







5.6 线程块的调度
假设现在有1024个线程块需要调度处理,但只有8个SM去调度它们。在费米架构的硬件上,当每个线程块中的线程数量并不多时,每个SM一次最多能接受8个线程块。当每个线程块中线程的数量比较合理时,一个SM一次一般能处理6~8个线程块。
现在,我们将这1024个线程块分配到6个SM中,平均每个SM需要处理170个线程块,还余4个需要处理。接下来我们将详细介绍余下的这4个线程块如何处理,因为它们的处理会带来一个比较有趣的问题。
像之前提到的那样,前1020个线程块被分配到SM中进行处理,那么它们是怎样分配的?硬件也许会分配6个线程块分配到第一个SM,然后紧接着的6个线程块分配到第二个SM,跟着第三个、第四个,依次类推。也有可能是硬件轮流为每个SM分配一个线程块,线程块0被分配到0号SM中,线程块1被分配到1号SM中,线程块2到2号SM中,依此类推。英伟达并没有公布他们到底是使用的哪种方式,但很有可能是后面一种,因为这种方式能让 SM 达到合理的负载平衡。
如果现在我们有19个线程块和4个SM,将所有的线程块都分配到一个SM上进行处理,显然不够合理。如果让前3个SM每个处理6个线程块,最后一个SM 处理一个线程块那么最后一个线程块就会很快处理完,然后SM 会闲置。这样做设备的利用率会很低。
如果我们用轮流交替的方式将线程块分配到SM中,每个SM处理4个线程块(4x4=16个线程块),还剩三个线程块单独用一个SM 再次处理,假设每个线程块执行所花费的时间是一样的,那么通过让每个SM能均衡地处理线程块,而不是像之前那样有的SM负载过重有的SM负载过轻,这样我们就可以减少17%的执行时间。
而在实际的程序中,我们往往会用到成千上万个线程块。在线程块调度者为每个SM初始化分配了线程块之后,就会处于闲置状态,直到有线程块执行完毕。当线程块执行完毕之后就会从 SM 中撤出,并释放其占用的资源。由于线程块都是相同的大小,因此一个线程块从SM 中撤出后另一个在等待队列中的线程块就会被调度执行。所有的线程块的执行顺序是随机、不确定的,因此,当我们在编写一个程序解决一个问题的时候,不要假定线程块的执行顺序,因为线程块根本就不会按照我们所想的顺序去执行。
当执行到一些相关联的操作时,我们会遇到一个很严重的问题。我们以浮点加法运算作为例子,而事实上,浮点加法运算并没有太多的相关联性。我们对一个浮点数组做加和运算,数组按照不同顺序做加和操作时得到的结果会不同。这主要是由舍人误差所引起的,而浮点运算必定会产生这种误差。但不论是什么顺序,最终的结果都是正确的。因此,这并不是一个并行执行的问题,而是一个顺序的问题。因为即便在CPU上用一个单线程的程序来运行,我们也会看到相同的问题。无论是在CPU还是GPU上,我们对一串随机的浮点数做加和运算,不论是从头加到尾,还是从尾加到头,我们都会得到不同的结果。甚至可能更糟的是,在GPU上,由于线程块的不确定调度,多次对相同的数据进行计算,每次得到的结果都不相同,但所有结果都是正确的。关于这种问题的解决办法,本书的后半部分将会有详细的介绍。到目前为止,我们只需要知道这样做得到的结果会不同,但没有必要认为这个结果是错的。
回到我们之前讨论的剩余线程块的处理的问题上。通常,线程块的数目并不是SM数目的整数倍。但由于制造更大、更复杂的处理器很困难,我们往往会看到CUDA的设备上搭载着奇数个SM。在处理器制造工艺中,硅的使用很广泛,但正是由于硅的使用的增加,也降低了其他领域相对再增加的可能性。同其他处理器的生产厂商一样,英伟达禁掉了有瑕疵的SM的使用,并将其作为低配置单元出售。这使得其生产量大大增加,从某种角度来说,这些有瑕疵的设备创造了经济价值。然而,对于程序员而言,这只意味着SM的总数不总是2的整数倍。当前费米480系列的显卡以及TeslaS2050、S2070、C2050、C2070系列的显卡均搭载16个SM,其中一个SM 不可用,即只有15个SM 可供使用。目前,580系列的显卡已经解决了这个问题,但是在未来的GPU中,这个问题还可能再度出现。
到目前为止,解决余下线程块的方法只有一个,那就是让我们的内核函数尽量长并且需要足够长的时间完成。例如,我们用一个有限的时间步长来进行模拟。假设在费米480系列的显卡上,我们有16个线程块需要处理,但现在一共只有15个SM可用,那么每个SM分配一个线程块,余下的一个线程块只在前 15个线程块中的某一个执行完毕之后再调度处理如果每次内核执行需要 10分钟,那么前15 个线程块几乎会同时完成计算,然后再调度余下的那个线程块,那么其他14个SM 闲置,因此我们还需要等待10分钟整个内核函数的调用才会结束。相对于将16个线程块划分成几个大块,这种划分成若干小块的解决方案则提供了更好的间隔尺寸。
当运行环境是服务器环境时,此时就不止15个SM可供我们使用。在用GPU搭建的服务器环境中,往往都会有多块 GPU。此时,如果我们的任务仅仅是执行刚刚的内核函数,那么将会有很多SM 处于闲置状态直至该内核函数结束调用。在这种情况下,我们最好重新设计内核函数,以保证在每个GPU中,线程块的数目都是SM数目的整数倍,以此提高设备的利用率。
其实从负载平衡的角度来看,这个问题还有待优化。因此,在之后的CUDA运行时库中支持重叠的内核以及在同一块CUDA设备上可以运行多个单独的内核。通过这种方法,我们就可以维持吞吐量,使GPU集群不止有一任务源可以调度。一旦设备出现闲置,它就会从内核流中选择另一个内核进行执行。
5.7 一个实例--统计直方图
在编程中,我们可能经常遇到统计直方图,利用统计直方图,我们可以得到某些类或者某些数据出现的频数,从而得到它们的分布情况。假设统计某些数字出现的次数,我们用一个bin 数组与这些数字相关联,保存它们出现的次数,如果某个数出现一次,那么相对应的bin 就加 1。
在这个简单例子中,我们用256个bin来统计数字0~255出现的次数。我们只需要遍历一个字节数组,这个数组里面的值只占一个字节,如果数组里面的值为0,那么bin[0]就加1,如果是10,那么bin[10]就加1。我们将这个数组称作输入数组。
用串行算法解决的代码非常简单,如下所示:

这里,我们通过索引i来遍历整个输入数组,用++运算符来对相应的bin进行累加操作。
当将这段串行代码转化成并行的时候,我们会遇到一个问题。如果我们用 256个线程来执行,若多个线程同时对同一个bin进行加1操作,将出现竞争的情况。
如果你知道C语言是如何转化成汇编指令的,那么你就会知道这段代码在汇编下会如何执行。细分下来,主要有这样几步操作:
1) 从输人数组中读取数据到寄存器:
2) 计算出这个数对应的bin的基地址与偏移量;
3) 获取当前这个数对应的 bin的值:
4) 对 bin 值进行加 1;
5) 将新的 bin 值写回内存。
问题主要出现在步骤3、4、5,因为它们没有进行原子操作。所谓的原子操作,就是当某个线程对某项数据进行修改的时候,其他优先级比较低的线程无法打断它的操作,直至该线程完成对该数据的所有操作。由于CUDA采用的是多线程并行模式,如果我们以锁步的方式执行这段伪码就会遇到一个问题。两个或两个以上的线程在步骤3获取了相同的值,接着进行加1操作,然后将新的数据再写回内存。这时,最后做写操作的那个线程写人的数据才是最终的值。这肯定是不对的,因为本来一共加了N,可最后只加了1,数据值错误的少了N-1。
数据的相关性造成了这个问题的产生,而在用顺序执行的代码中我们根本看不到这个问题。bin 在线程之间是以共享资源的形式存在,因此,在某个线程读取和修改 bin 值之前,必须等上一个线程完成对 bin 的操作才行。
这个问题在日常编程中并不少见,CUDA针对此也提供了一个较为简单的方法:
![]()
这个操作保证了对 value 这个值进行的加法操作在所有线程之间是串行执行的。
既然问题得到了解决,那么我们就来考虑该用什么样的方式将之前的串行代码转化成在线程、线程块及线程网格上运行的并行代码。主要有两种方式,一种是基于任务分解的模型,一种则是基于数据分解的模型。当然,两种方案都需要考虑。
基于任务分解的模型主要是将输人数组中的元素分配到每一个线程中,然后再进行原子加法操作。这种方法对于程序来说是最简单的解决方案,但同时也有一定缺点,因为有些数据是共享资源。假设现在有256个bin,而输入数组有1024个元素,假定这256个bin所统计的信息是平均分布的,并且每个bin最后统计出的结果都为4,那在计算每个bin的时候就会产生4次竞争。如果输入数组更大(因为CUDA本身就是用来解决大数据问题的)那产生的竞争也就更多,执行的时间也就更长。也就是说,输入数组的大小决定了程序运行的总时间。
如果直方图中所统计的信息都是平均分布的,那么每个bin产生竞争的次数就等于输人数组的大小除以所统计的信息种类数,即bin的数目。假设输入数组的大小为512MB(524 288 个元素),一共统计了4类信息,那么每个bin就会有131072个元素进行竞争。最糟糕的是,如果输人数组中所有元素都对应同一个 bin,由于通过原子操作对这个 bin 进行内存读写,因此我们的并行程序也就完全变成了一个串行程序。
不论是刚刚所说的哪种情况,程序执行的时间都受到硬件处理竞争的能力以及读/写内存带宽的影响。
下面是多线程采用任务分解模型的具体实现。以下是GPU程序代码:
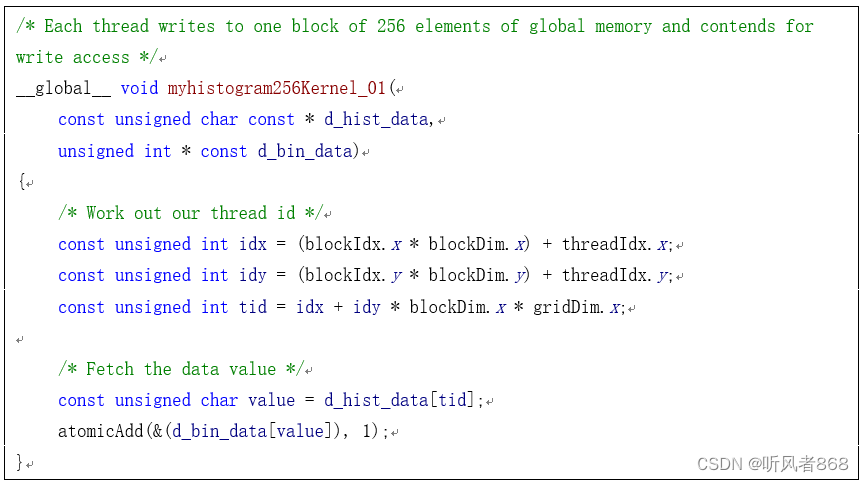
我们用一块 GTX460显卡对这种方法进行测试,测得其处理速度为1025MB/S。很有趣的是,该方法的处理速度并不随输人数组的大小改变而加快或降低。无论输入数组的大小是多少,都会得到一个固定的速度值,而且这个速度值非常慢。对于显存为1GB的GTX460显卡而言,它的存储带宽为115GB/s,而我们测得的处理速度为1025MB/s,可想而知,采取这种简单幼稚的方案获取的性能是多么低。
虽然这个处理速度非常低,但它同时也说明这是由于某些因素的限制而造成,因此,我们要找出这些影响性能的因素并且消除它们。在该程序中,其中一个最可能影响性能的因素就是存储带宽。在程序中,一共有两次对内存的读/写操作,先是每次从输人数组中获取N个数然后又压缩至N次写回到一块1K的内存区(256个元素x每个数4个字节)。
首先我们来讨论一下读操作。每个线程从输人数组中读得一个字节的元素,但由于线程束的读操作合并到了一起,即每半个线程束(16个线程)同时做一次读操作,由于最少的传输大小为32字节,但现在只读了16个字节,因此浪费了50%的存储带宽,性能很低。在最好的情况下,每半个线程束最多能读128个字节,如果是这样,每个线程将从内存中获得4个字节的数据,即可以通过处理4个统计直方图的条目,而不是先前的一个来完成。
现在,我们来看如何每次读4个字节的数据然后进行统计计算。我们可以按照读整型数的方式每次读取一个4字节的数据,然后将这个整型数拆分成4个字节来进行计算,如图5-14所示。理论上这提供了一种更好的合并读的方式并确实能让我们的程序获得比之前更好的性能。以下是修改后的内核代码:
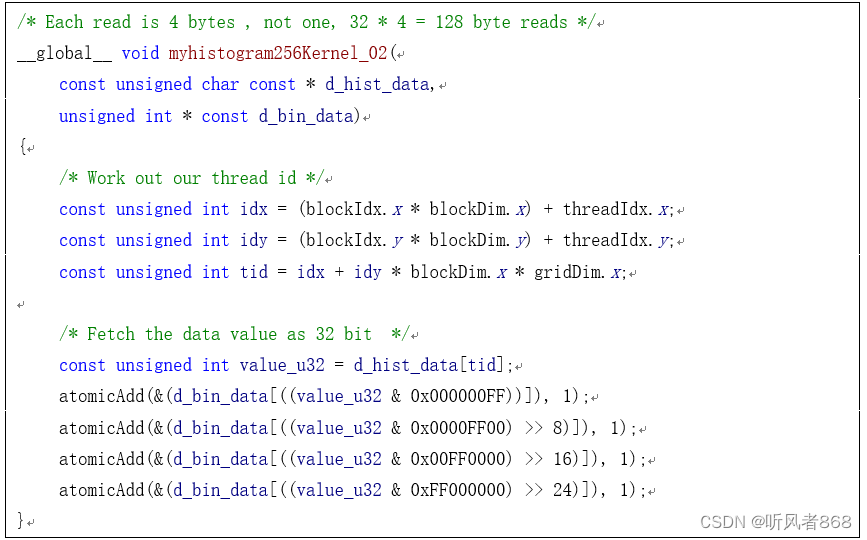
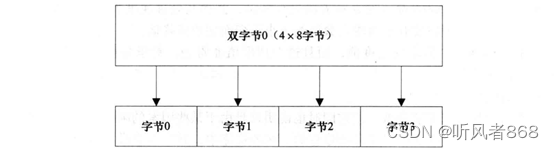
图5-14字与字节的映射关系
但在运行内核时我们会发现,我们所做的努力只实现了零加速。事实上,这种现象在我们优化程序的时候会经常发生,原因主要是我们还没真正弄清楚引起性能瓶颈的因素。
为什么我们做出了努力可是程序还是没有得到优化呢?原因主要是内核是在计算能力为2.x的硬件上运行的。半个线程束合并读取内存数据的方式对计算能力为 2.x的硬件来说并不会产生很大影响,因为它已经将整个线程束的内存读取都合并到一起了。也就是说,在测试设备GTX460上(计算能力为2.1的硬件),来自一个线程束的32次单字节读取被合并为一次32字节的读操作。
很明显,相对于存储带宽带来的微小影响,原子写操作才可能是性能瓶颈的罪魁祸首。为此,我们将采用另外一种方案来编写内核,即基于数据分解的模型。通过观察我们会发现内核中有一些数据会被再次用到,而我们可以将这些被再次利用的数据放入能高效处理共享数据的存储区中,例如二级缓存和共享内存,以此来提高程序的性能。
我们知道最初引起程序性能低下的原因就是对 256个bin所产生的竞争。多个SM 中多个线程块都要将它们的计算结果写回内存,然后硬件对每个处理器的缓存中的bin数组进行同步。分开来看,就是程序从内存中获取数据,然后做加法操作,最后将计算得到的新值写回内存。而这其中,有好几步操作都可以一直在二级缓存中进行。在费米型架构的硬件上二级缓存中的数据在SM之间是共享的。相比之下,如果在计算能力为1.x的硬件上,如果将数据都放在全局内存上进行读写操作,程序的性能会降低好几个数量级。
但即使在费米架构的硬件上使用了二级缓存,我们仍需对所有的SM 进行同步。另外由于我们执行的写操作是一种比较分散的模式,它依赖于直方图输入数据的分布特性,有时数据的分布非常分散,造成写操作没法合并,从而严重影响程序的性能。
另一种方案就是让每一个SM都计算出一个统计直方图,最后再将所有的直方图汇总到一块主内存上。无论是CPU编程还是GPU编程,我们都要尽量去实现这种方案。因为利用的资源越接近处理器(例如SM),程序就会运行得越快。
之前我们提到使用共享内存。共享内存是一块比较特殊的内存,因为它存在于芯片上并且它的存取比全局内存更快。我们可以在共享内存上创建一个包含256个bin的局部统计直方图,最后将所有共享内存上计算得到的统计直方图通过原子操作汇总到全局内存。假设每个线程块处理一个统计直方图,而对全局内存读写的操作次数也不会因此而减少,但写回内存的操作却因此可以合并起来。以下是这种方法的内核代码:
__shared__ unsigned int d_bin_data_shared[256];
/* Each read is 4 bytes, not one, 32 * 4 = 128 byte reads */
__global__ void myhistogram256Kernel_03(
const unsigned int const * d_hist_data,
unsigned int * const d_bin_data)
{
/* work out our thread id */
const unsigned int idx = (blockIdx.x * blockDim.x) + threadIdx.x;
const unsigned int idy = (blockIdx.y * blockDim.y) + threadIdx.y;
const unsigned int tid = idx + idy * blockDim.x * gridDim.x;
/* Clear shared memory */
d_bin_data_shared[threadIdx.x] = 0;
/* Fetch the data value as 32 bit */
const unsigned int value_u32 = d_hist_data[tid];
/* Wait for all threads to update shared memory */
__syncthreads();
atomicAdd(&(d_bin_data_shared[((value_u32 & 0x000000FF))]), 1);
atomicAdd(&(d_bin_data_shared[((value_u32 & 0x0000FF00) >> 8)]), 1);
atomicAdd(&(d_bin_data_shared[((value_u32 & 0x00FF0000) >> 16)]), 1);
atomicAdd(&(d_bin_data_shared[((value_u32 & 0xFF000000) >> 24)]), 1);
/* Wait for all threads to update shared memory */
__syncthreads();
/* The write the accumulated data back to global memory in blocks, not scattered */
atomicAdd(&(d_bin_data[threadIdx.x]), d_bin_data_shared[threadIdx.x]);
}
内核必须针对共享内存做一次额外的清除操作,以免之前执行的内核随机残留一些数据。此外,在将下一个线程块中所有线程的数据更新到共享内存单元之前,必须等待(_Syncthreads)前一个线程块的所有线程完成共享内存单元的清除操作。最后,在将结果写回到全局内存之前,也需要设置一个同步操作,以保证所有的线程都完成了计算。
此时,通过将连续的写操作合并,我们程序的性能立刻就提升了6倍,处理速度达到6800MB/s。但请注意,必须在计算能力为1.2或者更高,并且支持共享内存原子操作的设备上执行这段代码才能获得如此高的处理速度。
将连续的写操作合并起来之后,我们需要考虑一下如何减少全局内存的阻塞。我们已经对读数据的大小进行了优化,每次从源数据中读出一个值,而且每个值只需要读一次,因此,我们只需要考虑减少对全局内存写操作的次数了。假设每个线程块处理的直方图不是一个而是N个,那么我们对全局内存的写操作的带宽就会减少N倍。
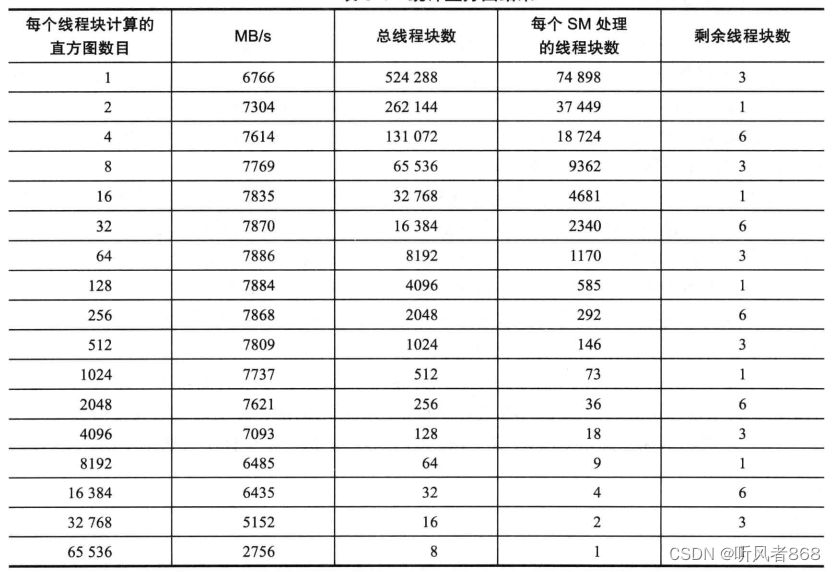
表5-4显示了在费米460显卡(包含7个SM)上,对数据总量为512M的统计直方图进行处理,当N值不同时,获得不同的处理速度。其中,当N为64时得到最高的处理速度7886MB/s。以下是内核代码:
/* Each read is 4 bytes, not one, 32 * 4 = 128 byte reads */
/* Accumulate into shared memory N times */
__global__ void myhistogram256Kernel_07(
const unsigned int const * d_hist_data,
unsigned int * const d_bin_data,
unsigned int N)
{
/* work out our thread id */
const unsigned int idx = (blockIdx.x * blockDim.x * N) + threadIdx.x;
const unsigned int idy = (blockIdx.y * blockDim.y) + threadIdx.y;
const unsigned int tid = idx + idy * (blockDim.x * N) * gridDim.x;
/* Clear shared memory */
d_bin_data_shared[threadIdx.x] = 0;
/* Wait for all threads to update shared memory */
__syncthreads();
for(unsigned int i = 0, tid_offset = 0; i < N; ++i,tid_offset += 256)
{
const unsigned int value_u32 = d_hist_data[tid + tid_offset];
atomicAdd(&(d_bin_data_shared[((value_u32 & 0x000000FF))]), 1);
atomicAdd(&(d_bin_data_shared[((value_u32 & 0x0000FF00) >> 8)]), 1);
atomicAdd(&(d_bin_data_shared[((value_u32 & 0x00FF0000) >> 16)]), 1);
atomicAdd(&(d_bin_data_shared[((value_u32 & 0xFF000000) >> 24)]), 1);
}
/* Wait for all threads to update shared memory */
__syncthreads();
/* The write the accumulated data back to global memory in blocks, not scattered */
atomicAdd(&(d_bin_data[threadIdx.x]), d_bin_data_shared[threadIdx.x]);
}
表 5-4 统计直方图结果
现在,我们来看看这段代码究竟做了什么。首先,我们用一个循环变量i进行了N次循环,每次循环我们都处理了在共享内存中的256个字节的直方图数据。每个线程块包含256个线程,每个线程计算一个bin。而循环的次数即每个线程块处理的直方图的个数。每执行完一次循环,指向内存的指针向后移动256个字节(tid_offset += 256),以指向下一个处理的直方图。
由于自始至终我们都使用了原子操作,因此我们只需要在内核计算的开始与结尾处进行同步操作。不必要的同步会降低程序的性能,但同时也能让内存的访问变得更加整齐统一。
通过观察表,我们可以发现一个很有趣的现象。当每个线程块处理的直方图的数目为32或者更多的时候,我们看到吞吐量没有明显的增加。N值每增加两倍,全局内存的带宽反而在降低。因此,如果全局内存带宽是问题的所在,那么处理速度应该随着N值的增长而线性增长。那么,究竟什么才是真正影响性能的因素呢?
其实,真正的主要因素还是原子操作。每个线程都要同其他线程一同对一块共享数据区进行竞争,又由于数据模式设计的并不好,因此,对执行中的时间有了很大的影响。
在之后的章节中,我们将会采用不使用原子操作的方式来实现该算法。
5.8 本章小结
本章中我们讲到了许多关于线程、线程块以及线程网格的知识。现在你应该熟悉了如何利用CUDA将任务分解到线程网格、线程块及线程上。此外,本章还涉及了硬件上的线程束的概念以及线程块的调度问题,以及时刻保证硬件上有足够数量的线程的需要。
了解 CUDA的线程模型是 GPU 编程的基础。我们要清楚 GPU 编程与 CPU 编程的根本不同,同时也要清楚它们之间的相互联系。
在本章中,根据待处理数据来组织线程结构是非常重要的,它对程序性能的影响非常大。另外,尤其是当应用程序需要共享数据时,将一个简单的任务并行化处理并不是一个简单的工作。我们要时刻想寻找一个更好的方案,而不只是寻找一个适合的方案。
此外,本章中我们还谈到了关于原子操作的使用以及原子操作带来的序列化执行问题。另外还有分支结构带来的问题,要牢记保证所有线程遵循相同控制路径的重要性。本书后面
的章节中还会对原子操作与分支进行详细的讨论。
在本章CUDA内核代码中用到一些C语言的扩展语法,本书后面章节中还会出现这样的语法,读者应学会在自己的CUDA程序中也采用这样的语法,并明确知道其具体含义。
读完这章相信你已经对CUDA有了深刻的了解与认识,希望你不会再对CUDA或并行编程感到神秘。
问题
1.在本章所描述的直方图统计算法中,找出数据分布最好与最坏的模式。普通分布情况中有哪些也是有问题的?你将如何解决?
2.如果不使用算法,在基于G80系列的硬件上进行测试,你认为影响性能的最主要的因素是什么?
3.如果对一个在 CPU内存上的数组进行处理,是采用行-列顺序执行的方式好还是采
用列-行顺序执行的方式好?如果是在GPU上,会有什么不同吗?
4.假设现在有一段代码分别使用不同数量的线程块进行执行,一种使用了4个线程块每个线程块包含 256个线程,另一种使用了1个线程块,这个线程块中包含1024个线程请问哪个内核先执行完,为什么?每个线程块在代码中的不同位置调用syncthreads()进行了
4 次同步。线程块之间相互不影响。
5.GPU 上基于 SIMD的实现模式与多核 CPU上基于 MIMD 的实现模式各有什么优点与缺点?
答案
1.当统计的数据均匀分布时是最好的情形。因为这种分布使得任务与数据平均分配,对共享内存存储片进行原子操作的次数也是非常平均的。
最坏的情况则是统计的数据全部是同一个值。这使得所有的线程都竞争同一块共享数据,原子操作与共享内存存储冲突使整个程序变成了串行的。
不幸的是,一种常见的用法是使用已排序的数据,这种情况非常糟糕,某几个共享数据可能会遇到连续大量的原子写操作,也使程序成为串行化。
一种解决办法是对数据集进行轮询访问,每次迭代时将数据写人一个新容器内。但这种方法需要我们了解数据的分布。例如,用32个容器对256个数据点进行一个线性函数的建模。假定数据点0~31进入第一个容器,之后每一个容器都依此类推。每个容器处理一个值,这样就可以将写操作分布到每个容器中,从而避免竞争。在这个例子中,读数据应按这种方式:0,32,64,96,1,33,65,97,2,34,68,98…
2.由于G80设备(计算能力为1.0或1.1)不支持基于共享内存的原子操作,因此代码无法编译通过。假设我们采用全局内存的原子操作对其进行修改,那么相比之前基于共享内存的原子操作方案,这种方案得到的性能将降低7倍。
3.以行-列的顺序执行方式更好,因为CPU会使用一种“预取”的技术,它可以使后续待读取的数据被同时取到缓存中,最终整个缓存行中会装满从内存获取的数据。也就是说,CPU 在获取数据时会按行获取。
采用列-行的方式可能会慢一点。采用先列遍历的方式可能会慢很多。因为CPU从内存获取的一个缓存行数据不太可能被后面的循环迭代用到,除非每一行的数据并不多。在GPU上,每个线程会取出每一行的一个或多个数据元素。因此,从一个比较高的层面来讲整个循环应该采用列顺序的方式来执行,因为每一行获取的数据会被其他的线程立即处理掉。同CPU的缓存行一样,在计算能力为2.x的硬件上也能通过预取的方式将数据取出到缓存行,但有一点不同的是,取出的数据会立即被线程消费掉。
4.当执行 syncthreadsO)进行同步操作时,整个线程块将被阻塞直到线程块内所有的线程都到达了同步点。当到达同步点之后所有的线程才能再次被调度。让一个线程块拥有非常多的线程意味着当SM 在等待单个线程块内的线程到达同步点时可能会出现没有线程束可供调度的情况。由于线程的执行流是未知的,部分线程可能很快地到达同步点,而有的则需要很久才能到达。产生这种现象,主要因为硬件层的设计是针对获取更高吞吐量而不是针对减少延迟。因此,只有当块与块之间不需要通过全局内存进行通信,块内的线程经常通信的时候,一个线程块开启很多线程才能充分发挥性能。
5.由于每个执行单元的指令流都是相同的,SIMD模式将指令的获取时间均摊到每一个执行单元。但是,当指令流出现分支,指令就会被序列化。而MIMD模式的设计主要是为了处理不同指令流,当指令流出现分支,它不需要对线程进行阻塞。然而它需要更多指令存储以及译码单元,这就意味着硬件需要更多的硅,同时,为了维持多个单独的指令序列,它对指令带宽的需求也非常的高。
一般使用SIMD与MIMD的混合模式才是最好的方案。用MIMD的模式处理控制流,用SIMD的模式处理大数据。在CPU上使用SSE/MME/AVX指令扩展集时就是采用的SIMD与MIMD的混合模式,而在GPU上,当线程束与线程块以高粒度处理分支情况时也是采用的混合模式。
















 1166
1166











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











