







6.1 简介
在传统的CPU模型中,内存是线性内存或平面内存,单个CPU核可以无约束地访问任何地址的内存。在CPU的硬件实际实现中,有许多一级(L1)、二级(L2)以及三级(L3)缓存。那些善于对CPU代码进行优化以及有高性能计算(High-Performance Computing,HPC)背景的人,对这些缓存甚是熟悉。然而对大多数程序员而言,这些概念却显得非常的抽象。
抽象已经在现代程序语言中成为了一种趋势。它使程序员离底层硬件越来越远,以确保程序员不必过多了解底层硬件就可以编写程序。虽然抽象将问题提升到一个更高的层次,使得问题解决更加简单,程序的生产率也提高了一个等级,但它仍需要灵活的编译器将上层的抽象转换成底层硬件能够理解的形式。理论上,抽象是一个非常伟大的概念,但事实上却很难将其毫无瑕疵地实现。相信在未来的几十年里,我们可以看到编译器与程序语言得到巨大改善,使其能自动地利用并行硬件。但目前而言,要想程序在不同平台获得高性能,还必须了解硬件是如何工作的,这是问题的关键所在。
在一个基于CPU的系统中,如果要获取好的性能,就必须了解缓存是如何工作的。我们首先来看CPU端的缓存,然后将其与GPU端的缓存进行对比,看看有哪些相似之处。从指令流的角度来看,大多数程序都是以顺序方式执行,其中包含了各种各样的循环结构。如果程序调用了一个函数,很有可能该程序会很快再次调用这个函数,如果程序对某一块特殊的内存进行了访问,很有可能在很短的时间内程序会再次对这块内存进行访问。当对某块数据已经使用过一次后还可能再次使用,某个函数执行一次之后还可能再次执行,这就是时间局部性(temporal locality)原则。
从一个计算机系统中的主内存DRAM中获取数据会非常的慢。相对于处理器的时钟频率,DRAM的存取速度一直都非常慢。随着处理器时钟频率的不断提高,DRAM的存取速度就更跟不上处理器的时钟频率了。
目前处理器搭配的 DDR-3 DRAM 一般能达到1.6GHz。当然,如果配备一些高速的模块以及更好的处理器,其最高能达到2.6GHz。然而,CPU的每个核一般都能达到3.0GHz,如果没有缓存进行快速存取,那么对CPU而言,DRAM的带宽非常不足。由于代码与数据都存在 DRAM中,如果无法快速地从DRAM获取程序与数据,CPU的指令带宽(一个时间帧内指令执行的数量)会明显受到限制。
这里有两个比较重要的概念,一个是存储带宽(memory bandwidth),即在一定时间内从DRAM 读出或写人的数据量。另一个是延迟(1atency),即响应一个获取内存的请求所花费的时间,通常这个时间会是上百个处理器周期。如果一个程序需要从内存获取四个元素,则将所有请求一起处理然后等待所有数据到达,总要好过处理一个请求然后等待数据到达,处理下一个后再等待。因此,如果没有缓存,处理器的存储带宽将会受到很大限制,延迟也会增大很多。
我们用超市的收银过程作为例子,来形象化地介绍存储带宽与延迟。假设一家超市有N个收银台,并不是每个收银台都有员工在工作。如果只有两个收银台正常工作,顾客将会在这两个收银台后面排起很长的队等待付款。每个收银台在一定时间内(例如,一分钟)处理的顾客的人数就是吞吐量或者带宽。而顾客在队列中需要等待的时间则为延迟,即顾客从进入队列直到付款离开所花费的时间,
由于队伍越来越长,店主可能会增加更多收银台进行工作,顾客就会分流到到新的收银台。如果新开两个收银台工作,收银台的带宽将增加一倍,因为在相同的时间内可以服务两倍于之前的人数。此外,延迟也会减半,因为平均每个队列只有原先的一半长,等待的时间也就减少了一半。
然而,这并不是免费的。更多的收银台意味着需要花更多的钱雇更多的收银员;超市更多的零售空间需要分配给收银台,相应地,货架空间就会减少。从内存总线带宽与内存设备时钟频率的角度来看,处理器的设计也出现了相同的权衡点。设备上硅片占用的空间是有限的,外部内存总线的宽度通常会受到处理器上物理引脚数目的限制。另一个需要理解的概念为事务开销(transaction overhead)。当收银员为每名顾客处理付款操作时就有明显的开销。有些顾客的购物篮中只有两三件物品,而有些购物车则充满了物品。店主会更喜欢那些购满整个购物车的顾客,因为他们可以更加高效地处理,即收银员会花费更多的时间在清点货物上,而不是处理付款。
在GPU中,我们能看到类似的机理。有些内存事务,相较于处理它们的开销来说,是属于轻量级的。因此,内存单元获取的时间相对于开销而言也就较少,换言之,即达到最高效率的百分比很低。但有些事务比较庞大,需要花大量的时间才能完成,这些事务能高效地处理并能达到接近最高的存储传输速率。它们在一端转化成基于字节的内存事务,而在另一端转换成基于字的存储事务。为了获得最高的存储效率,GPU需要大量的庞大事务和尽可能少的轻量级事务。
6.2高速缓存
高速缓存是硬件上非常接近处理器核的高速存储器组。高速缓存主要由硅制成,但由于硅很贵,因此高速缓存的价格也很昂贵。此外,硅还可以用来制成更大的芯片以及低产却价格更贵的处理器。例如,许多服务器上的英特尔至强芯片(the Intel Xeon,常用于服务器)比普通台式机搭载的处理器贵得多,因为它搭载了巨大的三级缓存,而普通处理器搭载的缓存比较小。
高速缓存的最大速度与缓存的大小成反比关系。一级缓存是最快的,但它的大小一般限制在16KB、32KB或者64KB。通常每个CPU核会分配一个单独的一级缓存。二级缓有相对而言慢一些,但是它更大,通常有256KB~512KB。三级缓存可能存在也可能不存在,如果存在,通常是几兆字节的大小。二级缓存或三级缓存一般在处理器的核之间是共享的,或者作为连接于特定处理器核的独立缓存来维护。在传统的CPU上,一般而言,至少三级缓存在处理器核之间是共享的。处理器核便可通过设备上这块共享内存快速地进行通信。
G80与GT200系列GPU没有与CPU中高速缓存等价的存储器,但它们却有两块基于硬件托管的缓存,即常量内存与纹理内存,它们类似CPU中的只读缓存。与CPU不同,GPU主要依赖基于程序员托管的缓存或共享内存区。
在费米架构的GPU实现中,第一次引人了不基于程序员托管的数据缓存这个概念。这个架构的GPU中每个SM有一个一级缓存,这个一级缓存既是基于程序员托管的又是基于硬件托管的。在所有的SM 之间有一个共享的二级缓存。
缓存在处理器的核或SM之间共享有什么意义?为什么要这样安排?这主要是为了让设备之间能够通过相同的共享缓存进行通信。共享缓存允许处理器之间不需要每次都通过全局内存进行通信。这在进行原子操作的时候特别有用,由于二级缓存是统一的,所有的SM 在给出的内存地址处获取一致版本的数据。处理器无须将数据写回缓慢的全局内存中,然后再读出来,它只需要保证处理器核之间的数据一致性。在G80与GT200系列的硬件设备上,并没有统一的高速缓存,因此与费米以及后续的设备相比,在它们上面做原子操作会非常慢。
对大多数程序而言,高速缓存非常有用。很多程序员既不关心也不了解如何在编写软件时获取更好的性能。缓存的引人使得大多数程序能够更加合理地运转,程序员也不需要过多地了解硬件是如何工作的。但这种简单的编程方式只适合最初的学习,多数情况下,我们需要更加深入地了解。
一名CUDA的初学者与一名CUDA的专家相比,差距可能非常大。希望读者通过阅读此书,能够迅速学会编写CUDA代码,用并行代码替换你原来的串行代码,使你的程序加速好几倍。
数据存储类型
GPU 提供了不同层次的若干区域供程序员存放数据,每块区域根据其能达到的最大带宽以及延迟而定义,如表6-1所示。
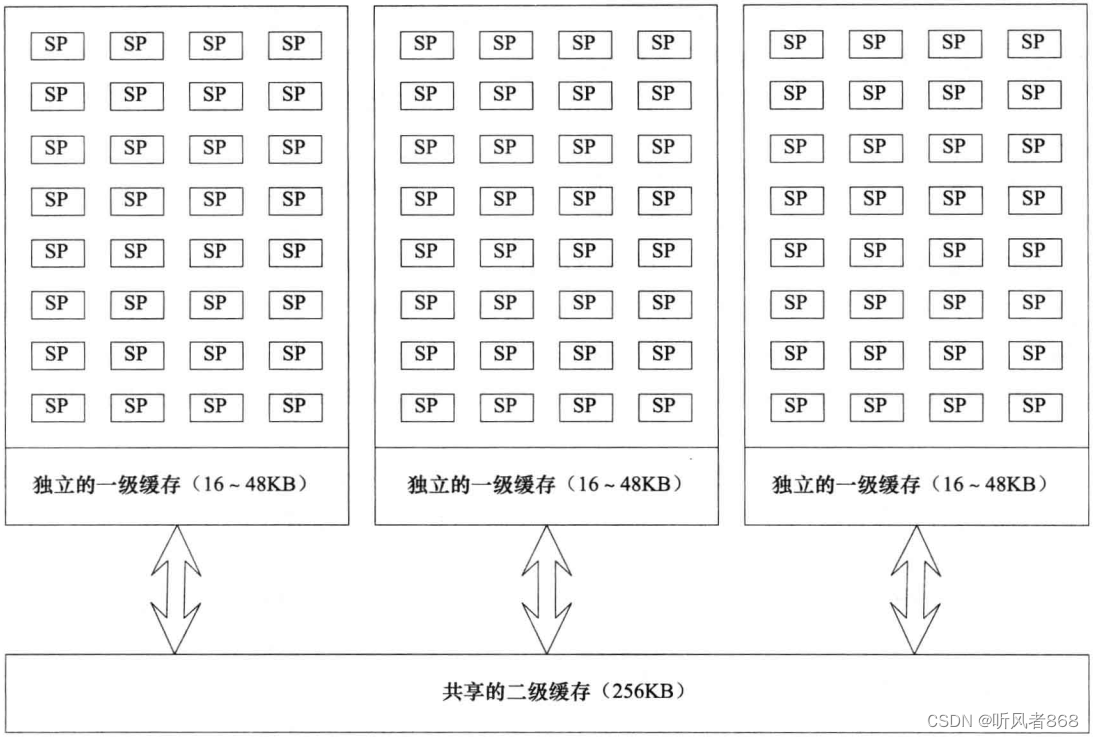
图6-1 SM一级缓存与二级缓存数据通路
表 6-1不同存储类型的访问时间

最快速也最受偏爱的存储器是设备中的寄存器,接着是共享内存,如基于程序员托管的一级缓存,然后是常量内存、纹理内存、常规设备内存,最后则是主机端内存。注意不同存储器之间的存储速度的数量级的变化规律。本章将依次介绍这几种存储器的使用以及如何最大化地利用它们。
传统上,绝大多数书籍会从全局内存开始介绍,因为它在性能优化中扮演着关键角色。除非获取全局内存的模式正确,否则一旦模式错误,就没有必要再去谈优化了。而本书将采用一种不同的方式进行介绍,本章将首先介绍如何高效地使用最内部的设备,由内而外,最后介绍全局内存以及主机端内存,让读者能够理解不同层次的存储器的效率以及知道如何获得高效。
大多数CUDA程序都是逐渐成熟的。一开始使用全局内存初始化,初始化完毕之后再考虑使用其他类型的内存,例如,零复制内存(zero-copymemory)、共享内存、常量内存、最终寄存器也被考虑进来。为了优化一个程序,我们需要在开发过程中考虑这些问题。在程序之初就要考虑使用速度较快的存储器,并且准确知道在何处以及如何提高程序性能,而不是在程序写完之后才想到用哪些快速的存储器对程序进行优化。另外,不仅要思考如何高效地访问全局内存,也要时刻想办法减少对全局内存的访问次数,尤其在数据会被重复利用的时候。
6.3 寄存器的用法
与CPU不同,GPU的每个SM(流多处理器)有上千个寄存器。一个SM可以看作是一个多线程的 CPU核。一般 CPU拥有二、四、六或八个核。但一个GPU却有N个 SM 核。在高端的费米GF100系列的顶级设备上有16个SM,GT200系列的设备上的SM数目多达32个,G80系列的设备SM最多也有16个。
看起来很奇怪,费米架构设备上的SM数目居然比早期的一些设备还要少。这是因为费米架构设备上每个SM拥有更多的SP(流处理器),而所有的工作其实都是SP处理的。由于每个核上SP数目不同,因此每个核支持的线程数目也有很大的不同。一般地,CPU每个核会支持一到两个硬件线程。相比之下,GPU的每个核可能有8~192个SP,这意味着每个SM在任何时刻都能同时运行这些数目的硬件线程。
事实上,GPU上的应用线程进入流水线、进行上下文切换并分配到多个SM中。这意味着在一台GPU设备的所有SM中活跃的线程数目通常数以万计。
CPU与GPU架构的一个主要区别就是CPU与GPU映射寄存器的方式。CPU通过使用寄存器重命名和栈来执行多线程。为了运行一个新任务,CPU需要进行上下文切换,将当前所有寄存器的状态保存到栈(系统内存)上,然后从栈中恢复当前需要执行的新线程上次的执行状态。这些操作通常需要花费上百个CPU时钟周期。如果在CPU上开启过多的线程时间几乎都将花费在上下文切换过程中寄存器内容的换进/换出操作上。因此,如果在CPU开启过多的线程,有效工作的吞吐量将会快速降低。
然而,GPU却恰恰相反。GPU利用多线程隐藏了内存获取与指令执行带来的延迟。因此在 GPU上开启过少的线程反而会因为等待内存事务使GPU处于闲置状态。此外,GPU也不使用寄存器重命名的机制,而是致力于为每一个线程都分配真实的寄存器。因此,当需要上下文切换时,所需要的操作就是将指向当前寄存器组的选择器(或指针)更新,以指向下一个执行的线程束的寄存器组,因此几乎是零开销。
注意这里用到了线程束的概念。在第5章介绍线程的部分已经详细地介绍了这个概念。一个线程束即同时调度的一组线程。在当前的硬件中,一个线程束包含32个线程。因此,在一个SM中,每次换进/换出、调度都是32个线程同时执行。
每个SM能调度若干个线程块。在SM层,线程块即若干个独立线程束的逻辑组。编译时会计算出每个内核线程需要的寄存器数目。所有的线程块都具有相同的大小,并拥有已知数目的线程,每个线程块需要的寄存器数目也就是已知和固定的。因此,GPU就能为在硬件上调度的线程块分配固定数目的寄存器组。
然而在线程层,这些细节对程序员是完全透明的。如果一个内核函数中的每个线程需要的寄存器过多,在每个SM中GPU能够调度的线程块的数量就会受到限制,因此总的可以执行的线程数量也会受到限制。开启的线程数量过少会造成硬件无法被充分利用,性能急剧下降,但开启过多又意味着资源可能短缺,调度到SM上的线程块数量会减少。
这一点要特别注意,因为它可能引起应用程序的性能突然下降。如果一个应用程序先前使用了4个线程块,现在改用更多的寄存器,可能导致只有3个线程块可供调度,这样GPU的吞吐量会降低1/4。这种类型的问题可以利用许多性能分析的工具来定位,本书的第7章将会介绍性能分析的内容。
由于所使用的硬件不同,每个SM可供所有线程使用的寄存器空间大小也不同,分别有8KB、16KB、32KB以及64KB。牢记,每线程中每个变量会占用一个寄存器。因此,C语言中的一个浮点型变量就会占用N个寄存器,其中N代表调度的线程数量。在费米架构的设备上,每个SM拥有32KB的寄存器空间。如果每个线程块有256个线程,则每个线程可使用32(32768/4/256)个寄存器。为了让费米架构的设备上的每个线程可使用的寄存器数目达到最大,即64个寄存器(G80及GT200上最多128个),每个线程块上的线程数目需要减少一半,即128。当线程块上的寄存器数目是允许的最大值时,每个SM会只处理一个线程块。同样,也可以使用四个线程块,每个线程块32个线程(一共4x32=128个线程),每个线程使用的寄存器数目也能达到最多。
如果能够最大化地利用寄存器,例如,使用寄存器对一个数组的某一块进行计算,会非常高效。由于这一组值通常是数据集中的N个元素,元素之间是相互独立的,因此可以在单个线程中实现指令级的并行(Instruction-LevelParallelism,ILP)。这是由硬件将许多独立的指令流水线化实现的。后面将有一个实际例子来具体介绍这种方案。
然而,大多数内核对寄存器的需求量都很低。如果将寄存器的需求量从128降到64,则相同的SM 上可再调度一个线程块。例如,如果需要32个寄存器,则可调度四个线程块通过这样做,运行的线程总数可以得到提高。在费米型设备上,每个SM最多能运行1536个线程。一般情况下,占用率越高,程序就运行得越快。当线程级的并行(Thread-LevelParallelism,TLP)足以隐藏存储延迟时将会达到一个临界点,如果想继续提高程序的性能要么考虑更大块的存储事务,要么引人ILP,即单个线程处理数据集的多个元素。
但是,每个SM 能够调度的线程束的数量也是有限制的。因此,将每个线程需要的寄存器数量从32降到16,并不意味着SM能调度8个线程块。表6-2显示了当线程块中的线程数为 192与256以及线程需要的寄存器数目不同时,每个SM能够调度的线程块的数目。
表6-2 费米架构设备每个线程寄存器的可利用率
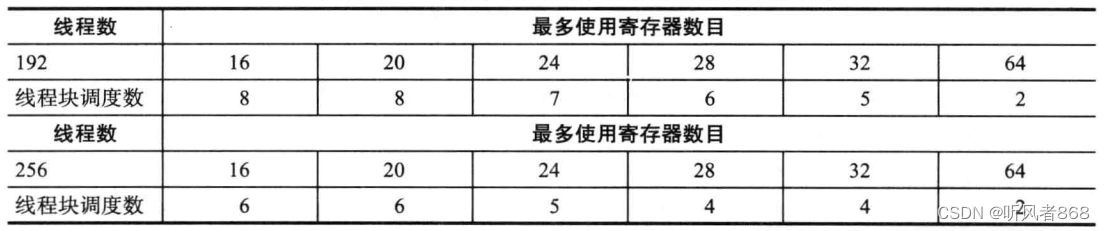
表6-2中的测试设备为费米架构的设备。至于开普勒架构的设备,只需简单地将表中的寄存器数目与线程块数目加倍即可。此处使用192与256个线程进行测试是因为它们能保证硬件的充分利用。注意当内核使用的寄存器的数目为16与20时,SM上调度的线程块的数目并没有增加,这是因为分配到每个SM上的线程束的数量是有限制的。在这种情况下,可以不考虑是否影响每个 SM 运行的线程总数而直接增加寄存器的使用量。
如果想使用寄存器来避免其他更慢的内存类型的使用,需要注意有效地使用它们。例如,一个循环根据一些布尔变量依次设置某个值的每一位。高效的方法是将32个布尔值封装到一个32位的字中,然后解封装。可以写这样一个循环,每次根据新的布尔值修改内存中的内容,做移位操作,移至字中的正确位置,如下所示:

从数组中读出第i个元素然后将其封装到一个整型数packed_result中。将布尔值向左移位必要的位数,然后与之前的结果做“按位或”操作。
如果变量packed_resut存于内存中,则需要做32次读/写内存的操作。但如果将变量packed_result设置为局部变量,编译器会将其放入寄存器中,在寄存器中而不是在主内存中做操作,最后再将结果写回主内存中,因此可节省31次内存读/写的操作。
这时,再回过头来看表6-1,你会发现每做一次全局内存的读/写操作需要花费上百个时钟周期。假定每做一个全局内存的读/写操作需要花费500个时钟周期。如果每次循环都需要从全局内存读取数据,然后按位或,最后写回全局内存,则一共需要32 x读操作时间+ 32 x写操作时间 = 64 x 500个时钟周期 = 32000个时钟周期。而使用寄存器则可消除31次读操作以及31次写操作,用一个时钟周期代替之前的500个时钟周期,因此一共花费(1 x读内存时间)+(1 x写内存时间) + (31 x读寄存器时间) + (1 x写寄存器时间)即(1x500)+(1x500)+(31x1)+(31x1)=1062个时钟周期,相比于32000个时钟周期时钟周期明显减少很多。因此,在相同问题领域里执行较简单的操作能够将性能提高31倍。
在 sum、min、max等普通的归约操作中也会看到类似的关系。所谓的归约操作,即利用函数将某个较大的数据集减少为较小的集合,通常减少到一个单项。例如,max(10,12,1,4,5)会返回数据集中最大的那个值12。
将结果累积在寄存器中可省去大量的内存写操作。在位包装的这个例子中,写内存的操作次数减少了31倍。无论是用CPU还是GPU,这种寄存器的优化方式都会使程序执行速度得到很大提高。
然而,这种优化方式需要程序员思考哪些参数是存于寄存器中,哪些参数是存于内存中,哪些参数需要从寄存器中复制回内存,等等。通常,这对一般的程序员而言显得有些困难。因此,许多程序员的代码都是直接运行在内存上。绝大多数CPU上的缓存可以通过将累计计算的值保存在一级缓存,从而有效掩饰这类问题。将数据写回缓存,避免将数据写回主内存,程序的性能并不会太差。但需要注意的是一级缓存仍然比寄存器慢,因此这种方案并不是最优化的,它可能比最优方案慢好几倍。
有些编译器可以自动检测出一些不高效的方式,并在优化阶段将数据载入寄存器计算但有些却不能。这主要由编译器的好坏决定。好的编译器可以利用优化器来弥补编程能力带来的性能不足。如果优化层级提高,程序中的错误也会蔓延滋生。但这并不是编译器的错。C语言的定义比较复杂。由于优化层级的提高,一个诸如缺少volatile限定符的操作就可能引人一些敏感的错误。对于这些错误,自动测试脚本以及连续地对非优化的版本进行测试可以有效地保证程序的正确性。
另外,优化编译器的供应商并不是每次都采纳最好的解决方案。如果编译器的供应商在测试一个优化解决方案时只有1%的程序无法通过,那么这个方案很可能会因为所产生的支持的问题而不被采纳。
GPU的计算能力超过内存带宽容量的好几倍。在费米型架构的硬件上,存储带宽最高能达到190GB/s,而计算能力最快能达到每秒执行超过一万亿次浮点运算,这比五倍的内存带宽还要多。在开普勒GTX680及TeslaK10上,计算能力提高到了3万亿次浮点运算,而内存带宽与GTX580几乎相同。在比特包装这个例子中,如果不用寄存器进行优化,而改用一个没有缓存的设备,每次循环迭代都需要进行一次读操作和一次写操作。每个整型数或浮点数的长度为4个字节,一次读写一共是8个字节,理论上,这个例子能达到的最好性能是1/8的内存带宽。如果内存带宽是190GB/s,则相当于每秒做了250亿次操作。
但实际情况中是不可能达到这么高的性能,因为原始的存储带宽也要考虑循环索引以及迭代。然而,这种快速而无须精细的计算方式可以让我们在编程之前估计出应用程序性能的上限。
理论上,采用这种减少31次内存操作的方式可以使程序的性能提高31倍,每秒执行7750亿次迭代操作。但在实际设备中执行时却会受到限制。尽管这样,相比于使用全局内存,通过寄存器的累加尽可能使用寄存器还是能使程序的性能得到很大的改善。
此处,我们编写了一个程序,分别用全局内存和寄存器进行位包装,从而获得一些真实的数据。以下是测试的结果。

以下是两个内核函数的代码:
__global__ void test_gpu_register(u32 * const data, const u32 num_elements)
{
const u32 tid = (blockIdx.x * blockDim.x) + threadIdx.x;
if (tid < num_elements)
{
u32 d_tmp = 0;
for (int i = 0; i < KERNEL_LOOP; ++i)
{
d_tmp |= (packed_array[i] << i);
}
data[tid] = d_tmp;
}
}
__device__ static u32 d_tmp = 0;
__global__ void test_gpu_gmem(u32 *const data, const u32 num_elements)
{
const u32 tid = (blockIdx.x * blockDim.x) + threadIdx.x;
if (tid < num_elements)
{
for (int i = 0; i < KERNEL_LOOP; ++i)
{
d_tmp |= (packed_array[i] << i);
}
data[tid] = d_tmp;
}
}
这两个内核函数的唯一区别是一个使用全局变量d_tmp,另一个使用本地寄存器。表 6-3显示了加速的结果。由表可知,平均加速7.7倍。而最让人意外的是,最快的加速比出自SM数量最多的那个设备。这说明了一个问题,不知读者是否注意到。在使用全局内存的内核函数中,线程块中的每个线程读/写到d_tmp中,并没有保证按怎样的顺序执行,因此输出是不确定的。内核函数正常执行,没有检测到任何CUDA错误,但是程序的结果通常可能是没有意义的。这种类型的错误在将串行代码转换成并行代码时是非常常见的一种典型错误。
表6-3 使用寄存器与使用全局内存的加速比
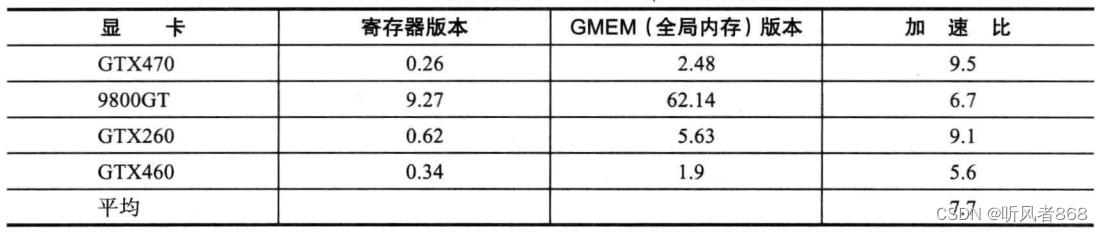
奇怪的答案告诉人们有些地方可能出错了。但该如何修改才正确呢?在寄存器版本的内核函数中,每个线程将结果写回唯一对应的寄存器。在GMEM(全局内存)版本的内核函数中,也应做相同操作。因此,只需将原先d_tmp的定义d_tmp:

现在每个线程都是对独立的一块内存区域进行读/写。现在加速比又是多少呢?参见表6-4。
表 6-4 使用寄存器与使用全局内存的实际加速比
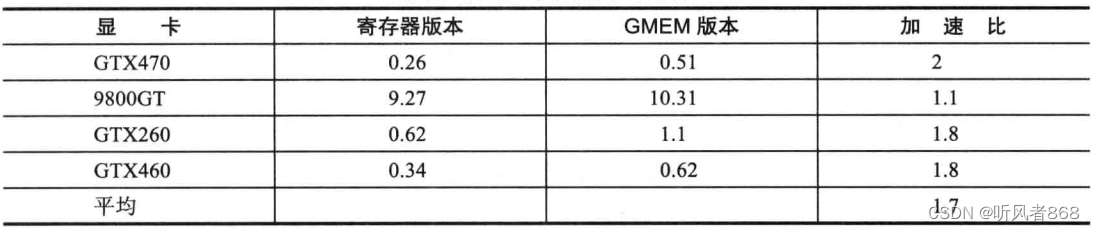
由表6-4可知,平均加速比降低到1.7倍。如果除去9800GT(计算能力为1.1的设备)这段简单代码的平均加速比接近两倍。因此,应尽量用其他方式避免全局内存的写操作。如果操作聚合到同一块内存上,如第一个例子,就会强制使硬件对内存的操作序列化,从而造成严重的性能降低。
现在,让一段代码运行得更快变得非常简单。循环一般非常低效,因为它们会产生分支,造成流水线停滞。更重要的是,它们消耗指令但并不是为了得出最终结果。循环的代码包含了循环计数器的增加、检测是否到了循环的终止状态以及每次迭代的一个分支判断。相比之下,每次迭代有用的指令是将值从packed_array中载入,向左移位N位,然后与当前的d_tmp做“或”操作。所有的操作中,循环的操作占了50%。我们可以通过査看PTX(Parallel Thread eXecution,并行线程执行)代码证实这一点。为了方便读者阅读这段虚拟汇编代码,高亮的代码即执行循环的代码。


这段 PTX 代码首先判断了for循环是否真正进入了循环。这一部分是在标注 $LDWbegin-block_180_5的代码块中执行的。标注$Lt_0_1794的代码块执行循环操作,当执行完 32 次迭代操作时跳转到标注$L_0_3330的代码块。标注$L_0_3330代码块执行的是下面这段代码;
d_tmp |= (packed_array[i] << i);
注意,除了循环的开销之外,packed_array用一个变量进行索引,因此每次循环都需要计算内存地址:

这非常的低效。相比于将循环展开,我们看到了一些更加有趣的东西:
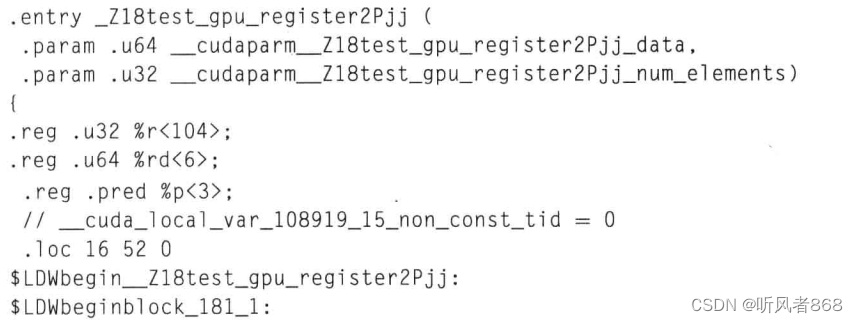
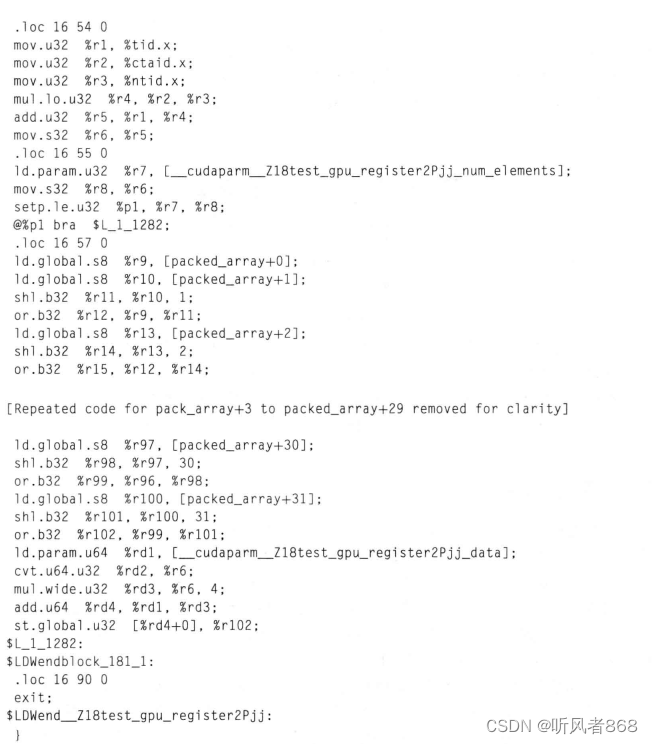
现在,几乎所有的指令都是为了计算得到结果,循环的开销没有了,无用指令减少了很多。packed array的地址计算也精简到一个编译时就分配的基地址加上偏移地址。所有计算都变简单了,但同时也变长了,无论是C代码还是虚拟PTX汇编代码。
这里,我们无须花费过多的时间来理解PTX代码,只需要知道C代码的一点小小的改动就会为虚拟汇编代码的生成代码带来很大的改变。了解诸如将循环展开的这种技巧会对今后编程有很大的帮助。在第9章中,本书将详细介绍PTX以及如何将其转换成机器能执行的实际代码。
表6-5显示了采用这种方式之后得到的加速比。由表可知,该方法在9800GT或GTX260上运行时,没有产生任何效果,但是,在计算能力为2x以上的硬件上运行时,例如GTX460与GTX470,加速比分别为2.4与3.4。与纯GMEM实现方案相比,GTX470执行得到的加速比为6.4。直观点说,如果原程序需要花6.5 小时来运行,优化之后只需要一个小时。
表 6-5 循环展开的影响
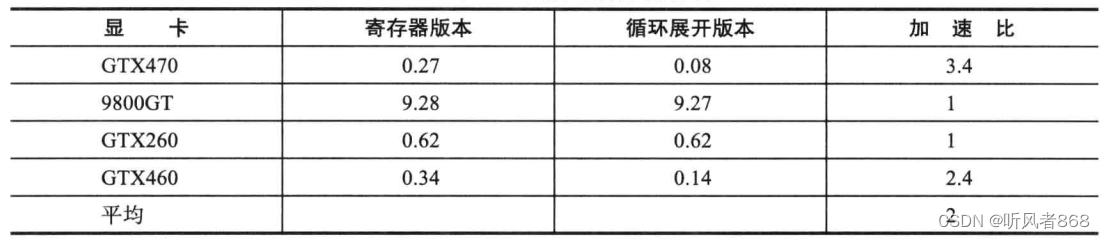
基于寄存器的优化能够为代码的执行时间带来巨大影响。读者可以利用节省的这段时间认真理解程序的内循环 PTX代码是如何生成的,学会将循环展开成单个的或一组表达式。如果学会这样去思考程序代码,程序的性能将会有质的飞跃。使用寄存器可以有效消除内存访问,或提供额外的ILP,以此实现 GPU内核函数的加速,这是最为有效的方法之一。
















 1859
1859











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











