







 本文详细介绍了PEFT(Parameter-Efficient Fine-Tuning)中的主流微调技术,包括LoRA、QLoRA、Adapter Tuning、Prefix Tuning等,这些方法用于在预训练的大模型上进行有效调整,以适应特定的NLP任务,降低微调成本并提高性能。文章阐述了各方法的基本原理、操作过程及其在Transformer架构中的作用。
本文详细介绍了PEFT(Parameter-Efficient Fine-Tuning)中的主流微调技术,包括LoRA、QLoRA、Adapter Tuning、Prefix Tuning等,这些方法用于在预训练的大模型上进行有效调整,以适应特定的NLP任务,降低微调成本并提高性能。文章阐述了各方法的基本原理、操作过程及其在Transformer架构中的作用。
迁移学习
微调实际上是迁移学习的一个实例,其中预训练的模型(通常在大型通用数据集上训练)被用作特定任务的起点。
迁移学习(Transfer Learning)是一种机器学习方法,它利用已经在一个任务上学到的知识,来帮助提高另一个相关任务的学习效果。简单来说,迁移学习就是将已有模型(通常是在大型数据集上训练得到的)应用于新的但相关的任务上,以此来改善新任务的性能,尤其是在新任务的数据量相对较少的情况下。
迁移学习的核心思想是,不同但相关的任务之间共享一些有用的信息或特征,因此在一个任务上学到的知识可以迁移到另一个任务上。例如,一个在图片分类任务上学到的模型,可能对新的图片分类任务也有帮助,因为图片识别中的某些特征(如边缘、纹理等)在不同的分类任务中是通用的。
LLM训练的两个阶段
Step 1.预训练阶段
大模型首先在大量的无标签数据上进行训练,预训练的最终目的是让模型学习到语言的统计规律和一般知识。在这个过程中模型能够学习到词语的语义、句子的语法结构、以及文本的一般知识和上下文信息。
需要注意的是,预训练本质上是一个无监督学习过程;得到预训练模型(Pretrained Model), 也被称为基座模型(Base Model),模型具备通用的预测能力。如GLM-130B模型、OpenAI的A、B、C、D四大模型,都是基座模型。
Step 2.微调阶段
预训练好的模型然后在特定任务的数据上进行进一步的训练。这个过程通常涉及对模型的权重进行微小的调整,以使其更好地适应特定的任务;得到最终能力各异的模型,例如 GPT 系列、 ChatGLM-6B等模型;
大模型微调
大模型微调指的是“喂”给模型更多信息,对模型的特定功能进行 “调教”,即通过输入特定领域的数据集,让其学习这个领域的知识,从而让大模型能够更好的完成特定领域的NLP任务,例如情感分析、命名实体识别、文本分类、对话聊天等。
微调包括:大模型全量微调(Fine-tuning)、PEFT(Parameter-Efficient Fine-Tuning)
大模型全量微调(Fine-tuning)通过在预训练的大型模型基础上调整所有层和参数,使其适应特定任务。这一过程使用较小的学习率和特定任务的数据进行,可以充分利用预训练模型的通用特征,但可能需要更多的计算资源。
PEFT(Parameter-Efficient Fine-Tuning )技术旨在通过最小化微调参数的数量和计算复杂度,来提高预训练模型在新任务上的性能,从而缓解大型预训练模型的训练成本。
PEFT包括LORA、QLoRA、Adapter Tuning、Prefix Tuning、Prompt Tuning、P-Tuning及P-Tuning v2等。
下图示例了7个主流微调方法在Transformer网络架构的作用位置和简要说明。
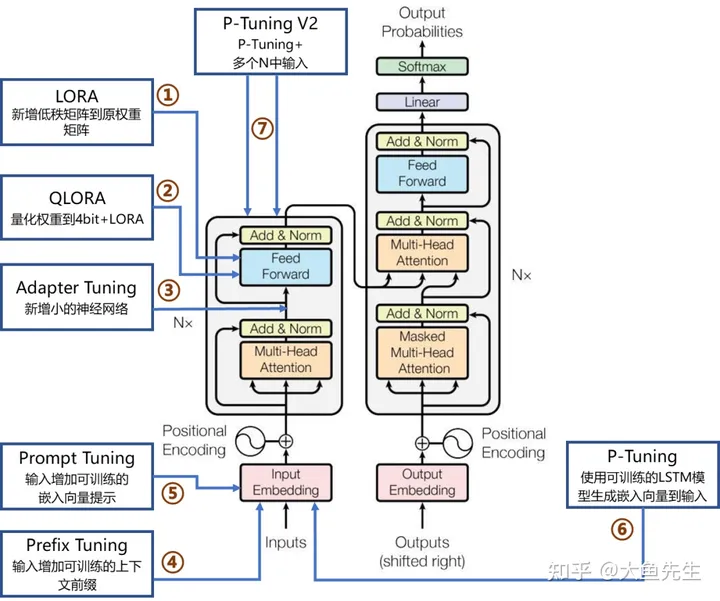
1、LoRA
LoRA是一种用于微调大型预训练语言模型(如GPT-3或BERT)的方法。它的核心思想是在模型的关键层中
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









