




 本文详细解析了贝叶斯分类的核心思想,包括朴素贝叶斯与贝叶斯网络,并通过实例展示了如何利用贝叶斯公式进行分类。文章还讨论了不同分类方法的优劣,以及如何结合实际场景灵活运用贝叶斯理论解决实际问题。
本文详细解析了贝叶斯分类的核心思想,包括朴素贝叶斯与贝叶斯网络,并通过实例展示了如何利用贝叶斯公式进行分类。文章还讨论了不同分类方法的优劣,以及如何结合实际场景灵活运用贝叶斯理论解决实际问题。
这两篇文章写得超赞:
朴素贝叶斯:
http://www.cnblogs.com/leoo2sk/archive/2010/09/17/naive-bayesian-classifier.html
贝叶斯网络:
http://www.cnblogs.com/leoo2sk/archive/2010/09/18/bayes-network.html
这篇文章写得很全:
http://www.kuqin.com/shuoit/20141111/343155.html
好了,开始随便写点东西吧:
贝叶斯,最根本的思想,莫不就是 先验分布+ 样本信息 = 后验分布。
先验,是没有任何输入的时候,最有可能的猜测
然后我们有了若干样本,知道这些样本的信息
最后,我们知道了,在这些样本下,后验分布如何
“贝叶斯定理之所以有用,是因为我们在生活中经常遇到这种情况:我们可以很容易直接得出P(A|B),P(B|A)则很难直接得出,但我们更关心P(B|A),贝叶斯定理就为我们打通从P(A|B)获得P(B|A)的道路。”
朴素贝叶斯:
所有条件都是相互独立的
要求的是 P(Yi|X)。而根据贝叶斯公式,需要计算 P(X|Yi) 和 P(Yi)。而根据条件独立,X={w1,w2….},只要求得 P(w1|Yi),P(w2|Yi)… 就可以了
注意的两点,一是如果w是连续的,可以使用正态分布的公式来算。二是如果某个类别没有某个特征,那实际上P(w|Y)就是0了,干扰会很大,所以默认给1的技术
贝叶斯网络
朴素贝叶斯的问题在于,假设了各个因素是条件独立的。不对。所以可以构建网络型的结构。有专家进行关系的梳理
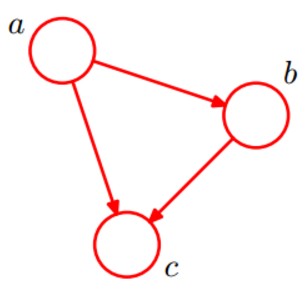
一个例子网络如下:
- 则它的计算如下:
- P(a,b,c) = P(c|a,b)P(b|a)P(a)
注意区分几种方法,一是概率,二是贝叶斯,三是加权。注意公式后的意义。以根据用户的购买行为判断性别为例说明。
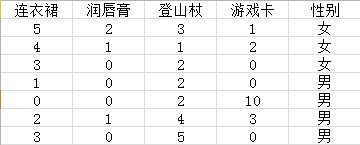
- 首先,假设数据张这个样子:
- 然后,可以计算得到各个w的值,即P(w|Yi)
- 一、概率的方法:
- 假设已知一个人买了润唇膏,连衣裙和登山杖,问他是男还是女,则可以计算下:
- P(男) = 0.25×0.33×0.68 = 0.0561
- P(女) = 0.75×0.66×0.31 = 0.1534
- 即:
- P(男) =0.0561/ (0.0561 + 0.1534 ) = 26.7%
- P(女) =0.1534/ (0.0561 + 0.1534 ) = 73.2%
- 故是个女的
- 这里,是几个连乘起来,公式后的意义就是:假设ta每次购买的时候,都是某一种性别的可能。多次购买,则这个概率连乘起来。
- 假设已知一个人买了润唇膏,连衣裙和登山杖,问他是男还是女,则可以计算下:
- 二、贝叶斯的方法:
- 依旧是理解公式的意义,已知买了c1,c2,c3,求解是某种性别的概率,即P(男|c1,c2,c3)。按贝叶斯公式,由假设各个类目条件独立,推理得 P(男|c1,c2,c3) = P(c1,c2,c3|男)P(男) / P(c1,c2,c3) = p(c1|男)p(c2|男)p(c3|男)p(男) / P(c1,c2,c3)。而分母可以去除掉,因为大家都一样的。
- 三、加权的方法:
- 可以看到,上面是有区分男女分布这种先验的概率的P(男)。衍生而来的一种“加权”的方法,如下:
- P(男) = (P(男|c1) * c1件数 + P(男|c2) * c2件数 + P(男|c3) * c3件数 ) / (c1件数 + c2件数 + c3件数)
- 类似是购买权重,以及考虑买的件数的关系
- 上述三个对比,其实发现都差不多…. 加权的可能要稍微好一点,约65%,反而是朴素贝叶斯最差….
- 再引申出来一点,上面是只考虑了购买,显然是不够的。而且会有男人的号被他女朋友用的情况,购买行为就很混乱。发现简单粗暴的,是根据姓名来,直观来看,叫健什么的男的多,叫丽什么的女的多。这个能到80%几啊!
频率 vs 概率
- 偶尔遇到一个问题,朴素贝叶斯时,的确要计算P(男|c1,c2,c3)的值,那就要计算分母P(c1,c2,c3)了。
- 当然,假设P(男|c1,c2,c3)的分子部分是A,可以再计算P(女|c1,c2,c3)的分子部分B,则P(男|c1,c2,c3) = A / (A+B),这是没有问题的
- 如果就是要算 P(c1,c2,c3),那么又有两种方法了。一是直接看(c1,c2,c3)这样的组合,在整个样本空间的占比,二是根据条件独立分别算P(c1)*P(c2)*P(c3)。直观上来,他们是不一样的,而且应该后一种方法更合理。其实没有这种说法,要明白 频率 和 概率的区别。我们都是在用频率来近似替代概率。所以样本量足够充足的话,这两种方法是一样的。不过样本量小的,还是后一种相对比较靠谱。


















 4202
4202

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









