







 本文详细指导如何利用腾讯云的HAI服务搭建一个支持多音色的文本转语音(TTS)系统,包括登录HAI控制台、设置AI框架、安装依赖、克隆代码库、运行UI界面和API服务的过程。
本文详细指导如何利用腾讯云的HAI服务搭建一个支持多音色的文本转语音(TTS)系统,包括登录HAI控制台、设置AI框架、安装依赖、克隆代码库、运行UI界面和API服务的过程。
在这篇文章中,我们将介绍如何使用腾讯云的高性能应用服务(HAI)来搭建一个具有多音色控制的文本转语音(TTS)引擎,具体操作步骤如下:
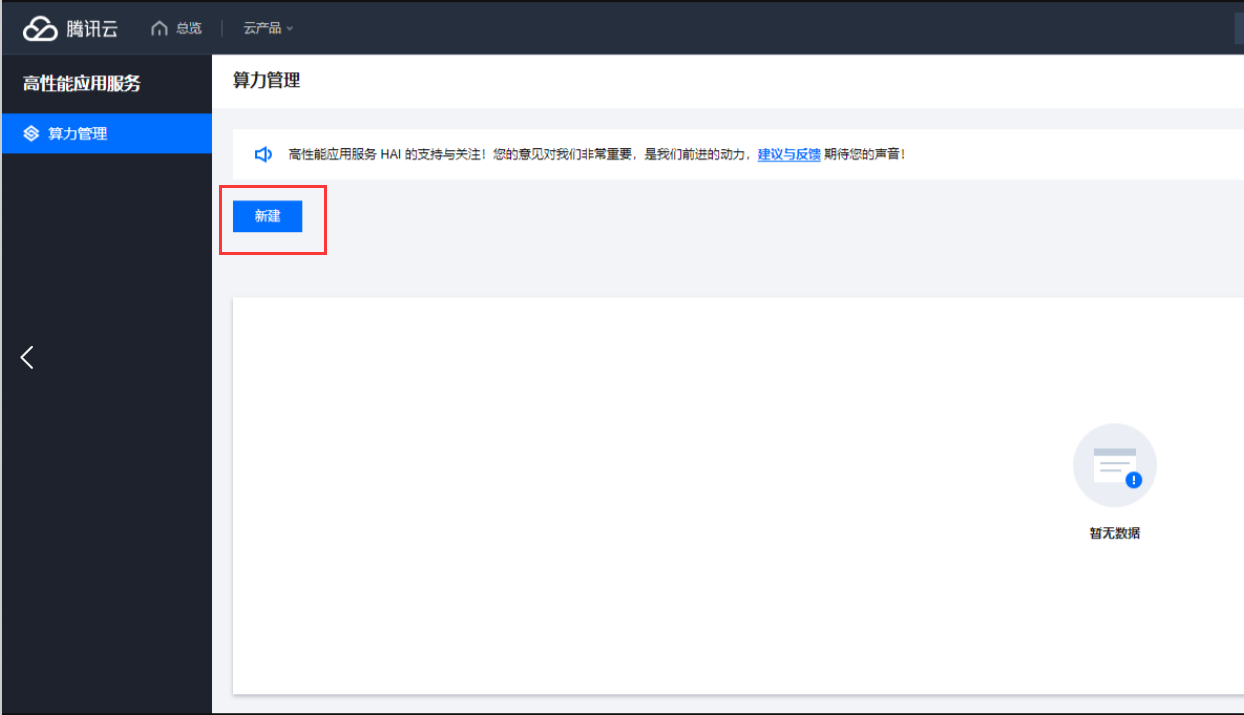
点击 新建 选择 AI 框架,选择算力方案、输入 实例名称、选择数量 后立即购买
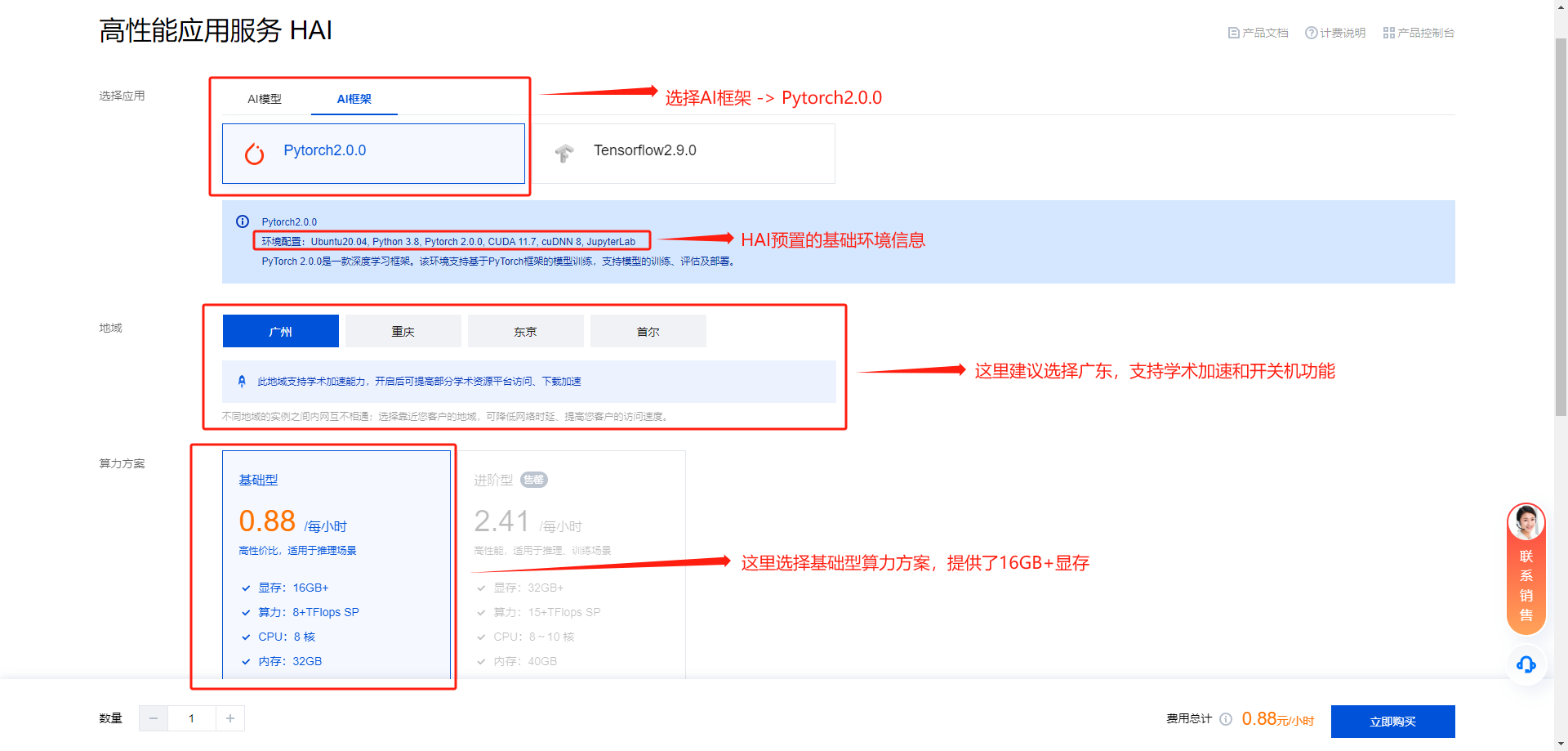
开启学术加速功能
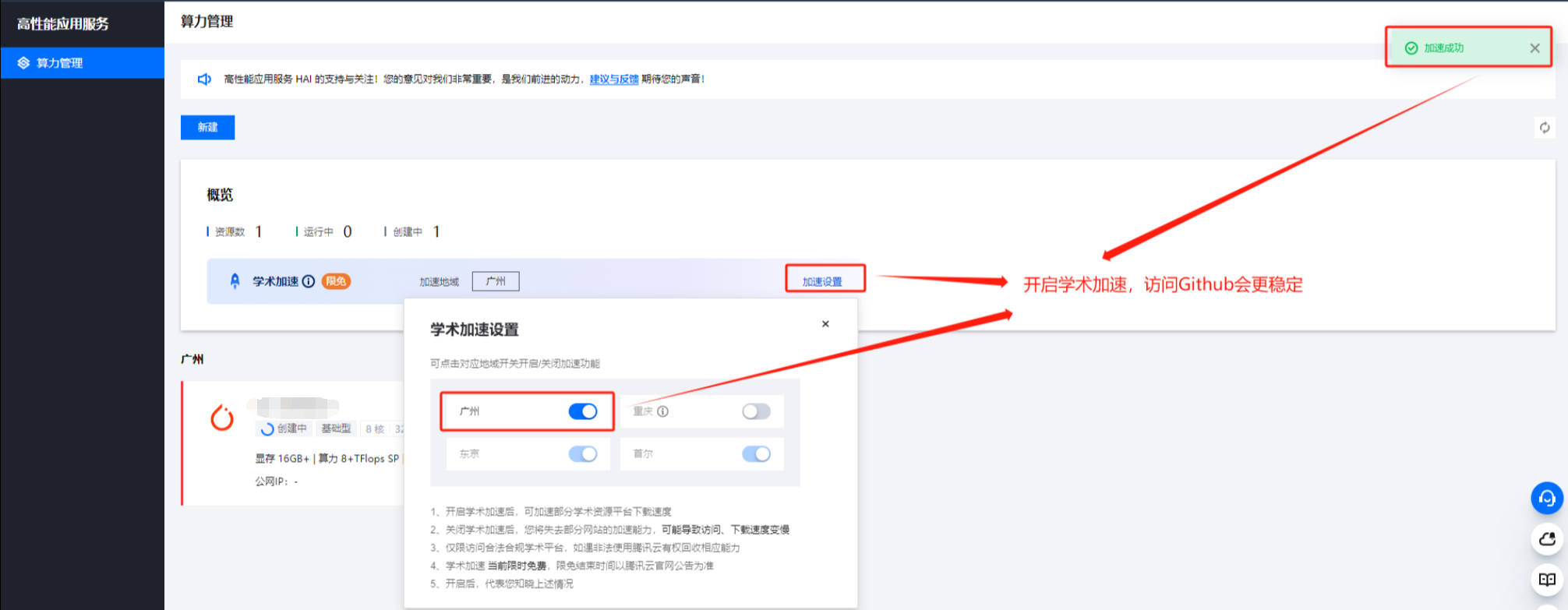
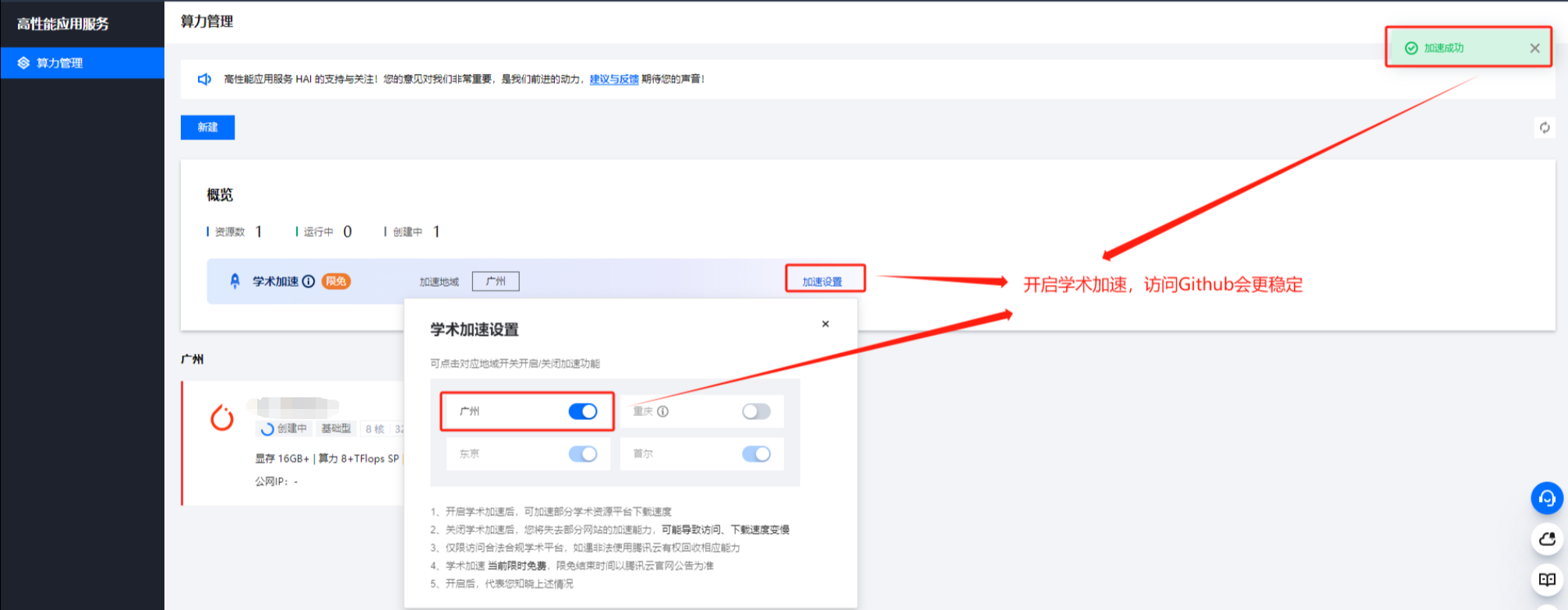
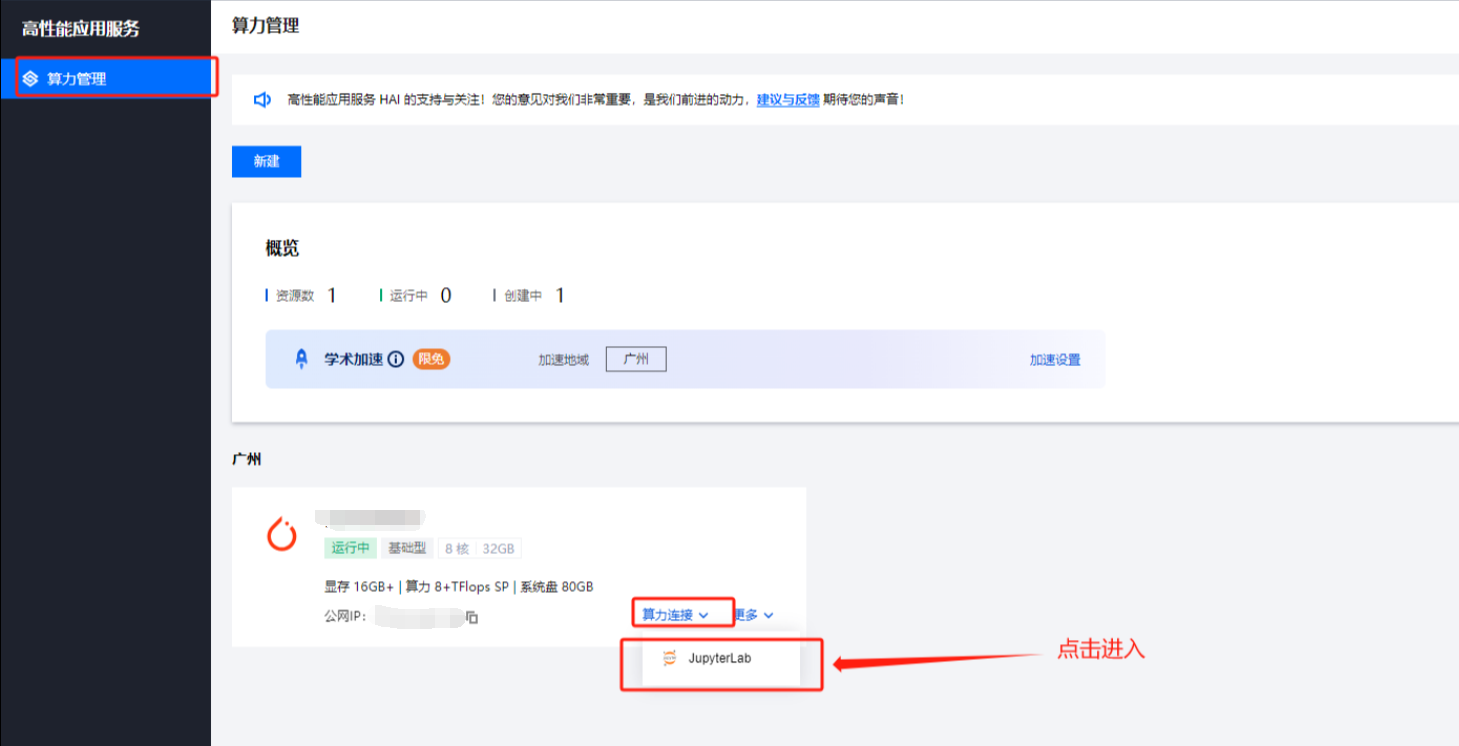
完成创建,查看运行状态
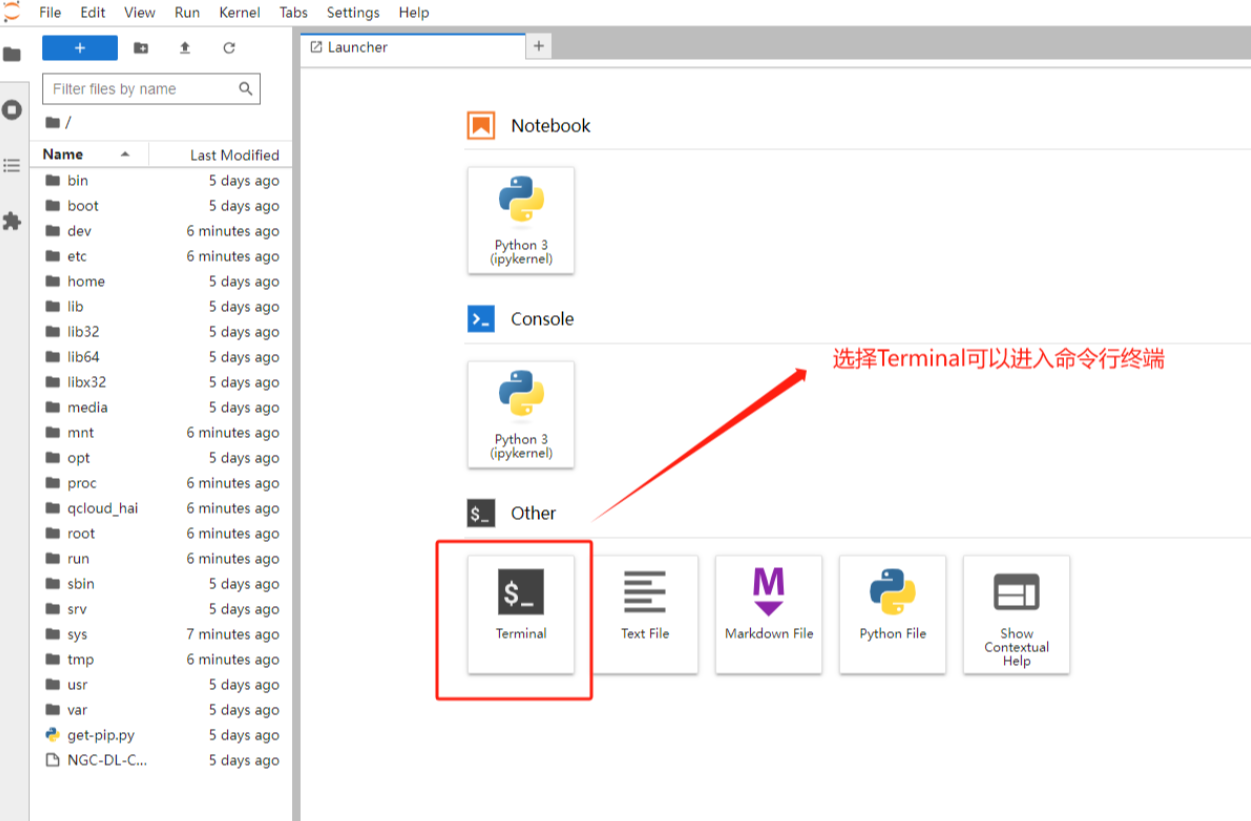
进入 jupyter_lab 环境
安装 git-lfs:
apt-get clean && apt-get update
apt-get install git-lfs
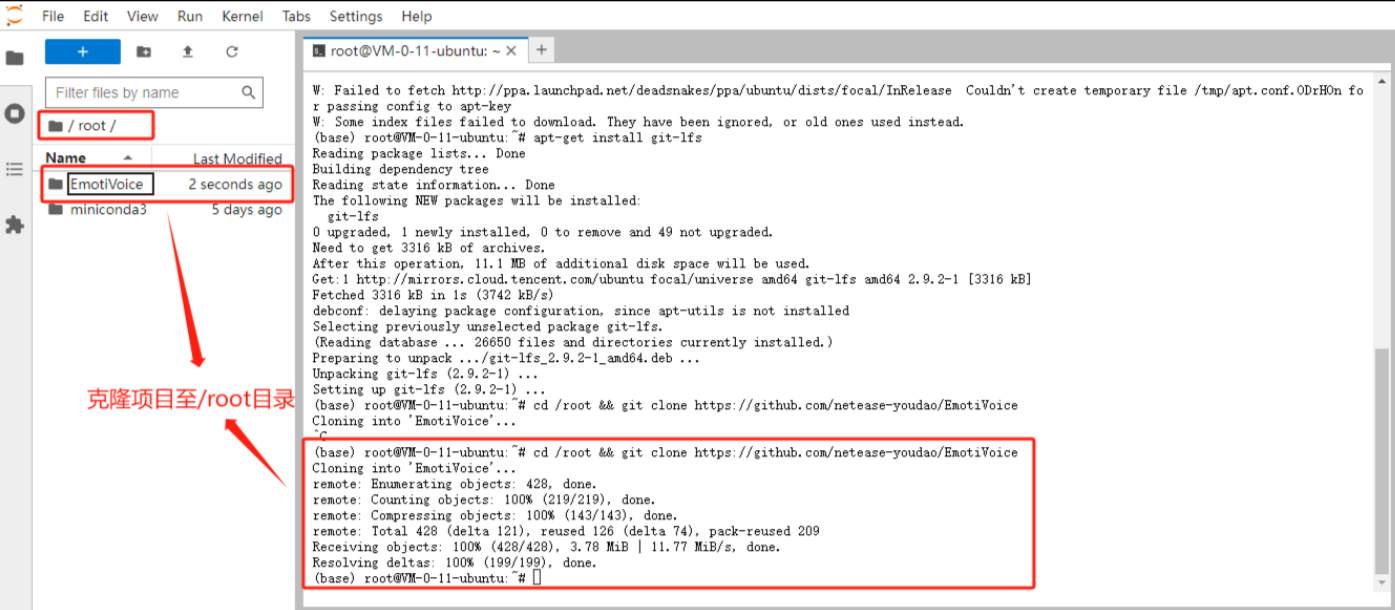
克隆 EmotiVoice 仓库:
cd /root && git clone https://github.com/netease-youdao/EmotiVoice
下载预训练模型文件:
cd /root/EmotiVoice
git lfs install
git lfs clone https://www.modelscope.cn/syq163/WangZeJun.git
下载 ckpt 模型:
cd /root/EmotiVoice
git lfs clone https://www.modelscope.cn/syq163/outputs.git
安装 EmotiVoice 依赖:
pip install numpy numba scipy transformers==4.26.1 soundfile yacs g2p_en jieba pypinyin
运行 UI 交互界面:
pip install streamlit
cd /root/EmotiVoice && streamlit run demo_page.py --server.port 6889 --logger.level debug
启动命令中的 6889 端口是 高性能应用服务默认开放的端口之一,如果修改了启动命令中的端口,需要手动配置 HAI 的安全组策略,将服务端口放行
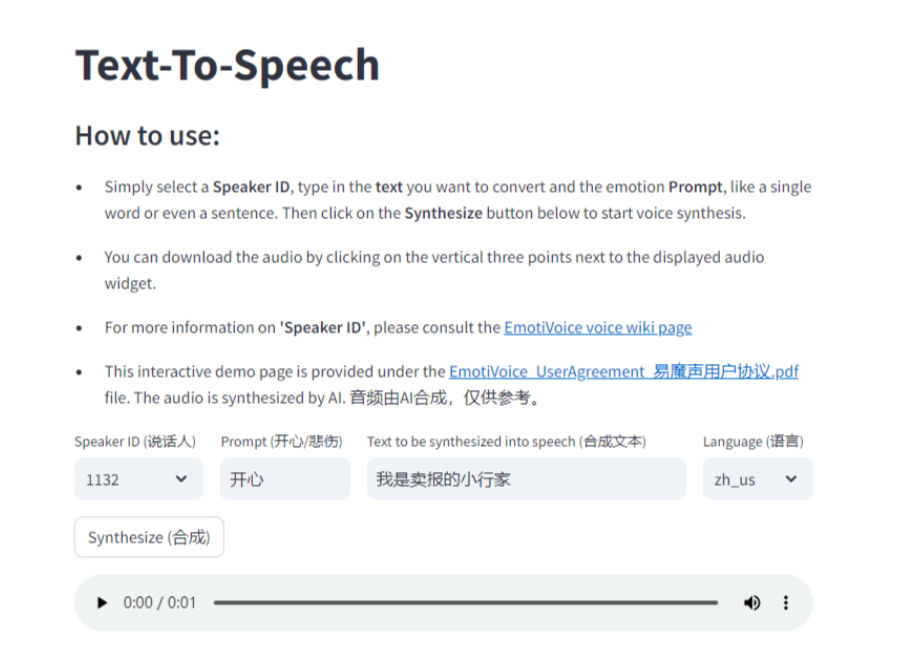
运行类 OpenAI TTS 的 API
# 安装ffmpeg
apt-get clean && apt-get update
apt-get install ffmpeg
# 安装API所需的依赖
pip install fastapi
pip install pydub
pip install uvicorn[standard]
# 运行服务
cd /root/EmotiVoice
uvicorn openaiapi:app --reload --host 0.0.0.0 --port 6006
启动后可以通过/docs 查看接口文档

















 1539
1539

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









