







本程序是在windows系统下跑通的。
数据集下载连接:
链接:https://pan.baidu.com/s/1Gt2L4N_bq0wmfc50ke1QcQ
提取码:arq2
目录
一、环境配置

PyTorch中torch、torchvision、torchaudio版本对应关系
1. 尝试配置作者使用的环境(失败)
-
创建虚拟环境
conda create -n road_env_Dlink python=2.7-
激活虚拟环境
conda activate road_env_Dlink-
安装pytorch和cuda
没有特别符合上述的,进行了更改
conda install pytorch==1.4.0 torchvision==0.5.0 torchaudio==0.4.0 cudatoolkit=8.0 cudnn=5.1其中, conda install cudnn==5.1和 torchaudio==0.4.0都找不到
失败结束
2. 使用我之前的环境(成功)
conda install pytorch==1.7.0 torchvision==0.8.0 torchaudio==0.7.0 cudatoolkit=10.2 cudnn=7.6.5python3.8

二、遇到的问题及代码修改
修改了一些地方,因为源代码使用python2写的,我环境中的版本是python3会有不兼容,语法问题
(1)关于输出
python2:
print '********'需要改成python3:(加上括号)
print ('********')(2)map计算len长度出问题
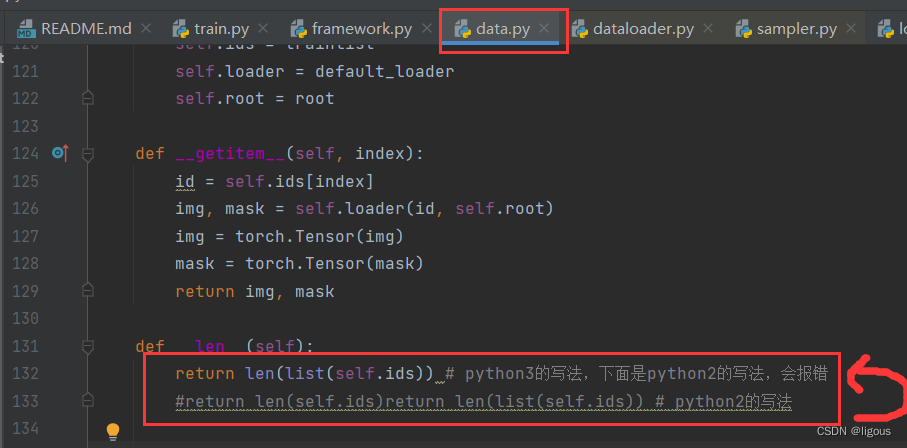
(3)map和list

应该是python3无法直接读取map中的各个元素(我的理解,不正确请指出哦)
(4)不同系统下的进程数问题
这个源代码可能是在linux系统下运行的,我的实验系统为windows10。

报错原因:在linux系统中可以使用多个子进程加载数据,而在windows系统中不能。所以在windows中要将DataLoader中的num_workers设置为0或者采用默认为0的设置
例如下图将num_workers的默认值置0,即可解决此报错问题
(5)内存不够问题
我的运行内存不够大,这个可以自行修改batch_size等参数,把占用内存变小一点。这里,我转移了服务器上运行,没在我的小破电脑上继续。
(6)loss优化问题
报错:
return loss.data[0]
IndexError: invalid index of a 0-dim tensor. Use `tensor.item()` in Python or `tensor.item<T>()` in C++ to convert a 0-dim tensor to a number
解决办法:修改loss.data[0]为loss.item()

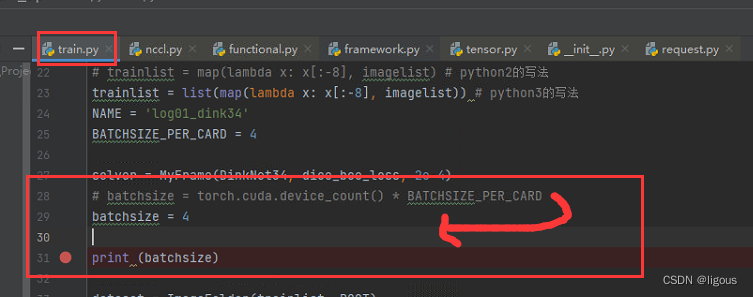
(7)gpu内存不够用
报错:
解决办法:修改batchsize大小,原本是8,改成了4,不过很奇怪,训练的时候一直没有训练情况的输出,还以为是卡死了,应该是还在训练,一个epoch时间太长了。
(8)python2和python3写文件的方式不同


也可以使用 mylog.write('写入文件的内容')
(9)train.py文件中无法将每个epoch的详细情况写入文件中
原因:关闭 “记录epoch的文件” 的指针在最后面,也就是说训练完所有epoch后该文件才会关闭,但在修改bug的时候,每次都是运行一半,文件一直没有被关闭,就出问题了。
解决办法:简单运行一下关闭该文件的代码,mylog.close(),可以在进入epoch前关闭该文件,然后停止本次运行,把文件关闭后,再次运行原来的程序即可。
经过修改bug后,终于跑通啦,由于batchsize只有4,每个epoch需要24分钟多一些, 还是很慢的。
代码整体参数设置:

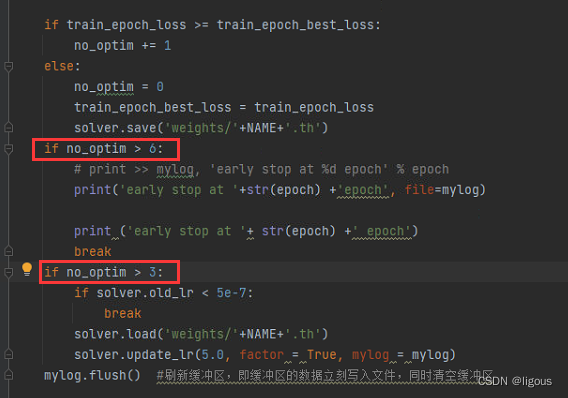
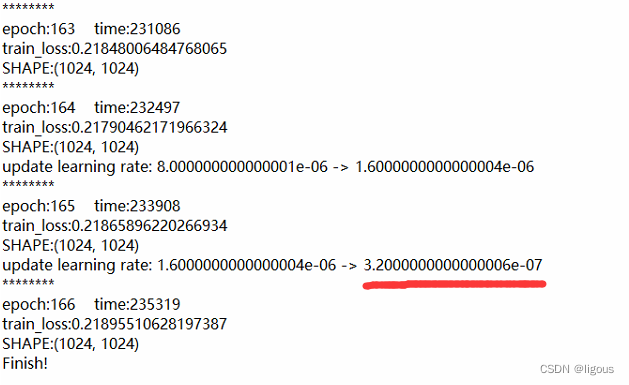
学习率已经到达了代码中训练停止的条件,结束!
源代码文件中给出的样例输出:

作者提供的样例训练了220个epoch
三、测试test
本次测试是采用原始提供的数据集,用所有的train集训练模型,然后,使用模型预测test集中的图像。
测试:

一共1244个测试图像,但是一共预测了1243个图像,最后一个没有预测,并报上述错误
发现是dataset/valid文件里最后一个数据损坏,不是正常的,删除即可。

测试预测成功:

test完成,但是好像没有其他指标什么的,因为test集中没有对应的标签图,所以,没法计算指标。
预测结果:

四、重新训练模型(正戏开始)
由于之前的训练,是将整个提供的train集进行训练,导致后续只能用test集中的数据进行预测,而无法计算指标,所以,这次训练将整个train集划分成新的train集和test集。
1. 数据准备
1.1 裁剪图像(1024—>512)
使用图像剪裁代码,把图像剪裁成512*512大小,没有overlap的图片。

图像裁剪代码(无overlap):
import os
from skimage import io, transform
import cv2
import numpy as np
image_dir = 'dataset/train'
image_list = os.listdir(image_dir)
im_sz = 512 #要分成的小块大小
step = im_sz #512 #相当于没有overlap,重叠的像素数为0
save_dir = 'dataset/train_seg'
times_all = 0
for image_name in image_list:
img,mak = None,None
if(image_name.split('.')[1] == 'jpg'):
img = io.imread(os.path.join(image_dir, image_name))
h, w, _ = img.shape
print(img.shape)
else:
mask = io.imread(os.path.join(image_dir, image_name), as_gray=True)
print(mask.shape)
h, w = mask.shape
name = image_name.split('_')[0] # 把前面的图像编号取出来
x_index = np.arange(0, h - im_sz, step).tolist() #(0,1024-1024,768)
y_index = np.arange(0, w - im_sz, step).tolist()
print(x_index)
# list[-1],表示列表最后一个元素,带负号的是从后往前找元素
# 判断最后一个分割点是不是正好能够把图像右边界分割下来,若不是,加入
if x_index[-1] != (h - im_sz):
x_index.append(h - im_sz)
if y_index[-1] != (w - im_sz):
y_index.append(w - im_sz)
# enumerate(),从0开始,0、1、2、3·····
for ind_x, col in enumerate(x_index):
for ind_y, row in enumerate(y_index):
if(img is not None):
patch = img[col:col + im_sz, row:row + im_sz, :]
print(col)
print(col+im_sz)
io.imsave(f'{save_dir}/{name}_{ind_x}_{ind_y}_sat.jpg', patch)
else:
patch_gt = mask[col:col + im_sz, row:row + im_sz]
io.imsave(f'{save_dir}/{name}_{ind_x}_{ind_y}_mask.png', patch_gt)以上代码,某些部分需要根据自己的需求,比如路径,进行修改。
1.2 划分数据集
注:由于deepglobe是比赛数据集,只有train集是包含sat和mask的,故本文是将train集作为初始数据集,重新划分为train、valid两个数据集,分别用于训练与测试
512*512大小的图片,下面列的数据集中图片的数量是sat + mask 一共的数量。
train :valid = 44832 :4976
注意:根据代码中,test.py的设置,需要将valid集中的sat和mask分开到两个文件夹中,如下所示:

2. 训练模型
参数等和三中设置差不多。
训练日志:

3. 预测
3.1 预测的结果:
使用的是用512大小的图片训练的模型。
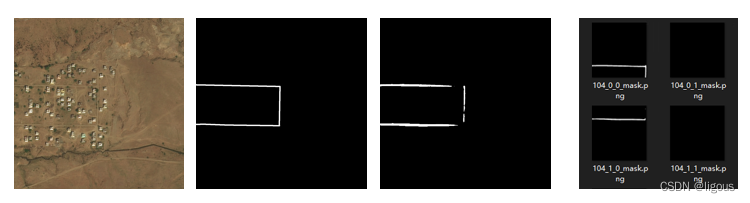
上面图片所示依次是:
sat,mask,预测1024*1024的结果,预测512*512的结果。
3.2 得到的指标:
| 大小 | 数据量 | Acc | O_IOU | 1_IOU | MIOU |
| 1024*1024 | 622 | 0.983905 | 0.982756 | 0.683513 | 0.833134 |
| 512*512 | 2488 | 0.984102 | 0.982873 | 0.643041 | 0.839141 |
本次实验就全部结束啦,整体来说,代码的改动是比较小的。
4. 评估指标代码
借鉴他人的代码,如有侵权,请告知我删除,orz orz orz
"""
refer to https://github.com/jfzhang95/pytorch-deeplab-xception/blob/master/utils/metrics.py
"""
import os
import csv
import numpy as np
import cv2
__all__ = ['SegmentationMetric']
"""
confusionMetric # 注意:此处横着代表预测值,竖着代表真实值,与之前介绍的相反
P\L P N
P TP FP
N FN TN
"""
class SegmentationMetric(object):
def __init__(self, numClass):
self.numClass = numClass
self.confusionMatrix = np.zeros((self.numClass,) * 2) # 混淆矩阵(空)
def pixelAccuracy(self):
# return all class overall pixel accuracy 正确的像素占总像素的比例
# PA = acc = (TP + TN) / (TP + TN + FP + TN)
acc = np.diag(self.confusionMatrix).sum() / self.confusionMatrix.sum()
return acc
def classPixelAccuracy(self):
# return each category pixel accuracy(A more accurate way to call it precision)
# acc = (TP) / TP + FP
classAcc = np.diag(self.confusionMatrix) / self.confusionMatrix.sum(axis=1)
return classAcc # 返回的是一个列表值,如:[0.90, 0.80, 0.96],表示类别1 2 3各类别的预测准确率
def meanPixelAccuracy(self):
"""
Mean Pixel Accuracy(MPA,均像素精度):是PA的一种简单提升,计算每个类内被正确分类像素数的比例,之后求所有类的平均。
:return:
"""
classAcc = self.classPixelAccuracy()
meanAcc = np.nanmean(classAcc) # np.nanmean 求平均值,nan表示遇到Nan类型,其值取为0
return meanAcc # 返回单个值,如:np.nanmean([0.90, 0.80, 0.96, nan, nan]) = (0.90 + 0.80 + 0.96) / 3 = 0.89
def IntersectionOverUnion(self):
# Intersection = TP Union = TP + FP + FN
# IoU = TP / (TP + FP + FN)
intersection = np.diag(self.confusionMatrix) # 取对角元素的值,返回列表
union = np.sum(self.confusionMatrix, axis=1) + np.sum(self.confusionMatrix, axis=0) - np.diag(
self.confusionMatrix) # axis = 1表示混淆矩阵行的值,返回列表; axis = 0表示取混淆矩阵列的值,返回列表
IoU = intersection / union # 返回列表,其值为各个类别的IoU
return IoU
def meanIntersectionOverUnion(self):
mIoU = np.nanmean(self.IntersectionOverUnion()) # 求各类别IoU的平均
return mIoU
def genConfusionMatrix(self, imgPredict, imgLabel): #
"""
同FCN中score.py的fast_hist()函数,计算混淆矩阵
:param imgPredict:
:param imgLabel:
:return: 混淆矩阵
"""
# remove classes from unlabeled pixels in gt image and predict
mask = (imgLabel >= 0) & (imgLabel < self.numClass)
label = self.numClass * imgLabel[mask] + imgPredict[mask]
count = np.bincount(label, minlength=self.numClass ** 2)
confusionMatrix = count.reshape(self.numClass, self.numClass)
# print(confusionMatrix)
return confusionMatrix
def Frequency_Weighted_Intersection_over_Union(self):
"""
FWIoU,频权交并比:为MIoU的一种提升,这种方法根据每个类出现的频率为其设置权重。
FWIOU = [(TP+FN)/(TP+FP+TN+FN)] *[TP / (TP + FP + FN)]
"""
freq = np.sum(self.confusion_matrix, axis=1) / np.sum(self.confusion_matrix)
iu = np.diag(self.confusion_matrix) / (
np.sum(self.confusion_matrix, axis=1) + np.sum(self.confusion_matrix, axis=0) -
np.diag(self.confusion_matrix))
FWIoU = (freq[freq > 0] * iu[freq > 0]).sum()
return FWIoU
def addBatch(self, imgPredict, imgLabel):
assert imgPredict.shape == imgLabel.shape
self.confusionMatrix += self.genConfusionMatrix(imgPredict, imgLabel) # 得到混淆矩阵
return self.confusionMatrix
def reset(self):
self.confusionMatrix = np.zeros((self.numClass, self.numClass))
# 测试内容
if __name__ == '__main__':
pre_dir = './pre'
mask_dir = './mask'
im_list = os.listdir(pre_dir)
# with open(f'./result.csv', 'w') as f:
# csv_writer = csv.writer(f)
# csv_writer.writerow(['image_name','Acc','0_IOU','1_IOU','MIOU'])
# f.close()
all_acc = 0
all_iou = 0
all_miou = 0
for im_name in im_list:
imgPredict = cv2.imread(os.path.join(pre_dir, im_name))
imgLabel = cv2.imread(os.path.join(mask_dir, im_name.split('.')[0] + '.tif'))
imgPredict = np.array(cv2.cvtColor(imgPredict, cv2.COLOR_BGR2GRAY) / 255., dtype=np.uint8)
imgLabel = np.array(cv2.cvtColor(imgLabel, cv2.COLOR_BGR2GRAY) / 255., dtype=np.uint8)
# imgPredict = np.array([0, 0, 1, 1, 2, 2]) # 可直接换成预测图片
# imgLabel = np.array([0, 0, 1, 1, 2, 2]) # 可直接换成标注图片
metric = SegmentationMetric(2) # 2表示有2个分类,有几个分类就填几
hist = metric.addBatch(imgPredict, imgLabel)
pa = metric.pixelAccuracy()
cpa = metric.classPixelAccuracy()
mpa = metric.meanPixelAccuracy()
IoU = metric.IntersectionOverUnion()
mIoU = metric.meanIntersectionOverUnion()
txt_name = im_name.split('.')[0]
all_acc+=pa
all_iou+= IoU[1]
all_miou+=mIoU
# with open(f'./result.csv', 'a',newline='') as f:
# csv_writer = csv.writer(f)
# csv_writer.writerow([txt_name, pa, IoU[0], IoU[1], mIoU])
# f.close()
# print('hist is :\n', hist)
# print('PA is : %f' % pa)
# print('cPA is :', cpa) # 列表
# print('mPA is : %f' % mpa)
# print('IoU is : ', IoU)
# print('mIoU is : ', mIoU)
五、代码中的一些小知识
下图是dlinknet中使用的数据增强:
水平翻转、垂直翻转、对角翻转、色彩抖动、图像移位、缩放。















 3179
3179











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









