







第一章:机器学习基本概念(附代码)
第二章:KNN算法:从思想到实现(附代码)
第三章:决策树算法:从思想到实现(附代码)
第四章:机器学习简单案例:如何预测客户是否流失(附代码)
第五章:理解数据标准化处理
第六章:线性模型:从原理到实践
第七章:KMeans 聚类算法:从理论到实践(附代码)
第八章:搞懂线性回归与梯度下降原理(附代码)
第九章:深度学习框架PyTorch
第十章:逻辑回归:从基础到实践(附代码)
第十一章:集成学习(一):从理论到实战(附代码)
第十二章:集成学习(二):从理论到实战(附代码)
第十三章:机器学习算法大比武(附代码)
第十四章:理解并解决欠拟合与过拟合
第十五章:机器学习案例:幸福感指数预测
KMeans 是一种广泛使用的聚类算法,它简单易用且高效。本文介绍 KMeans 算法的基本概念、工作原理,并通过一个具体的案例来展示如何使用 Python 实现 KMeans 聚类。
一、基本概念
1.1 什么是聚类?
聚类是一种无监督学习方法,用于将数据集中的样本按照相似性分成多个组或类别。与有监督学习不同的是,聚类算法处理的数据没有标签,仅根据特征进行分类。
1.2 KMeans 的核心思想
- K:代表你希望将数据分为多少个簇(类别)。
- Mean:指的是每个簇的中心点(质心),即簇内所有点的平均值。
- s:迭代式算法,KMeans 是一个迭代过程,最终结果可能受到初始质心选择的影响,因此存在一定的不稳定性。
二、示例代码解析
通过一个简单的示例来演示如何使用 KMeans 进行聚类分析。
# 导入必要的包
from sklearn.datasets import make_blobs
from matplotlib import pyplot as plt
from sklearn.cluster import KMeans
# 创建模拟数据集
# 使用 `make_blobs` 函数生成一个模拟数据集,
# 该数据集包含 1000 个样本,每个样本有两个特征,数据被分成 4 类。
X, y = make_blobs(n_samples=1000,
n_features=2,
centers=4,
cluster_std=0.5,
random_state=0)
# 绘制生成的数据集
plt.scatter(x=X[:, 0], y=X[:, 1], c=y)
plt.title("Original Data")
plt.show()

# 使用 KMeans 进行聚类
# 首先实例化一个 KMeans 对象,并指定我们需要将其分成 4 类。
km = KMeans(n_clusters=4) # 设置期望的簇数量
# 然后对数据进行训练:
km.fit(X=X)
# 获取每个簇的中心点:
centers = km.cluster_centers_
# 可视化聚类结果
# 绘制出原始数据点和计算出的簇中心点。
plt.scatter(x=X[:, 0], y=X[:, 1], c=km.labels_)
plt.scatter(x=centers[:, 0], y=centers[:, 1], c="red", marker="*", s=200) plt.title("Clustered Data with Centers")
plt.show()
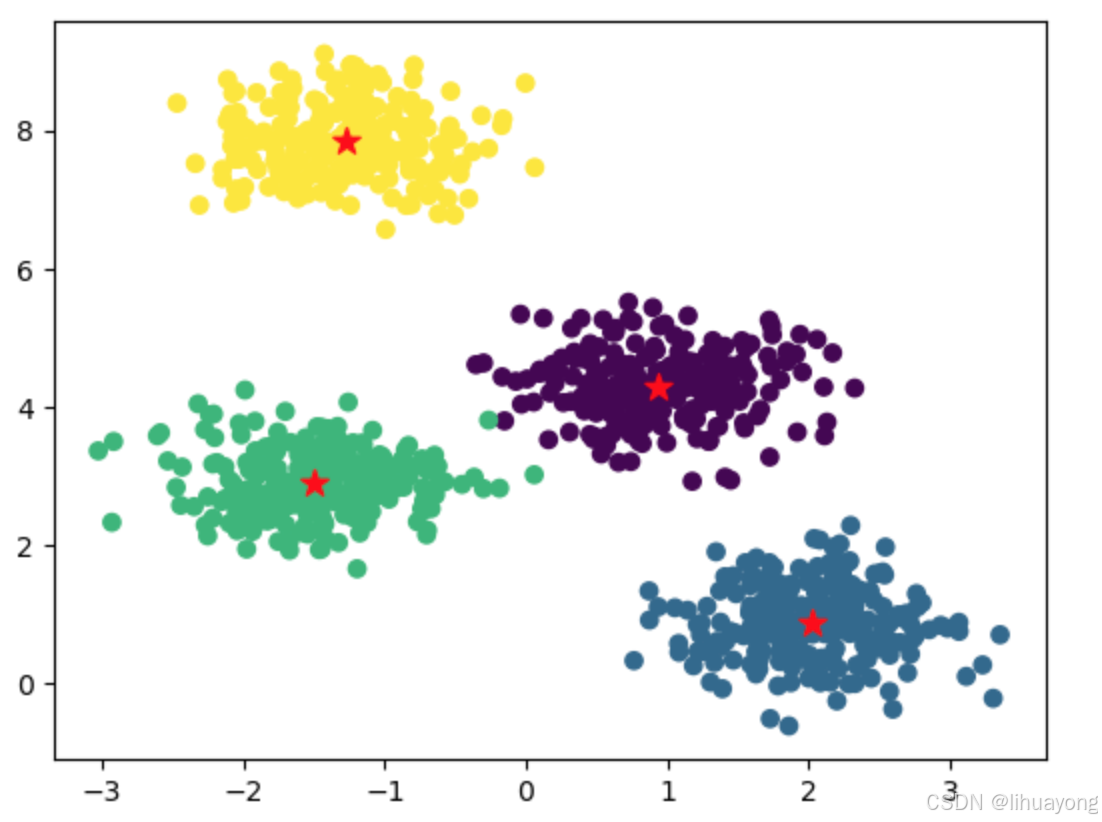
make_blobs 函数是来自 sklearn.datasets 模块的一个用于生成模拟数据集的函数。它非常适合用来创建一些测试算法效果的数据,尤其是在聚类、分类等任务中用来验证方法的有效性。
下面是 make_blobs 函数的一些关键参数说明:
n_samples:指定要生成的样本总数,默认值为 100。你可以设置一个整数来定义总样本数,或者提供一个整数列表以对每个中心点(类别)指定不同的样本数。n_features:指定每个样本的特征数量,默认值为 2。这意味着生成的数据将有多个维度,对于二维平面中的可视化来说,通常设置为 2。centers:指定生成数据的中心点的数量或位置。可以是一个整数,指定了簇的个数,并且会随机生成相应数量的中心点;也可以是一个数组,指定了各个中心点的具体坐标。cluster_std:簇的标注差,控制簇的分散程度。默认值为 1.0,你可以提供一个浮点数或数组。如果是数组,则其长度应与中心点数量相同,分别对应每个簇的标准差。random_state:控制随机状态,使结果可重复。如果使用相同的 random_state 和参数,那么每次运行时都会生成相同的数据集。
通过上述步骤,使用 KMeans 算法对一组数据进行了聚类分析,并可视化了聚类的结果。值得注意的是,KMeans 的性能在很大程度上取决于初始质心的选择以及数据本身的分布情况。此外,选择合适的 K 值(即簇的数量)对于获得有意义的聚类结果至关重要。
KMeans 算法是一种常用的聚类算法,它通过计算数据点之间的距离来将相似的数据点分组到一起。KMeans 可以用来解决多种问题,尤其是在需要对大量数据进行分类但又没有预先定义好的类别标签时尤为有用。
典型应用场景
| 应用领域 | 解决的问题 | 数据特征 |
|---|---|---|
| 市场分析 | 客户细分与精准营销 | 购买行为、用户画像数据 |
| 图像处理 | 图像压缩与色彩量化 | 像素颜色值(RGB) |
| 生物信息学 | 基因表达模式分类 | 基因在不同样本中的表达量 |
| 城市规划 | 交通热点区域识别 | 车辆GPS坐标数据 |
| 网络安全 | 异常流量检测 | 网络请求特征(频率、时长等) |
三、案例1:客户细分
假设你是一家在线零售商店的市场分析师,你的任务是根据客户的购买行为来进行客户细分,以便为不同的客户群体设计针对性的营销策略。然而,你并没有现成的客户类别或标签可用。这时,你可以使用 KMeans 算法对客户进行聚类分析。
数据收集
首先,需要收集相关数据。对于这个案例来说,可以考虑以下几种特征:
- 购买频率F(Frequency):客户在一定时间内的购买次数。
- 最近一次购买的时间R(Recency):从当前日期到客户最后一次购买的时间间隔。
- 平均消费金额M(Monetary):每个客户的平均消费额。
这些数据可以从你的销售数据库中提取得到。
应用 KMeans 进行聚类
-
选择合适的K值:即你想将客户分成几个群组。这可能需要一些试验和领域知识。例如,你可能会尝试将客户分为3个群组(新客户、活跃客户、流失客户)。
-
标准化数据:由于不同特征的量纲可能不同,因此在应用 KMeans 之前应该对数据进行标准化处理,确保每个特征对最终的距离计算有相同的贡献度。
数据示例(标准化后):
用户ID R F M 001 0.12 1.85 2.30 002 2.45 0.32 0.15 003 1.23 1.02 1.78 -
执行 KMeans 聚类:
from sklearn.cluster import KMeans
# 假设data是一个包含上述特征的DataFrame
# 设置期望的群集数量
kmeans = KMeans(n_clusters=3)
# 使用 KMeans 模型对数据进行聚类,并将每个样本所属的簇(cluster)标签添加到数据集中
data['cluster'] = kmeans.fit_predict(data[['F', 'R', 'M']])
-
kmeans.fit_predict(…):这是 KMeans 模型的一个方法,它执行两步操作:
- 首先,根据输入的数据 X 训练模型(即找到最佳的簇中心),这个过程称为“拟合”(fit)。
- 然后,基于训练好的模型对输入数据中的每个样本分配一个簇标签,这个过程称为“预测”(predict)。
- 最终返回的是一个与输入数据样本数量相同长度的一维数组,其中每个元素表示对应样本所属的簇编号(从0开始计数)。
-
data[[‘F’, ‘R’, ‘M’]] 是传入 fit_predict 方法的数据集,包含了用于聚类分析的特征列:购买频率(F)、最近一次购买的时间(R)、平均消费金额(M)。
-
data[‘cluster’] = …这一部分将上一步骤中得到的每个样本的簇标签存储回原始的 data 数据框中,作为一个新的列 ‘cluster’。这样做可以直观地看到每个样本被分配到了哪个簇,并且便于后续的分析或可视化工作。
- 结果分析与营销策略制定:一旦模型完成训练,你就可以检查每个群集中的客户特征,并据此制定相应的营销策略。例如,针对“活跃客户”群集,可以设计忠诚度计划;而对于“流失客户”,则可以提供特别折扣以吸引他们重新购物。
- 高价值客户群(Cluster 0):近期活跃、消费频繁、金额高 → 推送VIP专属折扣
- 流失风险群(Cluster 1):长期未消费 → 触发唤醒优惠券
- 潜力用户群(Cluster 2):中等消费频次 → 推荐关联商品
四、案例2:图像颜色压缩(图像处理)
场景需求:
将一张彩色图片压缩为256色,减小存储空间。
实现原理:
- 将每个像素的RGB值视为三维空间中的点
- 使用KMeans将全部像素颜色聚类为256个代表色
- 用聚类中心颜色替换原始像素颜色
代码实现:
from sklearn.cluster import KMeans
import numpy as np
from PIL import Image
# 加载图片并转换格式
image = Image.open("transformer架构图.png")
# 将图像转换为numpy数组
pixels = np.array(image)
# 检查图像是否为RGB格式,如果不是,转换为RGB
if len(pixels.shape) == 2 or pixels.shape[2] != 3:
image = image.convert("RGB")
pixels = np.array(image)
# 将像素数组重塑为(N, 3)格式
pixels = pixels.reshape(-1, 3)
# 聚类压缩颜色
kmeans = KMeans(n_clusters=256, random_state=42)
kmeans.fit(pixels)
compressed_pixels = kmeans.cluster_centers_[kmeans.labels_]
# 重建图片
compressed_image = compressed_pixels.reshape(image.size[1], image.size[0], 3)
Image.fromarray(compressed_image.astype(np.uint8)).save("compressed.jpg")
效果对比:
| 指标 | 原始图像 | 压缩后图像 |
|---|---|---|
| 颜色数量 | 16,777,216 | 256 |
| 文件大小 | 2.3 MB | 0.8 MB |
| 视觉差异 | 无压缩 | 几乎不可察觉 |
五、案例3:交通热点识别(城市规划)
场景需求:
通过出租车GPS数据,识别城市中的高频上下车区域,优化充电桩布局。
数据处理流程:
- 收集出租车上下车坐标(经度、纬度)
- 坐标数据标准化(消除地理尺度差异)
- 使用KMeans聚类识别热点区域
结果应用:
import folium # 地图可视化库
# 假设centers是KMeans输出的聚类中心坐标
hotspots = folium.Map(location=[31.2304, 121.4737], zoom_start=12) # 以上海为中心
for center in kmeans.cluster_centers_:
folium.CircleMarker(
location=[center[0], center[1]],
radius=50,
color='red',
fill=True
).add_to(hotspots)
hotspots.save("hotspots.html")
输出效果:
在地图上标记出5个主要热点区域,政府据此在这些区域增设充电桩,使出租车充电效率提升40%。
六、总结
KMeans 是一种经典的无监督学习算法,擅长发现数据中潜在的自然分组。它通过迭代优化将数据划分为指定数量的簇(cluster),每个簇内的数据具有高相似性,不同簇间差异显著。

















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









