







现实世界的数据通常表现为长尾分布,常跨越多个类别。这种复杂性突显了内容理解的挑战,特别是在需要长尾多标签图像分类(
LTMLC)的场景中。在这些情况下,不平衡的数据分布和多物体识别构成了重大障碍。为了解决这个问题,论文提出了一种新颖且有效的LTMLC方法,称为类别提示精炼特征学习(CPRFL)。该方法从预训练的CLIP嵌入初始化类别提示,通过与视觉特征的交互解耦类别特定的视觉表示,从而促进了头部类和尾部类之间的语义关联建立。为了减轻视觉-语义领域的偏差,论文设计了一种渐进式双路径反向传播机制,通过逐步将上下文相关的视觉信息纳入提示来精炼提示。同时,精炼过程在精炼提示的指导下促进了类别特定视觉表示的渐进纯化。此外,考虑到负样本与正样本的不平衡,采用了非对称损失作为优化目标,以抑制所有类别中的负样本,并可能提升头部到尾部的识别性能。来源:晓飞的算法工程笔记 公众号,转载请注明出处
论文: Category-Prompt Refined Feature Learning for Long-Tailed Multi-Label Image Classification

Introduction
随着深度网络的快速发展,近年来计算机视觉领域取得了显著的进展,尤其是在图像分类任务中。这一进展在很大程度上依赖于许多主流的平衡基准(例如CIFAR、ImageNet ILSVRC、MS COCO),这些基准具有两个关键特征:1)它们提供了在所有类别之间相对平衡且数量充足的样本,2)每个样本仅属于一个类别。然而,在实际应用中,不同类别的分布往往呈现长尾分布模式,深度网络往往在尾部类别上表现不佳。同时,与经典的单标签分类不同,实际场景中图像通常与多个标签相关联,这增加了任务的复杂性和挑战。为了应对这些问题,越来越多的研究集中在长尾多标签图像分类(LTMLC)问题上。
由于尾部类别的样本相对稀少,解决长尾多标签图像分类(LTMLC)问题的主流方法主要集中在通过采用各种策略来解决头部与尾部的不平衡问题,例如对每个类别的样本数量进行重采样、为不同类别重新加权损失、以及解耦表示学习和分类头的学习。尽管这些方法做出了重要贡献,但它们通常忽略了两个关键方面。首先,在长尾学习中,考虑头部和尾部类别之间的语义相关性至关重要。利用这种相关性可以在头部类别的支持下显著提高尾部类别的性能。其次,实际世界中的图像通常包含多种对象、场景或属性,这增加了分类任务的复杂性。上述方法通常从全局角度考虑提取图像的视觉表示。然而,这种全局视觉表示包含了来自多个对象的混合特征,这阻碍了对每个类别的有效特征分类。因此,如何在长尾数据分布中探索类别之间的语义相关性,并提取局部类别特定特征,仍然是一个重要的研究领域。
最近,视觉-语言预训练(VLP)模型已成功适应于各种下游视觉任务。例如,CLIP在数十亿对图像-文本样本上进行预训练,其文本编码器包含了来自自然语言处理(NLP)语料库的丰富语言知识。文本编码器在编码文本模态中的语义上下文表示方面展示了巨大的潜力。因此,可以利用CLIP的文本嵌入表示来编码头部和尾部类别之间的语义相关性。此外,在许多研究中,CLIP的文本嵌入已成功作为语义提示,用于将局部类别特定的视觉表示与全局混合特征解耦。
为了应对长尾多标签分类(LTMLC)固有的挑战,论文提出了一种新颖且有效的方法,称为类别提示精炼特征学习(Category-Prompt Refined Feature Learning,CPRFL)。CPRFL利用CLIP的文本编码器的强大的语义表示能力提取类别语义,从而建立头部和尾部类别之间的语义相关性。随后,提取的类别语义用于初始化所有类别的提示,这些提示与视觉特征交互,以辨别与每个类别相关的上下文视觉信息。
这种视觉-语义交互可以有效地将类别特定的视觉表示从输入样本中解耦,但这些初始提示缺乏视觉上下文信息,导致在信息交互过程中语义和视觉领域之间存在显著的数据偏差。本质上,初始提示可能不够精准,从而影响类别特定视觉表示的质量。为了解决这个问题,论文引入了一种渐进式双路径反向传播(progressive Dual-Path Back-Propagation)机制来迭代精炼提示。该机制逐步将与上下文相关的视觉信息积累到提示中。同时,在精炼提示的指导下,类别特定的视觉表示得到净化,从而提高其相关性和准确性。
最后,为了进一步解决多类别中固有的负样本与正样本不平衡问题,论文引入了在这种情况下常用的重新加权(Re-Weighting,RW)策略。具体来说,采用了非对称损失(Asymmetric Loss,ASL)作为优化目标,有效抑制了所有类别中的负样本,并可能改善LTMLC任务中头部与尾部类别的性能。
论文贡献总结如下:
-
提出了一种新颖的提示学习方法,称为类别提示精炼特征学习(
CPRFL),用于长尾多标签图像分类(LTMLC)。CPRFL利用CLIP的文本编码器提取类别语义,充分发挥其强大的语义表示能力,促进头部和尾部类别之间的语义关联的建立。提取的类别语义作为类别提示,用于实现类别特定视觉表示的解耦。这是首次利用类别语义关联来缓解LTMLC中的头尾不平衡问题,提供了一种针对数据特征量身定制的开创性解决方案。 -
设计了一种渐进式双路径反向传播机制,旨在通过在视觉-语义交互过程中逐步将与上下文相关的视觉信息融入提示中,从而精炼类别提示。通过采用一系列双路径梯度反向传播,有效地抵消了初始提示带来的视觉-语义领域偏差。同时,精炼过程促进了类别特定视觉表示的逐步净化。
-
在两个
LTMLC基准测试上进行了实验,包括公开可用的数据集COCO-LT和VOC-LT。大量实验不仅验证了方法的有效性,还突显了其相较于最近先进方法的显著优越性。
Methods
Overview
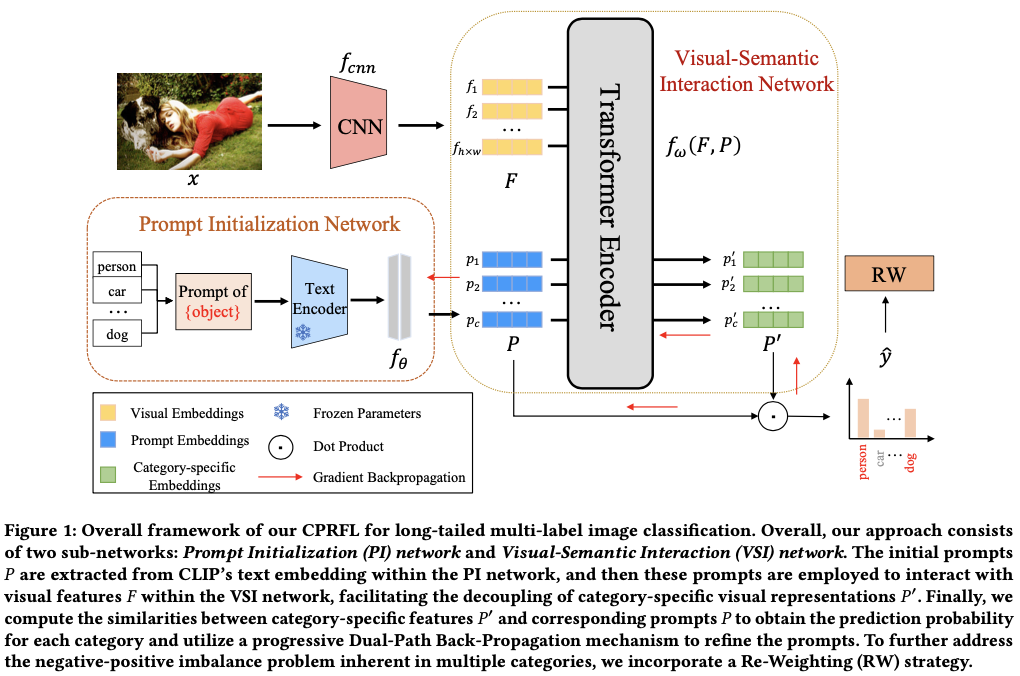
CPRFL方法包括两个子网络,即提示初始化(PI)网络和视觉-语义交互(VSI)网络。首先,利用预训练的CLIP的文本嵌入来初始化PI网络中的类别提示,利用类别语义编码不同类别之间的语义关联。随后,这些初始化的提示通过VSI网络中的Transformer编码器与提取的视觉特征进行交互。这个交互过程有助于解耦类别特定的视觉表示,使框架能够辨别与每个类别相关的上下文相关的视觉信息。最后,在类别层面计算类别特定特征与其对应提示之间的相似性,以获得每个类别的预测概率。为了减轻视觉-语义领域偏差,采用了一个逐步的双路径反向传播机制,由类别提示学习引导,以细化提示并在训练迭代中逐步净化类别特定的视觉表示。为进一步解决负样本与正样本的不平衡问题,采用了重加权策略(即非对称损失(ASL)),这有助于抑制所有类别中的负样本。
给定来自数据集
D
D
D 的输入图像
x
x
x ,首先利用一个主干网络提取局部图像特征
f
l
o
c
x
∈
R
h
×
w
×
d
0
f_{loc}^x \in \mathbb{R}^{h \times w \times d_0}
flocx∈Rh×w×d0 ,其中
d
0
,
h
,
w
d_0,h,w
d0,h,w 分别表示通道数、高度和宽度。论文采用了如ResNet-101的卷积网络,并通过去除最后的池化层来获取局部特征。之后,添加一个线性层
φ
\varphi
φ ,将特征从维度
d
0
d_0
d0 映射到维度
d
d
d ,以便将其投影到一个视觉-语义联合空间,从而匹配类别提示的维度:
KaTeX parse error: Undefined control sequence: \label at position 119: … = h \times w. \̲l̲a̲b̲e̲l̲{eq:1} \end{equ…
利用局部特征,我们在它们与初始类别提示之间进行视觉-语义信息交互,以辨别类别特定的视觉信息。
形式上,预训练的CLIP包括一个图像编码器
f
(
∙
)
f(\bullet)
f(∙) 和一个文本编码器
g
(
∙
)
g(\bullet)
g(∙) 。为了论文的目的,仅利用文本编码器来提取类别语义。具体来说,采用一个经典的预定义模板 “a photo of a[CLASS]” 作为文本编码器的输入文本。然后,文本编码器将输入文本(类别
i
i
i ,
i
=
1
,
.
.
.
,
c
i=1,...,c
i=1,...,c )映射到文本嵌入
W
=
g
(
i
)
=
{
w
1
,
w
2
,
.
.
.
,
w
c
}
∈
R
c
×
m
\mathcal{W} = g(i) =\{w_1,w_2,...,w_c\}\in \mathbb{R}^{c \times m}
W=g(i)={w1,w2,...,wc}∈Rc×m ,其中
c
c
c 表示类别数,
m
m
m 表示嵌入的维度长度。提取的文本嵌入作为初始化类别提示的类别语义。
Category-Prompt Initialization
为了弥合语义领域和视觉领域之间的差距,近期的研究尝试使用线性层将语义词嵌入投影到视觉-语义联合空间。论文选择了非线性结构来处理来自预训练CLIP文本嵌入的类别语义,而不是直接使用线性层进行投影。这种方法能够实现从语义空间到视觉-语义联合空间的更复杂的投影。
具体来说,论文设计了一个提示初始化(PI)网络,该网络由两个全连接层和一个非线性激活函数组成。通过PI网络执行的非线性变换,将预训练CLIP的文本嵌入
W
\mathcal{W}
W 映射到初始类别提示
P
=
{
p
1
,
p
2
,
.
.
.
,
p
c
}
∈
R
c
×
d
\mathcal{P} = \{p_1,p_2,...,p_c\}\in \mathbb{R}^{c \times d}
P={p1,p2,...,pc}∈Rc×d :
KaTeX parse error: Undefined control sequence: \label at position 66: …1+b_1)W_2+b_2, \̲l̲a̲b̲e̲l̲{eq:2} \end{equ…
其中,
W
1
W_1
W1 、
W
2
W_2
W2 、
b
1
b_1
b1 和
b
2
b_2
b2 分别表示两个线性层的权重矩阵和偏置向量,而
G
E
L
U
GELU
GELU 表示非线性激活函数。这里,
W
1
∈
R
m
×
t
W_1 \in \mathbb{R}^{m \times t}
W1∈Rm×t ,
W
2
∈
R
t
×
d
W_2 \in \mathbb{R}^{t \times d}
W2∈Rt×d ,
t
=
τ
×
d
t = \tau \times d
t=τ×d ,
τ
\tau
τ 是控制隐藏层维度的扩展系数。通常情况下,
τ
\tau
τ 被设置为0.5。
PI网络在从预训练CLIP的文本编码器中提取类别语义方面发挥了至关重要的作用,利用其强大的语义表示能力,在不依赖真实标签的情况下建立不同类别之间的语义关联。通过用类别语义初始化类别提示,PI网络促进了从语义空间到视觉-语义联合空间的投影。此外,PI网络的非线性设计增强了提取类别提示的视觉-语义交互能力,从而改善了后续的视觉-语义信息交互。
Visual-Semantic Information Interaction
随着Transformer在计算机视觉领域的广泛应用,近期的研究展示了典型注意力机制在增强视觉-语义跨模态特征交互方面的能力,这激励论文设计了一个视觉-语义交互(VSI)网络。该网络包含一个Transformer编码器,以初始类别提示和视觉特征作为输入。Transformer编码器执行视觉-语义信息交互,以辨别与每个类别相关的上下文特定视觉信息。这个交互过程有效地解耦了类别特定的视觉表示,从而促进了每个类别的更好特征分类。
为了促进类别提示与视觉特征之间的视觉-语义信息交互,将初始类别提示
P
∈
R
c
×
d
\mathcal{P} \in \mathbb{R}^{c \times d}
P∈Rc×d 与视觉特征
F
∈
R
v
×
d
\mathcal{F} \in \mathbb{R}^{v \times d}
F∈Rv×d 进行连接,形成一个组合嵌入集
Z
=
(
F
,
P
)
∈
R
(
v
+
c
)
×
d
Z = (\mathcal{F},\mathcal{P}) \in \mathbb{R}^{(v+c) \times d}
Z=(F,P)∈R(v+c)×d ,输入到VSI网络中进行视觉-语义信息交互。在VSI网络中,每个嵌入
z
i
∈
Z
z_i \in Z
zi∈Z 通过Transformer编码器固有的多头自注意力机制进行计算和更新。值得注意的是,仅关注更新类别提示
P
\mathcal{P}
P ,因为这些提示代表了类别特定视觉表示的解耦部分。注意力权重
α
i
j
p
\alpha_{ij}^p
αijp 和随后的更新过程计算如下:
KaTeX parse error: Undefined control sequence: \label at position 84: …qrt{d}\right), \̲l̲a̲b̲e̲l̲{eq:3} \end{equ…
KaTeX parse error: Undefined control sequence: \label at position 64: …{ij}^pW_vz_j), \̲l̲a̲b̲e̲l̲{eq:4} \end{equ…
p i ′ = G E L U ( p ˉ i W r + b 3 ) W o + b 4 , \begin{equation} p_i' = GELU(\bar{p}_iW_r+b_3)W_o+b_4, \end{equation} pi′=GELU(pˉiWr+b3)Wo+b4,
其中,
W
q
,
W
k
,
W
v
W_q, W_k, W_v
Wq,Wk,Wv 分别是查询、键和值的权重矩阵,
W
r
,
W
o
W_r, W_o
Wr,Wo 是变换矩阵,
b
3
,
b
4
b_3, b_4
b3,b4 是偏置向量。为了简化VSI网络的复杂度,选择了单层Transformer编码器而不是堆叠层。VSI网络的输出结果和类别特定的视觉特征分别记作
Z
′
=
{
f
1
′
,
f
2
′
,
.
.
.
,
f
v
′
,
p
1
′
,
p
2
′
,
.
.
.
,
p
c
′
}
Z' = \{f_1', f_2', ..., f_v', p_1', p_2', ..., p_c'\}
Z′={f1′,f2′,...,fv′,p1′,p2′,...,pc′} 和
P
′
=
{
p
1
′
,
p
2
′
,
.
.
.
,
p
c
′
}
\mathcal{P}' = \{p_1', p_2', ..., p_c'\}
P′={p1′,p2′,...,pc′} 。在自注意力机制下,每个类别提示嵌入综合考虑了其对所有局部视觉特征和其他类别提示嵌入的注意力。这种综合注意力机制有效地辨别了样本中的上下文相关视觉信息,从而实现了类别特定视觉表示的解耦。
Category-Prompt Refined Feature Learning
在通过VSI网络实现视觉特征与初始提示的交互后,得到的输出
P
′
\mathcal{P}'
P′ 作为分类的类别特定特征。在传统的基于Transformer的方法中,从Transformer获得的具体输出特征通常通过线性层投影到标签空间,用于最终分类。与这些方法不同,将类别提示
P
\mathcal{P}
P 作为分类器,并计算类别特定特征与类别提示之间的相似性,以在特征空间内进行分类。类别
i
i
i 的分类概率
s
i
s_i
si 可以通过以下计算:
KaTeX parse error: Undefined control sequence: \label at position 50: …i' \cdot p_i). \̲l̲a̲b̲e̲l̲{eq:6} \end{equ…
在多标签设置中,由于数据特性的独特性,需要计算每个类别的类别特定特征向量与相应提示向量之间的点积相似度来确定概率(softmax一下),这种计算方法体现了绝对相似性。而论文偏离了传统的相似性模式,而是使用类别特定特征向量与所有提示向量之间的相对测量。这种做法的原因在于减少了计算冗余,因为计算每个类别的特征向量与无关类别提示之间的相似度是不必要的。
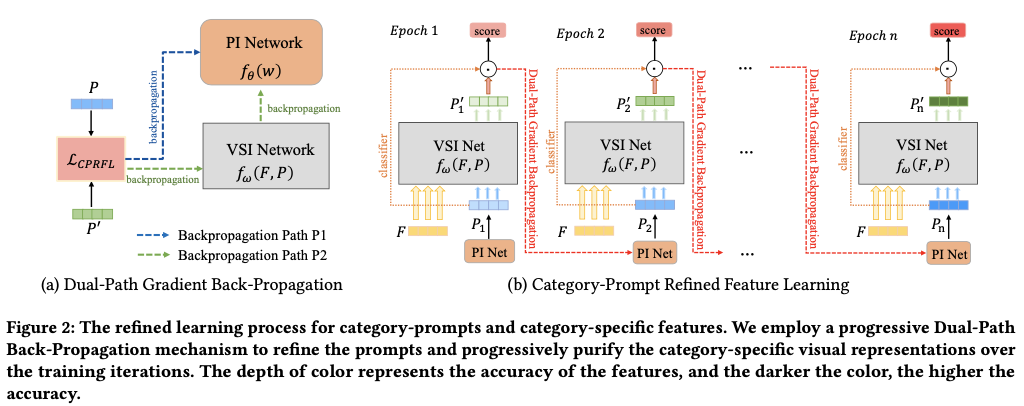
初始提示缺乏关键的视觉上下文信息,导致在信息交互过程中语义域与视觉域之间存在显著的数据偏差。这种差异导致初始提示不准确,从而影响类别特定视觉表示的质量。为了解决这个问题,论文引入了一种由类别提示学习引导的渐进式双路径反向传播机制。该机制在模型训练过程中涉及两个梯度优化路径(如图2a所示):一条通过VSI网络,另一条直接到PI网络。前者路径还优化VSI网络,以增强其视觉语义信息交互的能力。通过采用一系列双路径梯度反向传播,提示在训练迭代中逐渐得到优化,从而逐步积累与上下文相关的视觉信息。同时,优化后的提示指导生成更准确的类别特定视觉表示,从而实现类别特定特征的渐进净化。论文将这一整个过程称为“提示精炼特征学习”,反复进行直到收敛,如图2b所示。
Optimization
为了进一步解决多类别中固有的负样本与正样本不平衡问题,论文整合了在这种情况下常用的重新加权(Re-Weighting, RW)策略。具体而言,采用不对称损失(Asymmetric Loss, ASL)作为优化目标。ASL是一种焦点损失(focal loss)的变体,对正样本和负样本使用不同的
γ
\gamma
γ 值。给定输入图像
x
i
x_i
xi ,模型预测其最终类别概率
S
i
=
{
s
1
i
,
s
2
i
,
.
.
.
,
s
c
i
}
S_i = \{s_1^i,s_2^i,...,s_c^i\}
Si={s1i,s2i,...,sci} ,其真实标签为
Y
i
=
{
y
1
i
,
y
2
i
,
.
.
.
,
y
c
i
}
Y_i = \{y_1^i,y_2^i,...,y_c^i\}
Yi={y1i,y2i,...,yci} 。
使用ASL训练整个框架,如下所示:
KaTeX parse error: Undefined control sequence: \label at position 220: …\\ \end{cases} \̲l̲a̲b̲e̲l̲{eq:7} \end{equ…
其中,
c
c
c 是类别的数量。
s
~
j
i
\tilde{s}_j^i
s~ji 是ASL中的硬阈值,表示为
s
~
j
i
=
max
(
s
j
i
−
μ
,
0
)
\tilde{s}_j^i = \max(s_j^i - \mu, 0)
s~ji=max(sji−μ,0) 。
μ
\mu
μ 是一个用于过滤低置信度负样本的阈值。默认情况下,设置
γ
+
=
0
\gamma^{+} = 0
γ+=0 和
γ
−
=
4
\gamma^{-} = 4
γ−=4 。在论文的框架中,ASL有效地抑制了所有类别中的负样本,可能改善了LTMLC任务中的头尾类别性能。
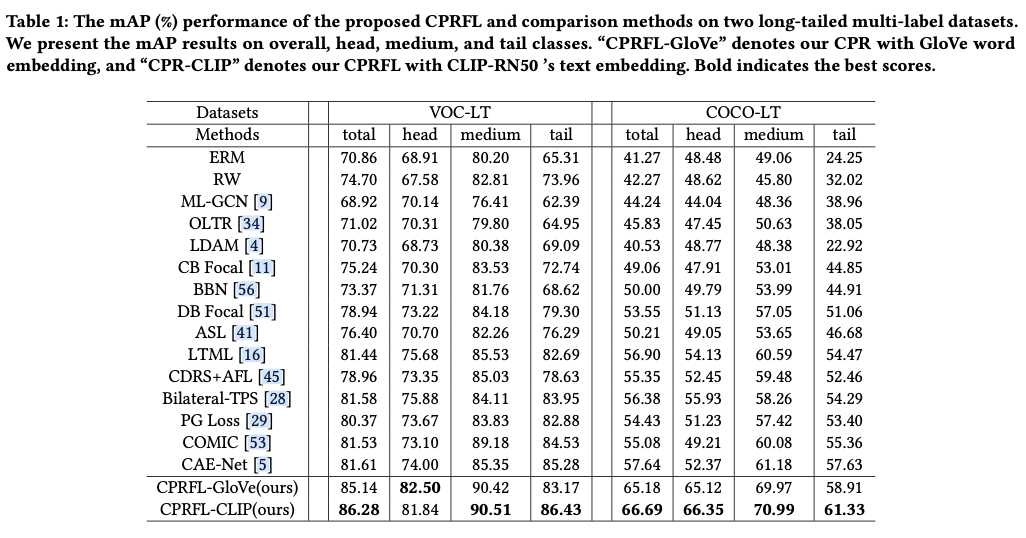
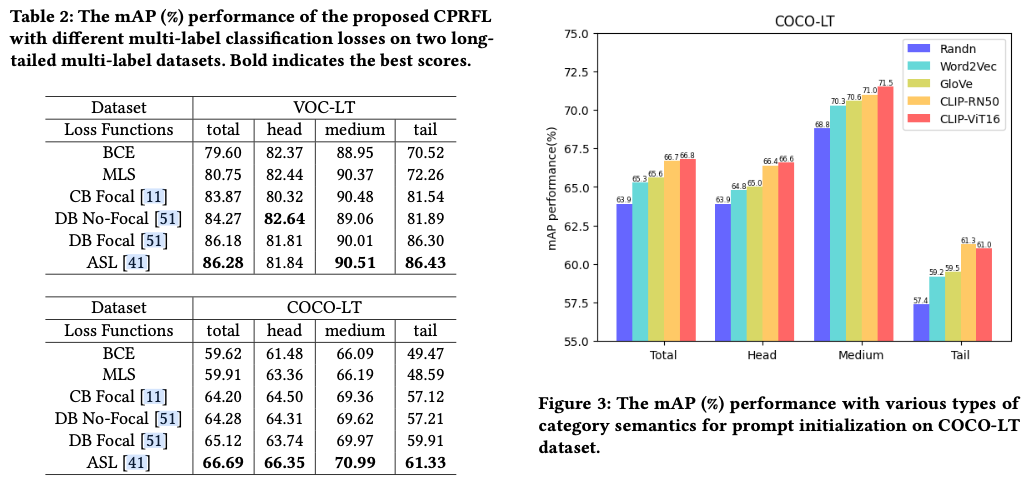
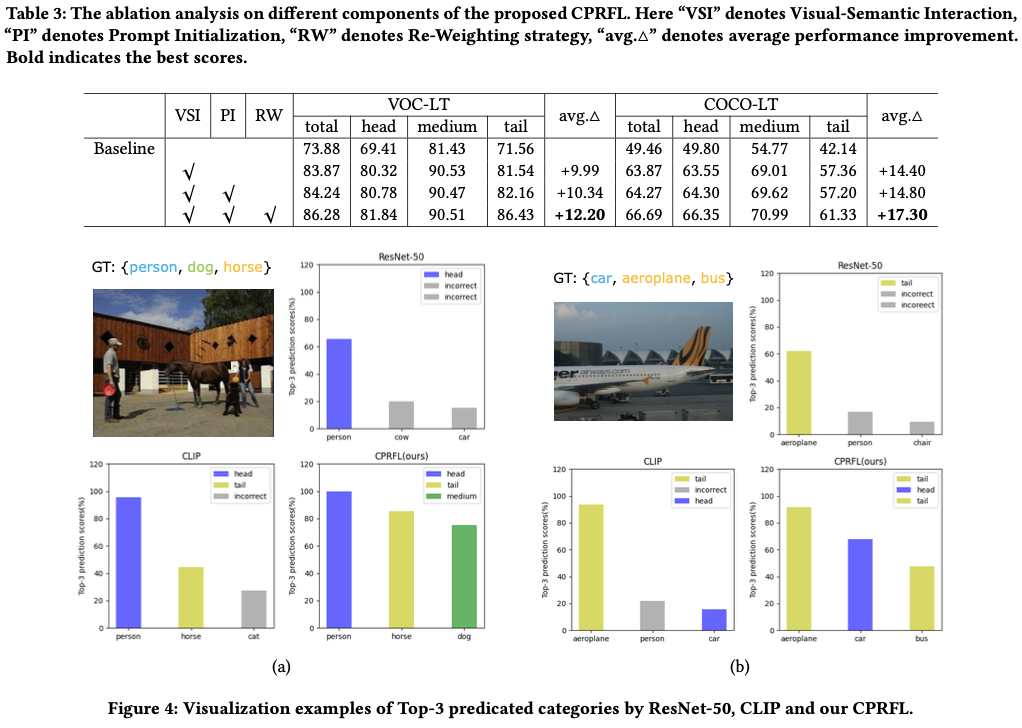
Experiments
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









