







ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
相关链接:arxiv
关键字:Large Language Models、GLM、Transformer、Post-training Alignment、Multi-language
摘要
本文介绍了ChatGLM,这是一个不断发展的大型语言模型系列,我们一直在开发中。本报告主要关注GLM-4语言系列,包括GLM-4、GLM-4-Air和GLM-4-9B。这些代表了我们训练的最先进的模型,它们结合了之前三代ChatGLM的所有见解和经验教训。迄今为止,GLM-4模型主要在中文和英文上进行了预训练,使用了大约一万亿个token,以及来自24种语言的一小部分语料库,并主要针对中文和英文使用进行了优化。通过多阶段后训练过程,包括有监督的微调和从人类反馈中学习,实现了高质量的对齐。评估表明,GLM-4在诸如MMLU、GSM8K、MATH、BBH、GPQA和HumanEval等通用指标方面与GPT-4不相上下或表现更佳,在按照IFEval测量的指令跟随方面接近GPT-4-Turbo,在长上下文任务方面与GPT-4 Turbo (128K)和Claude 3相当,并且在使用AlignBench测量的中文对齐方面优于GPT-4。GLM4 All Tools模型进一步对齐,以理解用户意图,并自主决定何时以及使用哪个工具来有效完成复杂任务。在实际应用中,它在通过Web浏览访问在线信息和使用Python解释器解决数学问题等任务中与GPT-4 All Tools相匹配甚至超越。在此过程中,我们开源了一系列模型,包括ChatGLM-6B(三代)、GLM-4-9B(128K、1M)、GLM-4V-9B、WebGLM和CodeGeeX,仅在2023年就在Hugging face上吸引了超过1000万次下载。开放模型可以通过https://github.com/THUDM和https://huggingface.co/THUDM访问。
核心方法
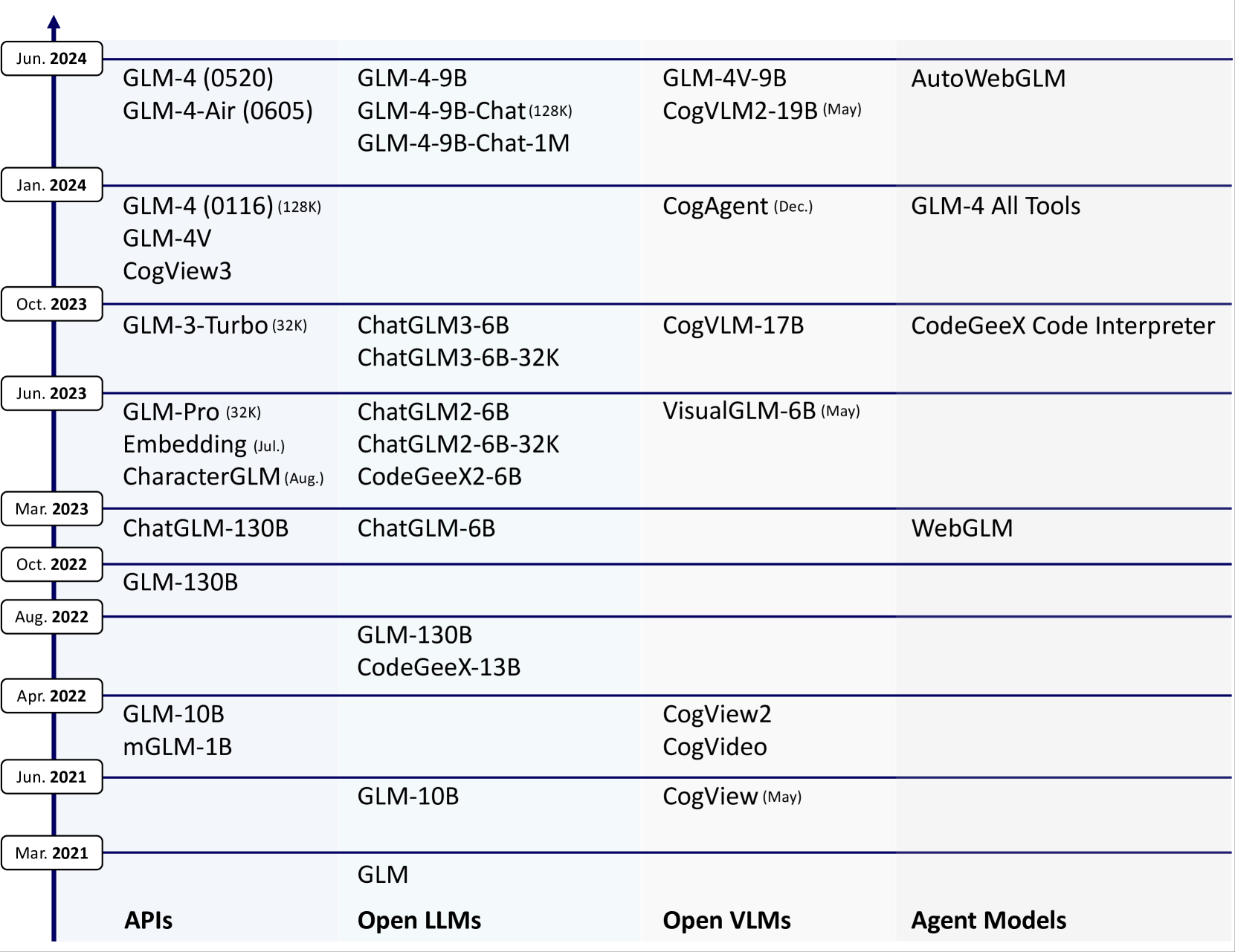
- 模型架构:GLM系列基于Transformer架构,采用了无偏置的Query、Key、Value(QKV)注意力机制,RMSNorm和SwiGLU替代了传统的LayerNorm和ReLU。
- 数据预处理:预训练语料包括多语言文档,经过去重、过滤和分词处理,使用了字节级BPE算法优化词汇表大小。
- 上下文长度扩展:通过位置编码扩展和持续训练,模型的上下文长度从2K扩展到32K,再到128K和1M。
- 后训练对齐:通过有监督的微调(SFT)和基于人类反馈的强化学习(RLHF),进一步优化模型以符合人类偏好。
- 多工具使用:GLM-4 All Tools模型能够理解用户意图,并自主选择最合适的工具来完成任务,如Web浏览器、Python解释器、文本到图像模型等。
实验说明
实验结果数据使用如下表格展示,并对实验进行详细说明:
| 模型 | MMLU | GSM8K | MATH | BBH | GPQA | HumanEval | 说明 |
|---|---|---|---|---|---|---|---|
| GLM-4-9B | 74.7 | 84.0 | 30.4 | 76.3 | - | 70.1 | 多语言预训练,上下文长度8K,后训练使用与GLM-4相同的流程和数据。 |
| GLM-4-Air | - | - | - | - | - | 75.7 | 性能与GLM-4 (0116)相当,具有更低的延迟和推理成本。 |
| GLM-4 (0520) | 83.3 | 93.3 | 61.3 | 84.7 | 39.9 | 78.5 | 最新模型,具有更好的性能。 |
实验数据来源于论文中的评估部分,展示了不同模型在多个基准测试上的性能。数据要求能够准确反映模

















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











