```
接下来,我们可以开始训练模型。在每个epoch中,我们将模型的输出与实际值进行比较,并计算损失。然后,我们使用反向传播算法更新模型的参数。
``` python
# Train the model
for epoch in range(num_epochs):
# Forward pass
outputs = model(x_train)
loss = criterion(outputs, y_train)
# Backward and optimize
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch+1) % 10 == 0:
print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, loss.item()))
```
最后,我们可以使用测试集来评估模型的性能:
``` python
# Test the model
with torch.no_grad():
predicted = model(x_test)
test_loss = criterion(predicted, y_test)
print('Test Loss: {:.4f}'.format(test_loss.item()))
# Plot the graph
plt.plot(x_test.numpy(), y_test.numpy(), 'ro', label='Original data')
plt.plot(x_test.numpy(), predicted.numpy(), 'b-', label='Fitted line')
plt.legend()
plt.show()
```
完整代码如下:
``` python
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
# Hyper-parameters
input_size = 1
output_size = 1
num_epochs = 60
learning_rate = 0.001
# Toy dataset
x_train = np.array([[1.2], [2.4], [3.6], [4.8], [6.0], [7.2], [8.4], [9.6], [10.8], [12.0]])
y_train = np.array([[2.5], [4.8], [7.1], [9.4], [11.7], [14.0], [16.3], [18.6], [20.9], [23.2]])
x_test = np.array([[1.5], [3.0], [4.5], [6.0], [7.5], [9.0], [10.5], [12.0], [13.5], [15.0]])
y_test = np.array([[3.2], [6.4], [9.6], [12.8], [16.0], [19.2], [22.4], [25.6], [28.8], [32.0]])
# Convert numpy arrays to torch tensors
x_train = torch.from_numpy(x_train).float()
y_train = torch.from_numpy(y_train).float()
x_test = torch.from_numpy(x_test).float()
y_test = torch.from_numpy(y_test).float()
# Create linear regression model
model = nn.Linear(input_size, output_size)
# Define loss function and optimizer
criterion = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
# Train the model
for epoch in range(num_epochs):
# Forward pass
outputs = model(x_train)
loss = criterion(outputs, y_train)
# Backward and optimize
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch+1) % 10 == 0:
print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, loss.item()))
# Test the model
with torch.no_grad():
predicted = model(x_test)
test_loss = criterion(predicted, y_test)
print('Test Loss: {:.4f}'.format(test_loss.item()))
# Plot the graph
plt.plot(x_test.numpy(), y_test.numpy(), 'ro', label='Original data')
plt.plot(x_test.numpy(), predicted.numpy(), 'b-', label='Fitted line')
plt.legend()
plt.show()
```








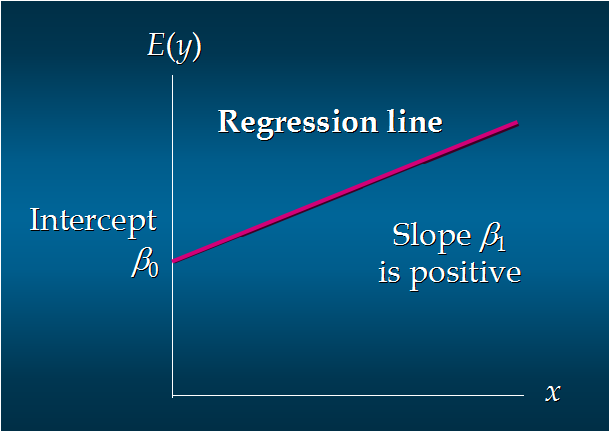
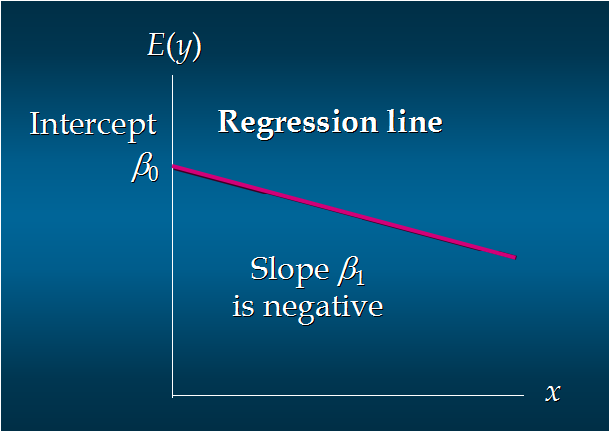
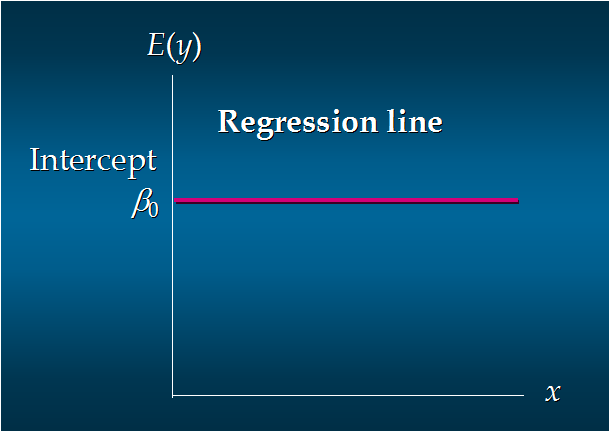
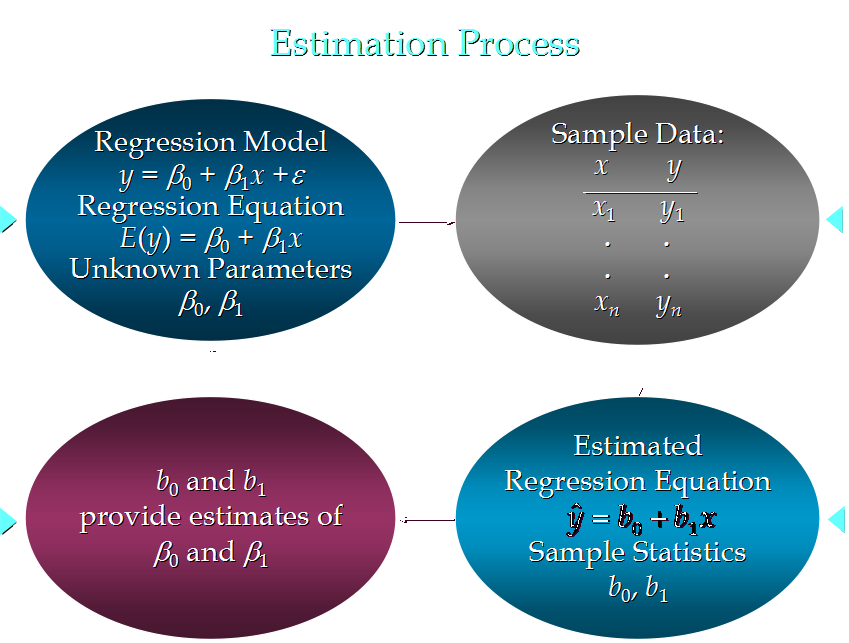














 104
104











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









