







原文Blog:https://zhuanlan.zhihu.com/p/61208558
1、deeplab v1
针对标准的深度卷积神经网络的两个主要问题:1.Striding操作使得输出尺寸减小; 2.Pooling对输入小变化的不变性,v1 使用空洞卷积(atrous)+条件随机场(CRFs)来解决这两个问题。
DeepLab v1是在VGG16的基础上做了修改:
- VGG16的全连接层转为卷积
- 最后的两个最大池化层去掉了下采样
- 后续卷积层的卷积核改为了空洞卷积
- 在ImageNet上预训练的VGG16权重上做finetune
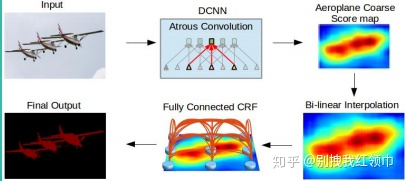
v1的方法将图像分类网络转换成dense feature extractors而不用学习额外的参数。
其中,CRF尝试找到图像像素之间的关系 : 相近的像素大概率为同一标签;CRF考虑在一个像素点标签分配概率;迭代细化结果。
2、deeplab v2
v2的改进:
- 提出了空洞空间金字塔池化(atrous spatial pyramid pooling,
ASPP),使用多个采样率采样得到的多尺度分割对象获得了更好的分割效果。 - 基础层使用了resnet
- 使用不同的学习率策略
针对物体的多尺度问题,提出ASPP模块;在卷积之前以多种采样率在给定的特征层上进行重采样;使用多条平行的有不同采样率的空洞卷积层。


3、deeplab v3
增强ASPP模块,复制resnet最后的block级联起来,加入BN。没有使用CRFs
新的ASPP模块包括:
- 一个1×1卷积和3个3×3的空洞卷积(采样率为(6,12,18)),每个卷积核都有256个且都有BN层
包含图像级特征image-level features(即全局平均池化Global Avearge Pooling) - 所有分支得到的结果concate起来通过1×1卷积之后得到最终结果。

4、deeplab v3+
- ASPP方法的优点是该种结构可以提取比较dense的特征,因为参考了不同尺度的feature,并且atrous
convolution的使用加强了提取dense特征的能力。但是在该种方法中由于pooling和有stride的conv的存在,使得分割目标的边界信息丢失严重。 - Encoder-Decoder方法的decoder中就可以起到修复尖锐物体边界的作用。

其中,(a)是v3的纵式结构;(b)是常见的编码-解码结构;©是v3+提出的encode-decode结构。

v3 plus还尝试改进的xception,如图7,效果好于resnet。

深度可分离卷积(deepwise convolution)
深度分离卷积是Xception这个模型中提出来的,具体来说分为两步,depthwise conv和pointwise conv,前者对输入特征图的每个通道分别单独进行卷积,然后再经过1*1卷积,这样操作使得参数量和计算量大幅减少,效果还挺好。在pytorch里,是这样实现的:
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1,
padding=0, dilation=1, groups=1,bias=True)
其中,groups参数就是实现depthwise conv的关键,默认为1,意思是将输入分为一组,此时是普通的卷积,当将其设为in_channels时,意思是将输入的每一个通道分别作为一组独立对其卷积,然后再加上1X1卷积,这样就符合xception的结构了。
附飞桨课件























 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









