







 本文概述了自然语言处理(NLP)的历史发展,从早期的基于规则方法到统计方法的转变,以及深度学习和大数据如何推动NLP技术进步,特别是大规模语言模型的应用和扩展其应用领域。
本文概述了自然语言处理(NLP)的历史发展,从早期的基于规则方法到统计方法的转变,以及深度学习和大数据如何推动NLP技术进步,特别是大规模语言模型的应用和扩展其应用领域。
文章目录
-
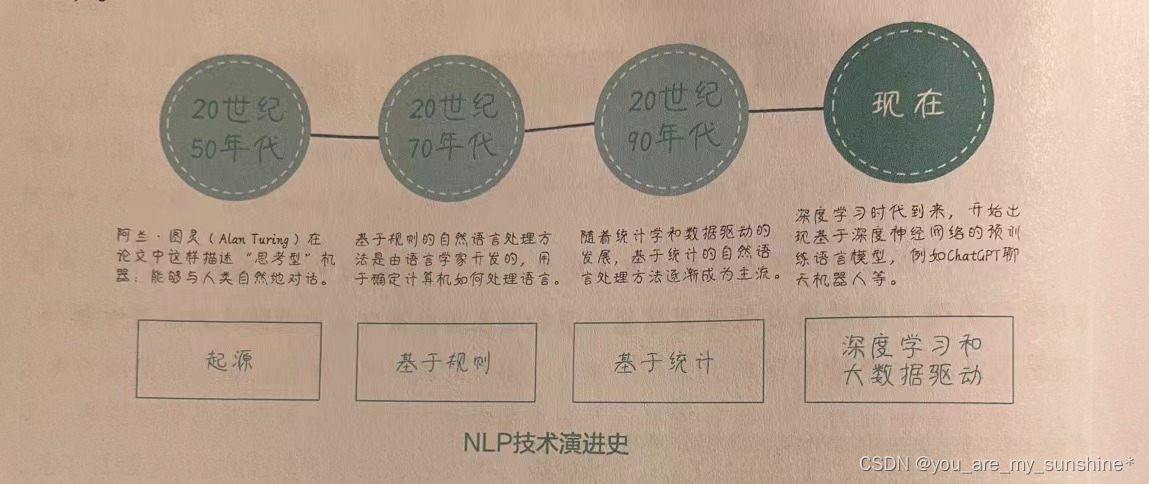
起源: NLP 的起源可以追溯到阿兰·图灵在20 世纪50年代提出的图灵测试。图灵测试的基本思想是,如果一个计算机程序能在自然语言对话中表现得像一个人,那么我们可以说它具有智能。从这里我们可以看出,AI最早的愿景与自然语言处理息息相关。NLP问题是AI从诞生之日起就亟须解决的主要问题。
-
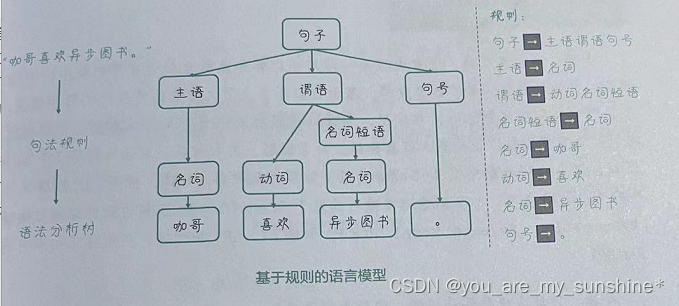
基于规则:在随后的数十年中,人们尝试通过基于语法和语义规则的方法来解决NLP问题。然而,由于规则很多且十分复杂,这种方法无法涵盖所有的语言现象。基于规则的语言模型的简单示例如下图所示。
-
基于统计:1970年以后,以弗雷德里克·贾里尼克(Frederick Jelinek)为首的IBM 科学家们采用了基于统计的方法来解决语音识别的问题,终于把一个基于规则的问题转换成了一个数学问题,最终使NLP任务的准确率有了质的提升。至此,人们才纷纷意识到原来的方法可能是行不通的,采用统计的方法才是一条正确的道路。因此,人们基于统计定义了语言模型(Language Model,LM):语言模型是一种用于捕捉自然语言中词汇、短语和句子的概率分布的统计模型。简单来说,语言模型旨在估计给定文本序列出现的概率,以帮助理解语言的结构和生成新的文本。
-
深度学习和大数据驱动:在确定了以统计学方法作为解决NLP 问题的主要武器之后,随着计算能力的提升和深度学习技术的发展,大数据驱动的NLP技术已经成为主流。这种技术使用深度神经网络(Deep Neural Network,也就是深层神经网络)等技术来处理海量的自然语言数据,从而学习到语言的复杂结构和语义。目前的大型预训练语言模型,在很多NLP任务上的表现甚至已经超过人类,不仅可以应用于语音识别、文本分类等任务,还可以生成自然语言文本,如对话系统、机器翻译等。
不难发现,基于规则和基于统计的语言模型,是NLP技术发展的关键节点,而大规模语言模型的诞生,又进一步拓展了NLP技术的应用范围。
学习的参考资料:
(1)书籍
利用Python进行数据分析
西瓜书
百面机器学习
机器学习实战
阿里云天池大赛赛题解析(机器学习篇)
白话机器学习中的数学
零基础学机器学习
图解机器学习算法
动手学深度学习(pytorch)
…
(2)机构
光环大数据
开课吧
极客时间
七月在线
深度之眼
贪心学院
拉勾教育
博学谷
慕课网
海贼宝藏
…















 316
316











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









