






简介
Transformer 模型由编码器(Encoder)和解码器(Decoder)两部分组成。这里我会着重描述解码器的结构以及在预训练、输入输出和预测时的输入输出。
解码器结构:
-
自注意力层(Self-Attention Layers):与编码器类似,解码器也包含多个自注意力层,用于在解码器端对输出序列的不同位置进行关注,解码器中的自注意力层被修改为接受一个遮盖(masking)向量,以便在计算注意力权重时将未来的信息屏蔽掉,只关注当前位置之前的信息。。
-
编码器-解码器注意力层(Encoder-Decoder Attention Layers):除了自注意力层外,解码器还包含编码器-解码器注意力层,用于将编码器端的信息与解码器端的信息进行交互,帮助解码器更好地理解输入序列。
-
前馈神经网络(Feed-Forward Neural Networks):与编码器一样,解码器也包含前馈神经网络层,用于对特征进行映射和转换。
-
位置编码(Positional Encoding):解码器也需要位置编码来将位置信息融入模型中,以便模型能够理解输入序列的顺序信息。
Decoder在预训练、输入输出和预测时的输入输出:
-
预训练:
- 输入:在预训练期间,解码器的输入通常是由目标序列(target sequence)以及可选的编码器端输出的上下文信息组成。这些输入经过嵌入(embedding)和位置编码后,被送入解码器中。
- 输出:解码器预训练的目标是生成目标序列的下一个词的概率分布。因此,在每个时间步,解码器会生成一个预测概率分布,以便训练模型。
-
输入输出:
- 输入:在进行输入输出(Inference)时,解码器的输入通常是由上一个时间步生成的词以及编码器端的上下文信息组成。这些输入通过嵌入和位置编码后,传递给解码器。
- 输出:解码器在每个时间步生成的输出通常是一个概率分布,用于预测下一个词的概率。根据应用场景,可以使用不同的策略(如贪婪搜索、束搜索等)来选择最终的输出序列。
-
预测:
- 输入:在预测阶段,解码器的输入通常是由起始符号(如)以及编码器端的上下文信息组成。这些输入经过嵌入和位置编码后,传递给解码器。
- 输出:解码器生成的输出是一个概率分布,用于预测下一个词的概率。根据应用需求,可以根据生成的概率分布采样得到最终的预测结果。
结构
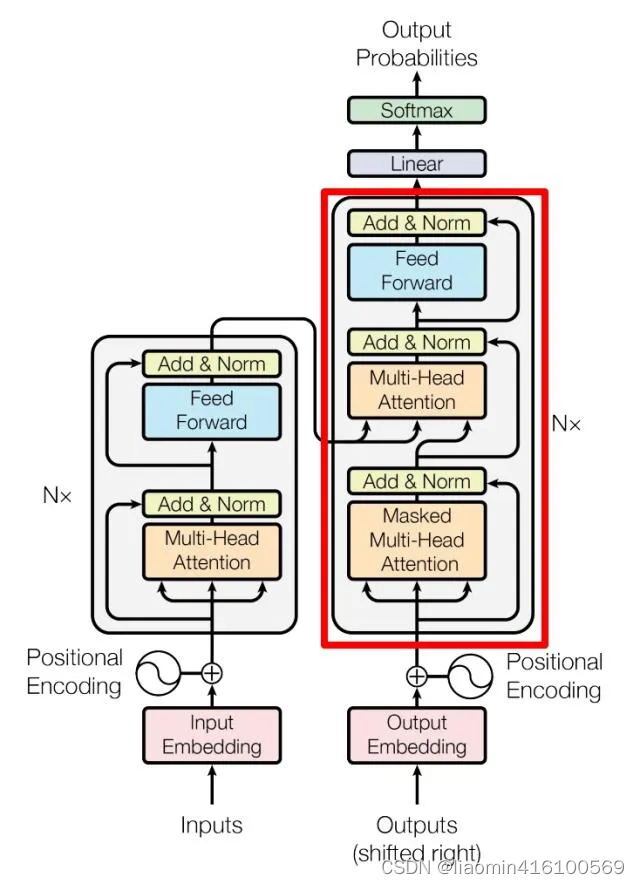
上图红色部分为 Transformer 的 Decoder block 结构,与 Encoder block 相似,但是存在一些区别:
- 包含两个 Multi-Head Attention 层。
- 第一个 Multi-Head Attention 层采用了 Masked 操作。
- 第二个 Multi-Head Attention 层的K, V矩阵使用 Encoder 的编码信息矩阵C进行计算,而Q使用上一个 Decoder block 的输出计算。
- 最后有一个 Softmax 层计算下一个翻译单词的概率。
先理解:自注意力的计算过程
原理
第一个 Multi-Head Attention
Decoder block 的第一个 Multi-Head Attention 采用了 Masked 操作,因为在翻译的过程中是顺序翻译的,即翻译完第 i 个单词,才可以翻译第 i+1 个单词。通过 Masked 操作可以防止第 i 个单词知道 i+1 个单词之后的信息。下面以 “我有一只猫” 翻译成 “I have a cat” 为例,了解一下 Masked 操作。
下面的描述中使用了类似 Teacher Forcing 的概念,不熟悉 Teacher Forcing 的童鞋可以参考以下上一篇文章Seq2Seq 模型详解。在 Decoder 的时候,是需要根据之前的翻译,求解当前最有可能的翻译,如下图所示。首先根据输入 “” 预测出第一个单词为 “I”,然后根据输入 “ I” 预测下一个单词 “have”。

Decoder 可以在训练的过程中使用 Teacher Forcing 并且并行化训练,即将正确的单词序列 ( I have a cat) 和对应输出 (I have a cat ) 传递到 Decoder。那么在预测第 i 个输出时,就要将第 i+1 之后的单词掩盖住,注意 Mask 操作是在 Self-Attention 的 Softmax 之前使用的,下面用 0 1 2 3 4 5 分别表示 “ I have a cat ”。
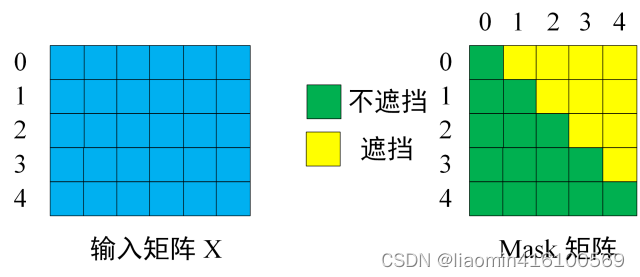
第一步:是 Decoder 的输入矩阵和 Mask 矩阵,输入矩阵包含 “ I have a cat” (0, 1, 2, 3, 4) 五个单词的表示向量,Mask 是一个 5×5 的矩阵。在 Mask 可以发现单词 0 只能使用单词 0 的信息,而单词 1 可以使用单词 0, 1 的信息,即只能使用之前的信息。
第二步:接下来的操作和之前的 Self-Attention 一样,通过输入矩阵X计算得到Q,K,V矩阵。然后计算Q和
K
T
K^T
KT的乘积
Q
K
T
QK^T
QKT
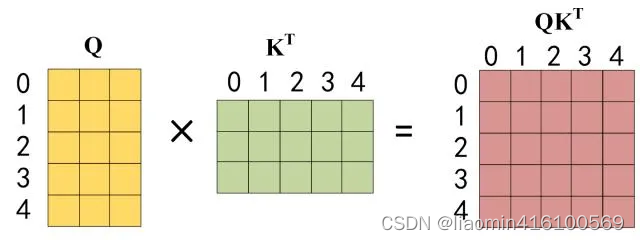
第三步:在得到
Q
K
T
QK^T
QKT之后需要进行 Softmax,计算 attention score,我们在 Softmax 之前需要使用Mask矩阵遮挡住每一个单词之后的信息,遮挡操作如下:
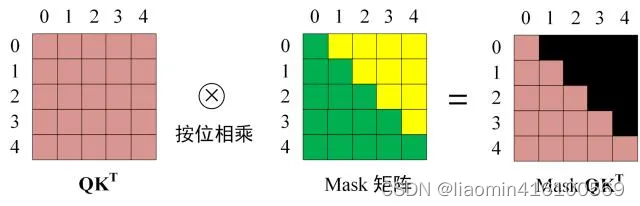
得到 Mask
Q
K
T
QK^T
QKT之后在 Mask
Q
K
T
QK^T
QKT上进行 Softmax,每一行的和都为 1。但是单词 0 在单词 1, 2, 3, 4 上的 attention score 都为 0。
第四步:使用 Mask
Q
K
T
QK^T
QKT与矩阵 V相乘,得到输出 Z,则单词 1 的输出向量
Z
1
Z_1
Z1是只包含单词 1 信息的。
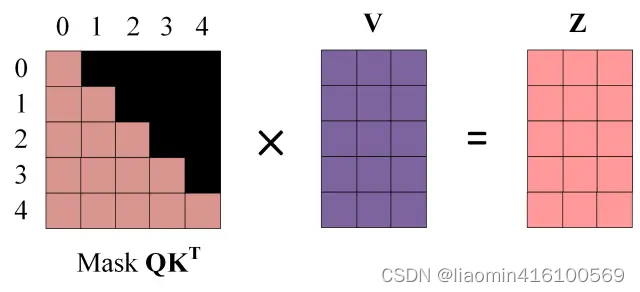
第五步:通过上述步骤就可以得到一个 Mask Self-Attention 的输出矩阵
Z
i
Z_i
Zi,然后和 Encoder 类似,通过 Multi-Head Attention 拼接多个输出
Z
i
Z_i
Zi然后计算得到第一个 Multi-Head Attention 的输出Z,Z与输入X维度一样。
第二个 Multi-Head Attention
Decoder block 第二个 Multi-Head Attention 变化不大, 主要的区别在于其中 Self-Attention 的 K, V矩阵不是使用 上一个 Decoder block 的输出计算的,而是使用 Encoder 的编码信息矩阵 C 计算的。
根据 Encoder 的输出 C计算得到 K, V,根据上一个 Decoder block 的输出 Z 计算 Q (如果是第一个 Decoder block 则使用输入矩阵 X 进行计算),后续的计算方法与之前描述的一致。
这样做的好处是在 Decoder 的时候,每一位单词都可以利用到 Encoder 所有单词的信息 (这些信息无需 Mask)。
什么使用Encoder计算k,v decoder计算Q
在 Transformer 模型的解码器中,使用了编码器的键(key)和值(value),而使用解码器的查询(query)。这种结构是为了充分利用编码器端对输入序列的理解,同时使得解码器端能够更好地根据自身生成的部分序列来做出决策。这种设计的物理意义可以从以下几个方面来理解:
-
利用编码器的上下文信息:编码器对输入序列进行编码,生成了对输入序列全局理解的表示。因此,使用编码器的键和值可以提供丰富的上下文信息,帮助解码器更好地理解输入序列。
-
解码器的自注意力:解码器的自注意力机制中,查询用于计算注意力权重,而键和值则用于构建注意力分布。使用解码器的查询意味着模型在计算注意力时更关注当前正在生成的部分序列,这有助于确保生成的序列在语法和语义上的连贯性。
-
解耦编码器和解码器:使用不同的键、值和查询将编码器和解码器的功能分开,使得模型更具灵活性和泛化能力。解码器可以独立地根据当前正在生成的序列来调整自己的注意力,而不受编码器端信息的限制。
总之,通过在解码器中使用编码器的键和值,以及使用解码器的查询,Transformer 模型能够更好地利用编码器端对输入序列的理解,并在解码器端根据当前正在生成的序列来做出决策,从而提高了生成序列的质量和连贯性。
Softmax 预测输出单词
Decoder block 最后的部分是利用 Softmax 预测下一个单词,在之前的网络层我们可以得到一个最终的输出 Z,因为 Mask 的存在,使得单词 0 的输出 Z0 只包含单词 0 的信息,如下:
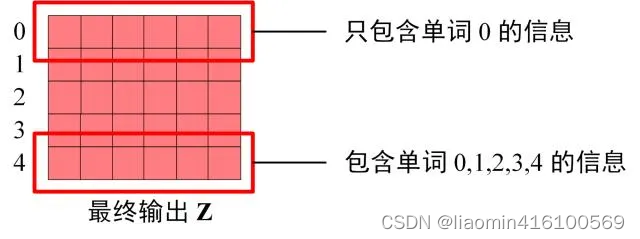
Softmax 根据输出矩阵的每一行预测下一个单词:
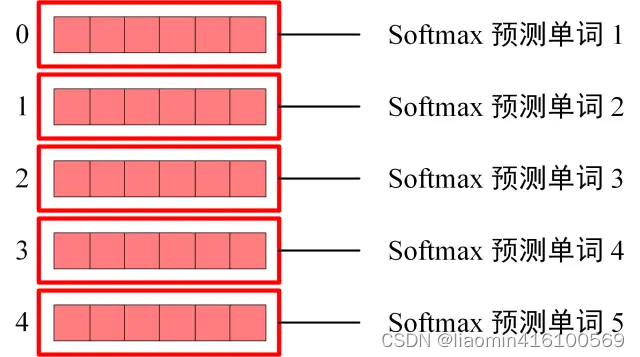
这就是 Decoder block 的定义,与 Encoder 一样,Decoder 是由多个 Decoder block 组合而成。















 1976
1976











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









