







论文提出SFR模块,直接重新激活一组浅层特征来提升其在后续层的复用效率,而且整个重激活模式可端到端学习。由于重激活的稀疏性,额外引入的计算量非常小。从实验结果来看,基于SFR模块提出的CondeseNetV2性能还是很不错的,值得学习
来源:晓飞的算法工程笔记 公众号
论文: CondenseNet V2: Sparse Feature Reactivation for Deep Networks

Introduction
目前大多数SOTA卷积网络都只能应用于算力充足的场景,而低算力场景往往是多数算法落地的实际场景,所以轻量级网络的研究是十分重要的。近期有研究认为DenseNet的长距离连接是低效的,较深的层往往将早期特征认定为过时并在生成新特征时将其忽略,造成了额外的内存和计算消耗。
为了缓解这一低效的设计,CondenseNet在训练过程中根据权重动态逐步裁剪不重要的层间连接,而ShuffleNetV2则通过分支和shuffle的设计使得层间连接随着层间距离增大而减少。对于这两个网络的具体介绍,可以看看公众号之前发的两篇解读:《CondenseNet:可学习分组卷积,原作对DenseNet的轻量化改进 | CVPR 2018》和《ShuffleNetV1/V2简述 | 轻量级网络》。
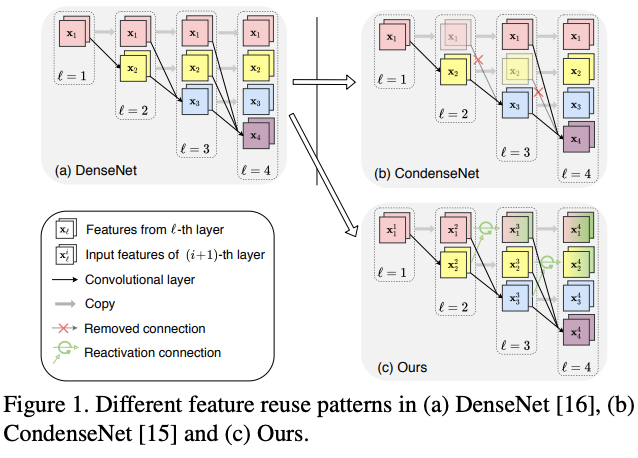
尽管上面的两个改进网络都有其提升,但论文认为直接淘汰浅层特征做法过于激进,浅层特征还是可能包含对生成深层特征有用的信息。在仔细研究后,论文提出了特征重激活(feature reactivation)的概念。整体思路如图1c所示,更新浅层特征从而可以更高效地被深层特征复用。
但需要注意的是,如果直接更新全部特征会带来过度的计算量,影响整体的效率。实际上,从DenseNet的成功可以看出,大部分的特征是不需要每次都更新的。为此,论文提出可学习的SFR(sparse feature reactivation)模块,通过学习的方式选择浅层特征进行重新激活,仅引入少量计算量就可以保持特征的"新鲜"。在应用时,SFR模块可转换分组卷积,复用当前的加速技术保证实践性能。
论文基于SFR模块和CondeseNet提出了CondenseNetV2,在性能和特征复用程度上都有很不错的表现,能媲美当前SOTA轻量级网络。实际上,SFR模块可简单地嵌入到任意卷积网络中,论文也将SFR模块嵌入ShuffleNetV2进行了相关实验,效果也是杠杠的。
Method
Sparse Feature Reactivation
先定义DenseNet中的特征复用机制。假设block共 L L L层,每层的特征输出为 x l x_{l} xl, x 0 x_0 x0为block输入。由于当前层会以稠密连接的形式复用前面所有层的输出, l l l层的复合函数会接受所有的前层特征作为输入:

在CondenseNet中, H l H_l Hl为可学习分组卷积(LGC),用于自动学习输入的分组以及去掉不重要的连接。而在ShuffleNet中, H l H_l Hl的输入会根据与当前层的距离进行丢弃。上面的两种网络设计倾向于丢弃冗余的长距离连接,取得了很不错的性能提升,然而这样的设计可能会阻碍高效的特征复用机制的探索。实际上,导致深层不再使用浅层特征的主要原因是特征 x l x_l xl一旦产生就不再改变。为此,论文提出计算消耗少的SFR模块,使得过时的特征可以被廉价地复用。
对第 l l l层引入重激活模块 G l ( ⋅ ) G_l(\cdot) Gl(⋅),该模块将层输入 x l x_l xl转换为 y l y_l yl,用于激活前面的层输出特征。定义激活操作 U ( ⋅ , ⋅ ) U(\cdot, \cdot) U(⋅,⋅)为与 y l y_l yl相加,稠密层的输入重激活可公式化为:

x l o u t x_l^{out} xlout为重激活的输出特征, l l l层的可学习分组卷积操作 H ( ⋅ ) H(\cdot) H(⋅)输出新特征 x l x_l xl。此外,旧特征 ( x i , i = 1 , ⋯ , l − 1 ) (x_i, i=1,\cdots,l-1) (xi,i=1,⋯,l−1)会被重新激活以提高其作用。

显然,重激活所有的特征是不必要的,DenseNet的成功说明大部分特征是不需要重新激活的,而且过多的重激活也会带来过多的额外计算。为此,论文希望能自动找到需要重激活的特征,只对这部分特征进行重激活。于是,论文提出了SFR(sparse feature reactivation)模块,如图2所示,基于剪枝的方法逐步达到这个目标。

重激活模块
G
l
(
⋅
)
G_l(\cdot)
Gl(⋅)包含卷积层、BN层和ReLU层,卷积核的权值矩阵
F
F
F的大小表示为
(
O
,
I
)
(O, I)
(O,I),
O
O
O和
I
I
I分别表示输出维度和输入维度。将
G
l
(
⋅
)
G_l(\cdot)
Gl(⋅)模块的输入
x
l
x_l
xl分成
G
G
G组,权值矩阵
F
F
F也随之分为
G
G
G组
F
1
,
⋯
,
F
G
F^1,\cdots,F^G
F1,⋯,FG,每个的大小变为
(
O
,
I
/
G
)
(O,I/G)
(O,I/G)。注意这里的分组不是将卷积变为分组卷积,只是为了方便稀疏化而进行的简单分组,计算量和参数量没改变。为了将重激活连接稀疏化,定义稀疏因子
S
S
S(也可以每组不同),使得每组在训练后只能选择
O
S
\frac{O}{S}
SO个维度进行重激活。
在训练期间,每个
G
l
(
⋅
)
G_l(\cdot)
Gl(⋅)中的连接方式由
G
G
G个二值掩码
M
g
∈
{
0
,
1
}
O
×
1
G
,
g
=
1
,
⋯
,
G
M^g\in\{0,1\}^{O\times\frac{1}{G}},g=1,\cdots,G
Mg∈{0,1}O×G1,g=1,⋯,G控制,通过将对应的值置零来筛选出
F
g
F^g
Fg中不必要的连接。换句话说,第
g
g
g组的权值变为
M
g
⊙
F
g
M^g\odot F^g
Mg⊙Fg,
⊙
\odot
⊙为element-wise相乘。
SFR模块参考了CondenseNet的训练方法进行端到端训练,将整体训练过程分为
S
−
1
S-1
S−1个稀疏阶段和最终的优化阶段。假设总训练周期为
E
E
E,则每个稀疏阶段的周期数为
E
2
(
S
−
1
)
\frac{E}{2(S-1)}
2(S−1)E,优化阶段的周期数为
E
2
\frac{E}{2}
2E。在训练时,SFR模块先重激活所有特征,即将
M
g
M^g
Mg初始为全1矩阵,随后在稀疏阶段逐步去掉多余的连接。在每个稀疏阶段中,
g
g
g组内重激活
i
i
i输出的重要程度通过计算对应权值的L1-norm
∑
j
=
1
I
/
G
∣
F
i
,
j
g
∣
\sum^{I/G}_{j=1}|F^g_{i,j}|
∑j=1I/G∣Fi,jg∣得到,将每个组中重要程度最低的
O
S
\frac{O}{S}
SO个输出(除掉组内已裁剪过的)裁剪掉,即将
j
j
j输出对应的
g
g
g组权值
M
i
,
j
g
M^g_{i,j}
Mi,jg设为零。如果
i
i
i输出在每个组中都被裁剪了,则代表该特征不需要重激活。在训练之后,每组输入只更新
1
/
S
1/S
1/S比例的输出,
S
S
S的值越大,稀疏程度越高。

在测试阶段,SFR模块可转换为标准分组卷积和index层的实现,这样的实现在实际使用中可以更高效地计算。如图3所示,转换后的分组卷积包含 G G G组,输出和输入维度为 ( O G S , I ) (\frac{OG}{S}, I) (SOG,I)。在分组卷积产生中间特征后,index层用于重排输出的顺序,从而获得 y l y_l yl。在排序时,需要将相同序号的中间特征相加再进行排序。
Architecture Design

基于提出的SFR模块,论文在CondenseNet的基础上改造出CondeseNetV2的新稠密层,结构如图4右所示。LGC层先选择重要的连接,基于选择的特征产生新特征 x l x_l xl。随后SFR模块将 x l x_l xl作为输入,学习重激活过时的特征。跟CondenseNet一样,为了增加组间交流,每次分组卷积后面都接一个shuffle操作。从图4的结构对比可以看出,CondenseNet和CondenseNetV2之间的差异在于旧特征的重激活,CondenseNetV2的特征复用机制效率更高。

CondenseNetV2沿用了CondenseNet指数增长以及全稠密连接的设计范式,加入了SFR-DenseLayer。结构图表1所示,SE模块和hard-swish非线性激活依旧使用。表1展示的是参考用的基础设计,调整的超参数或网络搜索可以进一步提升性能。
Sparse Feature Reactivation in ShuffleNetV2

SFR模块可嵌入到任意CNN中,除了CondenseNet,论文还尝试了ShuffleNet的改造。改造后的结构如图5所示,论文称之为SFR-ShuffleNetV2,仅应用于非下采样层。
Experiment
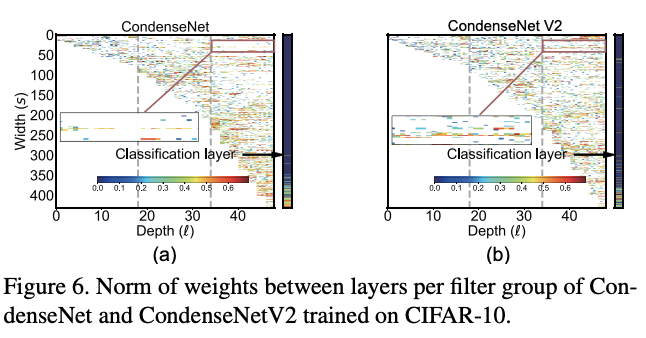
对不同层的卷积核权值进行可视化,纵坐标可认为是来自不同层的特征。可以看到,CondenseNet更关注相邻层的特征,而CondenseNetV2则也会考虑较早层的特征。

通过卷积核权值之和直接展示了层间的关联层度,进一步展示了CondenseNet对较早层的复用程度较高。

不同参数下的准确率对比,其中图b的 S = 1 S=1 S=1即CondenseNet。

论文提出了三种不同大小的CondenseNetV2,参数如表2所示,而ImageNet上的性能对比如表3所示。

在ImageNet上对比各模块的实际提升效果。

与SOTA模块在ImageNet上进行对比。

在端侧设备上进行推理速度对比。
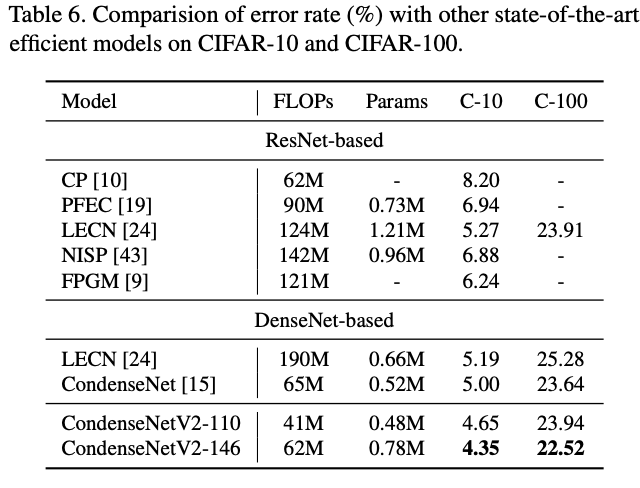
CIFAR数据集上的网络对比。

作为检测主干网络的性能对比。
Conclusion
论文提出SFR模块,直接重新激活一组浅层特征来提升其在后续层的复用效率,而且整个重激活模式可端到端学习。由于重激活的稀疏性,额外引入的计算量非常小。从实验结果来看,基于SFR模块提出的CondeseNetV2性能还是很不错的,值得学习。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】
















 8938
8938











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









