






- 本科会计跨专业应用统计研1-自学ing
痛苦day1
新手使用CSDN 多多包涵
看到有大佬的学习笔记,感觉这样比干看书要方便很多,决定效仿一下。

数据挖掘课老师说接下来会用python学 这部分做参考8
全书脉络:
- 第一部分
- 第一章:熟悉R环境
- 第二章:从R中导入数据
- 第三章:图形绘制
- 第四章:基本数据管理
- 第五章:数据管理中数值函数和字符处理函数的使用-控制结构
第一章
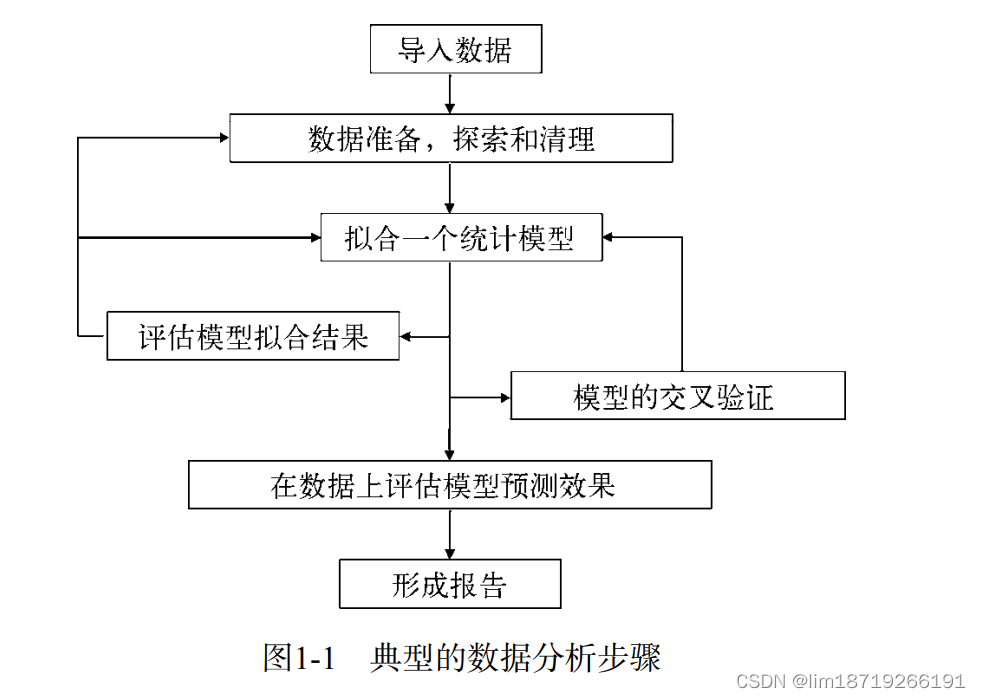
基本应用
- 赋值:<-
- 注释:#
-
帮助函数

工作空间

setwd("C:/myprojects/project1")
# 这个不知道为什么设置不了 可能是C盘限制,改成D盘即可
> dir.create("D:/Rstudy")
#可以使用函数dir.create()来创建新目录,然后使用setwd()将工作目录指向这个新目录。
> setwd("D:/Rstudy")
> getwd()
[1] "D:/Rstudy"
# 下面附setwd()和getwd()的相关笔记
options()
# 当前的选项设置情况将显示出来
options(digits=3)
# 显示为小数点后三位有效数字
x <- runif(20)
# 创建了一个包含20个均匀分布随机变量的向量
summary(x) # 数据摘要
hist(x) # 直方图
q()
# 当q()函数被运行的时候,程序将向用户询问是否保存工作空间。如果用户输入y,命令的历史记录保存到文件.Rhistory中,工作空间(包含向量x)保存到当前目录中的文件.RData中,会话结束,R程序退出。- 路径用正斜杠/
- 转义符:\
- setwd()不能生成新路径,要用dir.create()
R学习笔记之:setwd()与getwd() - 知乎 (zhihu.com)![]() https://zhuanlan.zhihu.com/p/29150673
https://zhuanlan.zhihu.com/p/29150673
在独立的目录中保存项目是一个好主意。你也许会在启动一个R会话时使用setwd()命令指 定到某一个项目的路径,后接不加选项的load(".RData")命令。这样做可以让你从上一次会话 结束的地方重新开始,并保证各个项目之间的数据和设置互不干扰。
这个怎么理解呢?
一个对话示例:
> age <- c(1,3,5,2,11,9,3,9,12,3)
> weight <- c(4.4,5.3,7.2,5.2,8.5,7.3,6.0,10.4,10.2,6.1)
> mean(weight)
[1] 7.06
> sd(weight)
[1] 2.077498
> cor(age,weight) #相关度
[1] 0.9075655
> plot(age,weight) #图形显示关系,用可视化的方式检查可能存在的趋势
> q()1.3.4 输入与输出
- 输入
source("filename")
# 可在当前会话中执行一个脚本。如果文件名中不包含路径,R将假设此脚本在当前工作目录中
source("myscript.R")
# 将执行包含在文件myscript.R中的R语句集合- 文字输出(并不影响图像)
sink("filename") #将输出重定向到文件filename
# 默认状态:覆盖原文件内容
append=TRUE
# 将文本追加到文件后,而不是覆盖
split=TRUE
# 将输出【同时】发送到屏幕和输出文件
sink()
# 不加参数:仅向屏幕返回输出结果- 图像输出

汇总示例
source("script1.R")
#执行1且显示在屏幕
sink("myoutput", append=TRUE, split=TRUE)
pdf("mygraphs.pdf")
source("script2.R")
# 执行script2.R,显示在屏幕上,且文本输出追加到文件myoutput后,图形输出保存为mygraphs.pdf
sink()
dev.off()
source("script3.R")
# 执行script3.R,结果显示在屏幕,没有文本或图形输出1.4 包
下载路径:http://cran.r-project.org/ web/packages
- 包是R函数、数据、预编译代码以一种定义完善的格式组成的集合。
- 存储包的目录 称为库(library)。
-
libPaths() # 能够显示库所在的位置 library() # 则可以显示库中有哪些包。 search() # 可以告诉你哪些包已加载并可使用 install.packages() # 安装需要的包 installed.packages() # 查看已安装的包的描述 update.packages() # 更新已经安装的包 library() # 命令载入这个包。例如,要使用gclus包,执行命令library(gclus)即可 help(package="package_name") # 输出某个包的简短描述以及包中的函数名称和数据集名称的列表。 help() # 可以查看其中任意函数或数据集的更多细节。这些信息也能以PDF帮助手册的形式从CRAN下载。常见错误
- 错误的大小写
- 忘记"":比如,install.packages("vcd"),写成了install.packages(vcd) 【注意,载入该包不需要双引号,library(vcd)即可】
- 函数调用需要加()
- 在Windows上,路径名中使用了\。R将反斜杠视为一个转义字符。 setwd("c:\mydata")会报错。正确的写法是setwd("c:/mydata")或 setwd("c:\\mydata")
- 使用了一个尚未载入包中的函数。函数order.clusters()包含在包gclus中。如果还 没有载入这个包就使用它,将会报错。
1.5 (没搞定)批处理:要以一种重复的、标准化的、无人值守的方式执行某个R程序
例如,你可能 需要每个月生成一次相同的报告,这时就可以在R中编写程序,在批处理模式下执行它。
对于Windows,则需使用:
"C:\Program Files\R\R-3.1.0\bin\R.exe" CMD BATCH
➥ --vanilla --slave "c:\my projects\myscript.R"将路径调整为R.exe所在的相应位置和脚本文件所在位置。
要进一步了解如何调用R,包括命令行 选项的使用方法,请参考CRAN(http://cran.r-project.org)上的文档“Introduction to R”(已经下载至桌面了)
1.6 将输出用为输入:结果的重用
# 保存简单线性回归的结果
lm(mpg~wt, data=mtcars)
lmfit <- lm(mpg~wt, data=mtcars) #保存
summary(lmfit) #显示统计概要,这时候显示的是前面保存的lmfit,也可以直接引用
plot(lmfit) #生成回归诊断图形
cook<-cooks.distance(lmfit) #计算和保存影响度量统计量
plot(cook)
predict(lmfit,mynewdata) # 应用lmfit来预测新数据
如果要了解某个函数返回值:help(lm) 或?lm,再找value部分,就知道这个命令返回了什么
1.8 本章示例
(1) 打开帮助文档首页,并查阅其中的“Introduction to R”
(2) 安装vcd包(一个用于可视化类别数据的包,你将在第11章中使用)。
(3) 列出此包中可用的函数和数据集。
(4) 载入这个包并阅读数据集Arthritis的描述。
(5) 显示数据集Arthritis的内容(直接输入一个对象的名称将列出它的内容)。
(6) 运行数据集Arthritis自带的示例。如果不理解输出结果,也不要担心。它基本上显示 了接受治疗的关节炎患者较接受安慰剂的患者在病情上有了更多改善。
(7) 退出
help.start() # 打开帮助文档
install.packages("vcd")
help(package="vcd")
library(vcd)
# 注意区别啥时候用"",啥时候不用
help(Arthritis)
# 阅读数据集的描述
Arthritis
# 显示数据集
example(Arthritis)
# 运行数据集自带的示例
q() 














 1464
1464











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









