







简要介绍
DeeplabV1和V2,即空洞卷积(atrous convolution), 能够明确地调整filters的感受野,并决定 DNN 计算得到特征的分辨率;DeeplabV3,即多尺度(multiple scales)分割物体,设计了串行和并行的空洞卷积模块,采用多种不同的 atrous rates 来获取多尺度的内容信息;DeeplabV3中提出 Atrous Spatial Pyramid Pooling(ASPP) 模块, 挖掘不同尺度的卷积特征,以及编码了全局内容信息的图像层特征,提升分割效果;
一、Deeplabv3
1.1 主要变化
(1)使用了 Multi-Grid 策略,即在模型后端多加几层不同 rate 的空洞卷积。
空洞卷积: Dilated Covolution,使得 backbone 在保持参数量不变,每个阶段的卷积层视野不变的前提下,靠后的卷积层也可保持较大的 feature maps 尺寸,从而有利于对小目标的检测,提高模型的整体性能。
Atrous convolution, 即 dilated convolution, 它主要是通过移除网络最后几层的降采样操作以及对应的滤波器核的上采样操作,来提取更紧凑的特征,相当于在不同的滤波器权重之间插入 holes,其决定了 DCNNs 计算的特征的分辨率,而不增加新的额外学习参数。

(2)将 batch normalization 加入到 ASPP 模块;
ASPP: Atrous Spacial Pyramid Pooling,在模型最后进行像素分类之前增加一个类似 Inception 的结构,包含不同个 rate(空洞间隔) 的 Atrous Conv,增强模型识别不同尺寸的同一物体的能力。
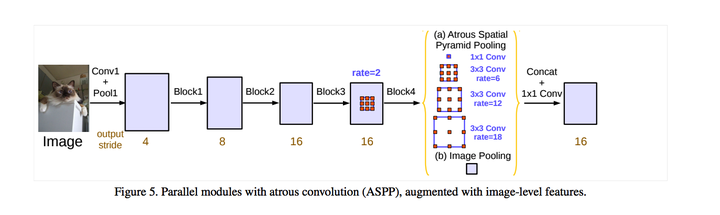
(3)具有不同 atrous rates 的 ASPP 能够有效的捕获多尺度信息。不过,论文发现,随着 sampling rate 的增加,有效 filter 特征权重(即有效特征区域,而不是补零区域的权重)的数量会变小。极端情况下,当空洞卷积的 rate 和 feature map 的大小一致时,
3
∗
3
3*3
3∗3 卷积会退化成
1
∗
1
1*1
1∗1。
采用 rate 非常大的 3×3 atrous convolution,由于图像边界效应,不能捕捉图像的大范围信息,effectively simply degenerating to 1×1 convolution, 所以提出将图像层特征整合仅在 ASPP 模块中。
(4)为了保留较大视野的多尺度信息,采用空洞卷积的方式解决这个问题,DeepLabv3 的 ASPP 加入了 全局池化层 + conv1x1 + 双线性插值上采样 的模块。
1.2 Atrous Convolution

扩大感受野:
- 在 deep net 中为了增加感受野且降低计算量,总要进行降采样(pooling 或 s2/conv),这样虽然可以增加感受野,但空间分辨率降低了。为了能不丢失分辨率,且仍然扩大感受野,可以使用空洞卷积。这在检测,分割任务中十分有用。一方面感受野大了可以检测分割大目标,另一方面分辨率高了可以精确定位目标。
捕获多尺度上下文信息:
- 空洞卷积有一个参数可以设置 dilation rate,具体含义就是在卷积核中填充
dilation rate-1个0,因此,当设置不同 dilation rate 时,感受野就会不一样,也即获取了多尺度信息。
二、Deeplabv3+
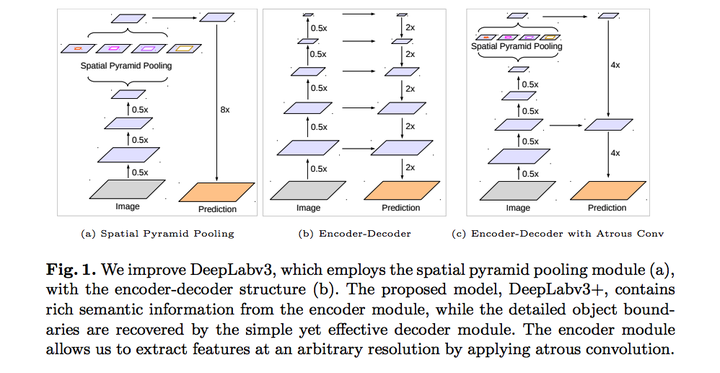

V3+ 最大的改进是将 DeepLab 的 DCNN 部分看做 Encoder,将 DCNN 输出的特征图上采样成原图大小的部分看做 Decoder ,构成 Encoder+Decoder 体系,双线性插值上采样便是一个简单的 Decoder,而强化 Decoder 便可使模型整体在图像语义分割边缘部分取得良好的结果。
具体来说,DeepLabV3+ 在 stride=16 的 DeepLabv3 模型输出上采样 4x 后,将 DCNN 中 0.25x 的输出使用
1
∗
1
1*1
1∗1 的卷积降维后与之连接(concat)再使用
3
∗
3
3*3
3∗3 卷积处理,然后双线性插值上采样 4 倍后得到相对于 DeepLabv3 更精细的结果。
Encoder-Decoder 网络包含:
- 逐步减少特征图并提取更高语义信息的 Encoder 模块
- 逐步恢复空间信息的 Decoder 模块
简述: DeepLabv3 作为 Encoder 提取特征,上采样后与 backbone 中间的低级特征以 concat 的方式融合,然后利用 3*3 卷积获得细化的特征,最后再进行上采样恢复到原始分辨率;在 backbone 部分,使用可分离卷积改进了 Xception。
2.1 改进之处
(1)借鉴 MobileNet,使用 Depth-wise 空洞卷积 +
1
∗
1
1*1
1∗1 卷积:
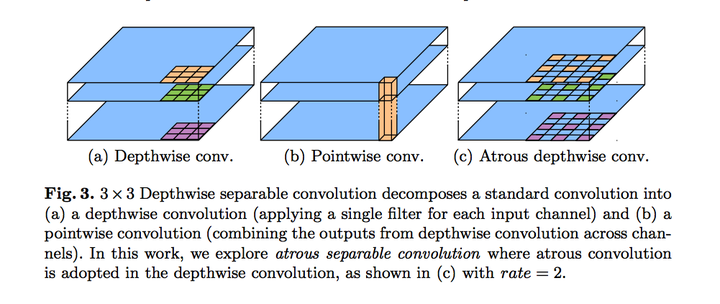
深度可分离卷积: 极大的降低了计算的复杂度。 【depthwise separable conv】 = 【depthwise conv】+【point conv】
空洞分离卷积: 【Atrous separable conv】=【depthwise conv】+【atrous conv】
【depthwise conv】是在每个通道上独自的进行空间卷积
【pointwise conv】是利用 1x1 卷积核 对【depthwise conv】进行组合,从而得到特征
【atrous conv】空洞卷积
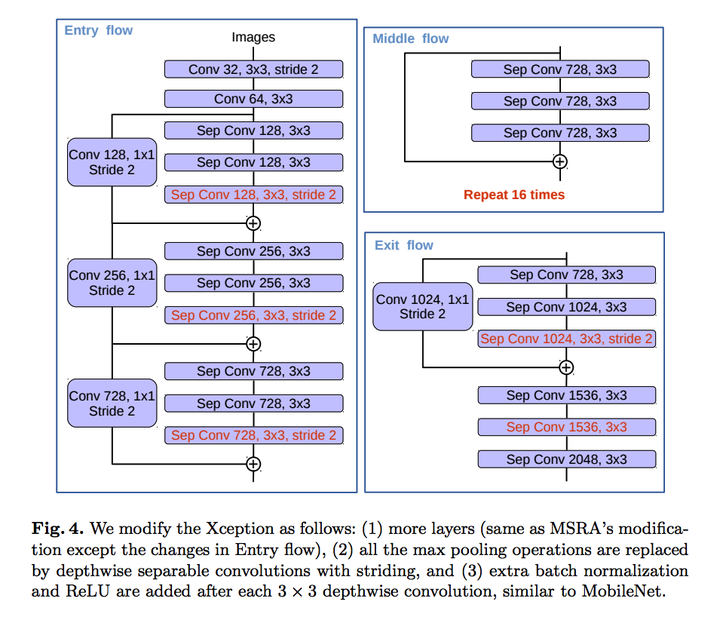
(2)使用修改过的 Xception 作为 backbone (也可使用ResNet101),并在 ASPP 和解码器模块中使用了 深度可分离卷积(Depthwise separable convolution),从而产生了一个更快、更强的编解码网络;:
2.2 Encoder
在 Encoder 部分,主要包括了 backbone(即上图中的 DCNN)、ASPP两大部分。
- 其中 backbone 有两种网络结构:将 layer4 改为空洞卷积的 Resnet 系列、改进的 Xception。从 backbone 出来的 feature map 分两部分:一部分是最后一层卷积输出的 feature maps,另一部分是中间的低级特征的 feature maps;backbone 输出的第一部分送入 ASPP 模块,第二部分则送入 Decoder 模块。
- ASPP 模块接受 backbone 的第一部分输出作为输入,使用了四种不同膨胀率的空洞卷积块(包括卷积、BN、激活层)和一个全局平均池化块(包括池化、卷积、BN、激活层)得到一共五组 feature maps,将其 concat 起来之后,经过一个 1*1 卷积块(包括卷积、BN、激活、dropout层),最后送入 Decoder 模块。
2.3 Decoder
在 Decoder 部分,接收来自 backbone 中间层的低级 feature maps 和来自 ASPP 模块的输出作为输入。
- 首先,对低级 feature maps 使用 1*1 卷积进行通道降维,从 256 降到 48(之所以需要降采样到48,是因为太多的通道会掩盖 ASPP 输出的 feature maps 的重要性,且实验验证 48 最佳);
- 然后,对来自 ASPP 的 feature maps 进行插值上采样,得到与低级 feature maps 尺寸相同的 feature maps;
- 接着,将通道降维的低级 feature maps 和线性插值上采样得到的 feature maps 使用 concat 拼接起来,并送入一组 3*3 卷积块进行处理;
- 最后,再次进行线性插值上采样,得到与原图分辨率大小一样的预测图。

















 417
417











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











