








一、简介
Simple Online and Realtime Tracking(SORT) 是一个非常简单、有效、实用的多目标跟踪算法。在 SORT 中,仅仅通过 IOU 来进行匹配虽然速度非常快,但是 ID switch 依然非常大。
Deep SORT 算法,相比 SORT,通过集成表观信息来提升 SORT 的表现。通过这个扩展,模型能够更好地处理目标被长时间遮挡的情况,将 ID switch 指标降低了45%。
表观信息 也就是目标对应的特征,论文中通过在大型行人重识别数据集上训练得到的深度关联度量来提取表观特征(借用了ReID领域的模型)。
二、方法
2.1 状态估计
延续 SORT 算法使用 8 维的状态空间 ( u , v , r , h , x ˙ , y ˙ , r ˙ , h ˙ ) (u, v, r, h, \dot{x}, \dot{y}, \dot{r}, \dot{h}) (u,v,r,h,x˙,y˙,r˙,h˙),其中 ( u , v ) (u,v) (u,v) 代表 bbox 的中心点,宽高比 r r r, 高 h h h 以及对应的在图像坐标上的相对速度。
论文使用具有等速运动和线性观测模型的 标准卡尔曼滤波器,将以上 8 维状态作为物体状态的直接观测模型。
每一个轨迹,都计算当前帧距上次匹配成功帧的差值,代码中对应 time_since_update变量。该变量在卡尔曼滤波器 predict 的时候递增,在轨迹和 detection 关联的时候重置为 0。
超过最大年龄的轨迹被认为离开图片区域,将从轨迹集合中删除,被设置为删除状态。代码中对应的 max_age 默认值为70,是级联匹配中的循环次数。
如果 detection 没有和现有 track 匹配上的,那么将对这个 detection 进行初始化,转变为新的 Track。新的 Track 初始化的时候的状态是未确定态,只有满足连续三帧都成功匹配,才能将未确定态转化为确定态。
如果处于未确定态的 Track 没有在 n_init 帧中匹配上 detection,将变为删除态,从轨迹集合中删除。

2.2 匹配问题
Assignment Problem 指匹配问题,在这里主要是匹配轨迹 Track 和观测结果 Detection。这种匹配问题经常是使用 匈牙利算法 (或者 KM算法)来解决,该算法求解对象是一个代价矩阵,所以首先讨论一下如何求代价矩阵:
- 使用
平方马氏距离来度量 Track 和 Detection 之间的距离,由于两者使用的是高斯分布来进行表示的,很适合使用马氏距离来度量两个分布之间的距离。马氏距离又称为协方差距离,是一种有效计算两个未知样本集相似度的方法,所以在这里度量 Track 和 Detection 的匹配程度。

- 其中 d j d_{j} dj 代表第 j j j 个 detection, y i y_{i} yi 代表第 i i i 个track, S i l S_i^{l} Sil 代表 d 和 y 的协方差。
- 第二个公式是一个指示器,比较的是马氏距离和卡方分布的阈值, t ( l ) = 9.4877 t^{(l)}=9.4877 t(l)=9.4877,如果马氏距离小于该阈值,代表成功匹配。
- 使用
cosine距离来度量表观特征之间的距离,reid 模型抽出得到一个 128 维的向量,使用余弦距离来进行比对:

- r j T r k ( i ) r_j^Tr_k^{(i)} rjTrk(i) 计算的是余弦相似度,而
余弦距离=1-余弦相似度,通过 cosine 距离来度量 track 的表观特征和 detection 对应的表观特征,来更加准确地预测 ID。SORT中仅仅用运动信息进行匹配会导致 ID Switch 比较严重,引入外观模型+级联匹配可以缓解这个问题。- 同上,余弦距离这部分也使用了一个指示器,如果余弦距离小于 t ( 2 ) t^{(2)} t(2),则认为匹配上。这个阈值在代码中被设置为 0.2(由参数
max_dist控制),这个属于超参数,在人脸识别中一般设置为 0.6。
综合匹配度是通过运动模型和外观模型的加权得到的

2.3 级联匹配
级联匹配是 Deep SORT 区别于 SORT 的一个核心算法,致力于解决目标被长时间遮挡的情况。为了让当前 Detection 匹配上当前时刻较近的 Track,匹配的时候 Detection 优先匹配消失时间较短的 Track。
当目标被长时间遮挡,之后卡尔曼滤波预测结果将增加非常大的不确定性(因为在被遮挡这段时间没有观测对象来调整,所以不确定性会增加), 状态空间内的可观察性就会大大降低。
在两个 Track 竞争同一个 Detection 的时候,消失时间更长的 Track 往往匹配得到的马氏距离更小,使得 Detection 更可能和遮挡时间较长的 Track 相关联,这种情况会破坏一个 Track 的持续性,这也就是 SORT 中 ID Switch 太高的原因之一。
def _match(self, detections):
""" 主要功能是进行匹配,找到匹配的,未匹配的部分 """
def gated_metric(tracks, dets, track_indices, detection_indices):
""" 用于计算 track 和 detection 之间的距离、代价函数,需要使用在 KM 算法之前 """
features = np.array([dets[i].feature for i in detection_indices])
targets = np.array([tracks[i].track_id for i in track_indices])
# 1. 通过最近邻计算出代价矩阵
cost_matrix = self.metric.distance(features, targets)
# 2. 计算马氏距离,得到新的状态矩阵
cost_matrix = linear_assignment.gate_cost_matrix(self.kf, cost_matrix, tracks, dets,
track_indices, detection_indices)
return cost_matrix
# 划分不同轨迹的状态
confirmed_tracks = [i for i, t in enumerate(self.tracks) if t.is_confirmed()]
unconfirmed_tracks = [i for i, t in enumerate(self.tracks) if not t.is_confirmed()]
# 进行级联匹配,得到匹配的track、不匹配的track、不匹配的detection
matches_a, unmatched_tracks_a, unmatched_detections = \
linear_assignment.matching_cascade(gated_metric, self.metric.matching_threshold, self.max_age,
self.tracks, detections, confirmed_tracks)
# 将所有状态为未确定态的轨迹和刚刚没有匹配上的轨迹组合为 iou_track_candidates 进行 IoU 的匹配
iou_track_candidates = unconfirmed_tracks + [k for k in unmatched_tracks_a
if self.tracks[k].time_since_update == 1]
# 未匹配
unmatched_tracks_a = [k for k in unmatched_tracks_a if self.tracks[k].time_since_update != 1]
# 对级联匹配中还没有匹配成功的目标再进行 IoU 匹配
matches_b, unmatched_tracks_b, unmatched_detections = \
linear_assignment.min_cost_matching(iou_matching.iou_cost, self.max_iou_distance, self.tracks,
detections, iou_track_candidates, unmatched_detections)
matches = matches_a + matches_b
unmatched_tracks = list(set(unmatched_tracks_a + unmatched_tracks_b))
return matches, unmatched_tracks, unmatched_detections
2.4 表观特征
表观特征这部分借用了 行人重识别领域 的网络模型,这部分的网络是需要提前离线学习好,其功能是提取出具有区分度的特征。
网络最后的输出是一个 128 维的向量用于代表该部分表观特征(一般维度越高区分度越高带来的计算量越大)。最后使用了 L2归一化 来将特征映射到单位超球面上,以便进一步使用余弦表观来度量相似度。
三、算法实现
3.1 MOT 主要步骤
- 给定视频原始帧。
- 运行目标检测器进行检测,获取目标检测框。
- 将所有目标框中对应的目标抠出来,进行特征提取(包括表观特征或者运动特征)。
- 进行相似度计算,计算前后两帧目标之间的匹配程度(前后属于同一个目标的之间的距离比较小,不同目标的距离比较大)
- 数据关联,为每个对象分配目标的 ID。
以上就是四个核心步骤,其中核心是检测,SORT论文的摘要中提到,仅仅换一个更好的检测器,就可以将目标跟踪表现提升18.9%。
3.2 SORT
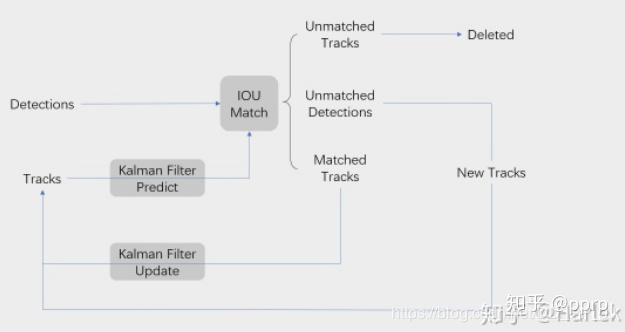
Deep SORT 算法的前身是 SORT, 全称是 Simple Online and Realtime Tracking。简单介绍一下,SORT 最大特点是基于 Faster R-CNN 的目标检测方法,并利用 卡尔曼滤波算法+匈牙利算法,极大提高了多目标跟踪的速度,同时达到了 SOTA 的准确率。
卡尔曼滤波算法 分为两个过程,预测和更新。该算法将目标的运动状态定义为 8 个正态分布的向量。
- 预测: 当目标经过移动,通过上一帧的目标框和速度等参数,预测出当前帧的目标框位置和速度等参数。
- 更新: 预测值和观测值,两个正态分布的状态进行线性加权,得到目前系统预测的状态。
匈牙利算法 解决的是一个分配问题,在 MOT 主要步骤中的计算相似度的,得到了前后两帧的相似度矩阵。匈牙利算法就是通过求解这个相似度矩阵,从而解决前后两帧真正匹配的目标。这部分 sklearn 库有对应的函数 linear_assignment 来进行求解。
SORT 算法中是通过前后两帧 IoU 来构建相似度矩阵,所以 SORT 计算速度非常快。
Detections 是通过目标检测器得到的目标框,Tracks是一段轨迹。核心是匹配的过程与卡尔曼滤波的预测和更新过程。
流程如下:
目标检测器得到目标框 Detections,同时卡尔曼滤波器预测当前的帧的 Tracks, 然后将 Detections 和 Tracks 进行 IoU 匹配,最终得到的结果分为:
Unmatched Tracks,这部分被认为是失配,Detection 和 Track 无法匹配,如果失配持续了 T l o s s T_{loss} Tloss 次,该目标 ID 将从图片中删除。(参数max_age)Unmatched Detections, 这部分说明没有任意一个 Track 能匹配 Detection, 所以要为这个 detection 分配一个新的 track。Matched Track,这部分说明得到了匹配。
卡尔曼滤波可以根据 Tracks 状态预测下一帧的目标框状态。
卡尔曼滤波更新是对观测值(匹配上的 Track)和估计值更新所有 track 的状态。
3.3 Deep SORT
DeepSort 中最大的特点是加入 外观信息,借用了 ReID领域模型 来提取特征,减少了 ID switch 的次数。整体流程图如下:
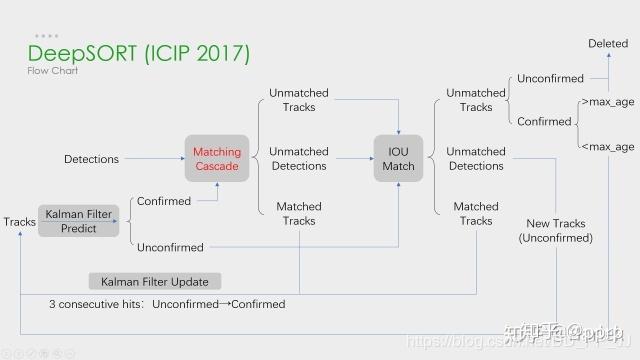
可以看出,Deep SORT 算法在 SORT 算法的基础上增加了 级联匹配(Matching Cascade)+新轨迹的确认(confirmed)。
总体流程就是:
- 卡尔曼滤波器预测轨迹 Tracks
- 使用匈牙利算法将预测得到的轨迹 Tracks 和当前帧中的 detections 进行匹配(级联匹配和 IoU 匹配)
- 卡尔曼滤波更新。
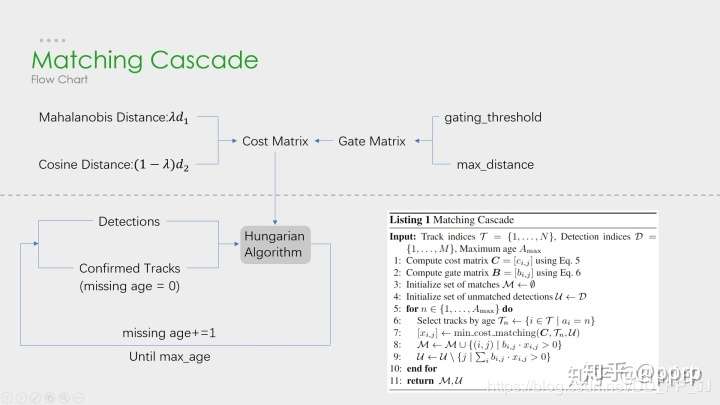
上半部分中计算相似度矩阵的方法使用到了 外观模型(ReID) 和 运动模型(马氏距离) 来计算相似度,得到代价矩阵,另外一个则是门控矩阵,用于限制代价矩阵中过大的值。
下半部分中是是级联匹配的数据关联步骤,匹配过程是一个循环(max_age 个迭代,默认为70),也就是从 missing age=0 到 missing age=70 的轨迹和 Detections 进行匹配,没有丢失过的轨迹优先匹配,丢失较为久远的就靠后匹配。通过这部分处理,可以重新将被遮挡目标找回,降低被遮挡然后再出现的目标发生的 ID Switch 次数。
将 Detection 和 Track 进行匹配,所以出现几种情况
- Detection 和 Track匹配,也就是 Matched Tracks。普通连续跟踪的目标都属于这种情况,前后两帧都有目标,能够匹配上。
- Detection 没有找到匹配的 Track,也就是 Unmatched Detections。图像中突然出现新的目标的时候,Detection 无法在之前的 Track 找到匹配的目标。
- Track 没有找到匹配的 Detection,也就是 Unmatched Tracks。连续追踪的目标超出图像区域,Track 无法与当前任意一个 Detection 匹配。
以上没有涉及一种特殊的情况,就是两个目标遮挡的情况。刚刚被遮挡的目标的 Track 也无法匹配 Detection,目标暂时从图像中消失。之后被遮挡目标再次出现的时候,应该尽量让被遮挡目标分配的ID不发生变动,减少 ID Switch 出现的次数,这就需要用到级联匹配了。
















 562
562











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











