







 本文深入解析Transformer解码器,包括解码器输入、掩码多头注意力、TokenPrediction过程,以及如何利用编码器输出预测新Token,以自动生成文本。通过实例演示了Transformer在机器翻译任务中的应用。
本文深入解析Transformer解码器,包括解码器输入、掩码多头注意力、TokenPrediction过程,以及如何利用编码器输出预测新Token,以自动生成文本。通过实例演示了Transformer在机器翻译任务中的应用。
本系列文章致力于用最简单的语言讲解Transformer架构,帮助朋友们理解它的强大,本文是第七篇:Transformer解码器图文详解。
本系列之前的两篇文章:Transformer输入详解和Transformer自注意力机制图文详解,我们已经用图示和代码形式讲解了Transformer架构的编码器部分,接下来,我们开始讲解解码器部分。
01 解码器(Decoder)
到目前为止,通过前面的两篇文章,我们已经完成了编码器部分的所有计算步骤,从对数据集进行编码到通过前馈网络传递矩阵;接下来的步骤,我们将讲解Transformer的编码器,如下是在GPT中Transformer编码器预测Token的演示动图。

我们看一下到目前为止我们已经完成了哪些内容,以及我们还需要完成哪些内容:
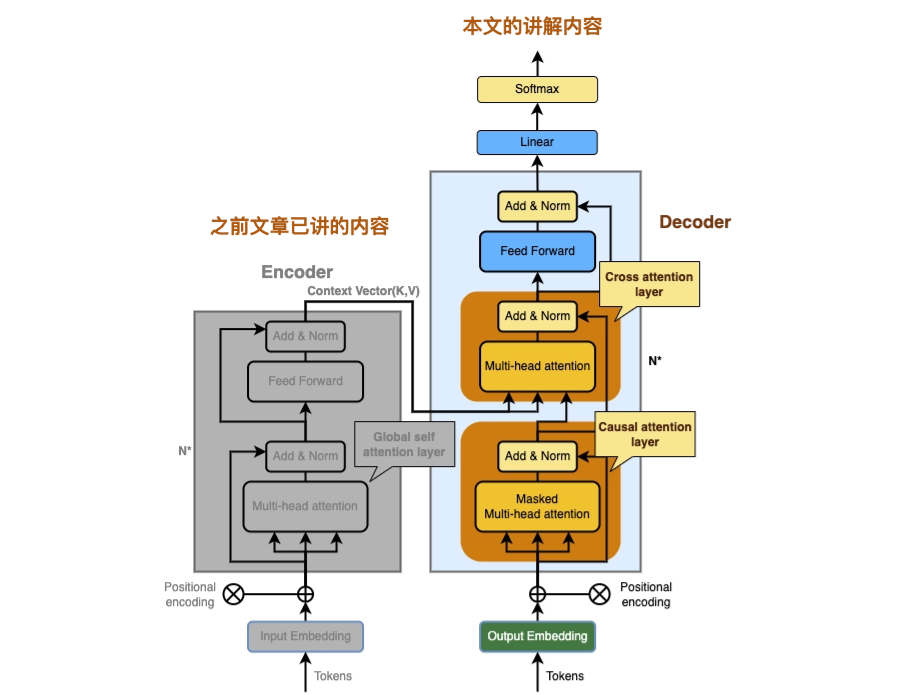
我们不会计算整个解码器,因为它的大部分已经在编码器中完成了类似的计算,详细计算解码器只会使文章变得冗长,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1474
1474

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









