







深度学习领域有哪些瓶颈:
https://www.zhihu.com/question/40577663
一片欣欣向荣背后,深度学习在计算机视觉领域的瓶颈已至。提出这个观点的,不是外人,正是计算机视觉奠基者之一,约翰霍普金斯大学教授Alan Yuille,他还是霍金的弟子。他说,现在做AI不提神经网络,成果都很难发表了,这不是个好势头。如果人们只追神经网络的潮流,抛弃所有老方法;如果人们只会刷榜,不去想怎样应对深度网络的局限性,这个领域可能很难有更好的发展。

面对深度学习的三大瓶颈,Yuille教授给出两条应对之道:靠组合模型培养泛化能力,用组合数据测试潜在的故障。观点发表之后,引发不少的共鸣。Reddit话题热度快速超过200,学界业界的AI科学家们也纷纷在Twitter上转发。Reddit网友评论道,以Yuille教授的背景,他比别人更清楚在深度学习在计算机视觉领域现状如何,为什么出现瓶颈。
深度学习的三大瓶颈Yuille指出,深度学习虽然优于其他技术,但它不是通用的,经过数年的发展,它的瓶颈已经凸显出来,主要有三个:
需要大量标注数据
深度学习能够实现的前提是大量经过标注的数据,这使得计算机视觉领域的研究人员倾向于在数据资源丰富的领域搞研究,而不是去重要的领域搞研究。虽然有一些方法可以减少对数据的依赖,比如迁移学习、少样本学习、无监督学习和弱监督学习。但是到目前为止,它们的性能还没法与监督学习相比。
过度拟合基准数据
深度神经网络在基准数据集上表现很好,但在数据集之外的真实世界图像上,效果就差强人意了。比如下图就是一个失败案例。
 一个用ImageNet训练来识别沙发的深度神经网络,如果沙发摆放角度特殊一点,就认不出来了。这是因为,有些角度在ImageNet数据集里很少见。在实际的应用中, 如果深度网络有偏差,将会带来非常严重的后果。要知道,用来训练自动驾驶系统的数据集中,基本上从来没有坐在路中间的婴儿。
一个用ImageNet训练来识别沙发的深度神经网络,如果沙发摆放角度特殊一点,就认不出来了。这是因为,有些角度在ImageNet数据集里很少见。在实际的应用中, 如果深度网络有偏差,将会带来非常严重的后果。要知道,用来训练自动驾驶系统的数据集中,基本上从来没有坐在路中间的婴儿。
对图像变化过度敏感
深度神经网络对标准的对抗性攻击很敏感,这些攻击会对图像造成人类难以察觉的变化,但可能会改变神经网络对一个物体的认知。而且,神经网络对场景的变化也过于敏感。比如下面的这张图,在猴子图片上放了吉他等物体,神经网络就将猴子识别成了人类,吉他识别成了鸟类。
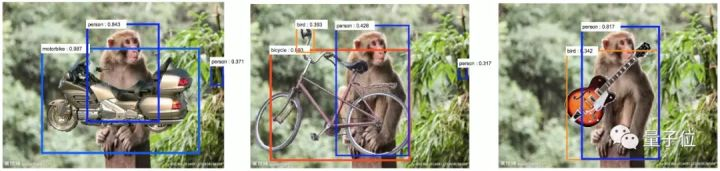
背后的原因是,与猴子相比,人类更有可能携带吉他,与吉他相比,鸟类更容易出现在丛林中。这种对场景的过度敏感,原因在于数据集的限制。对于任何一个目标对象,数据集中只有有限数量的场景。在实际的应用中,神经网络会明显偏向这些场景。对于像深度神经网络这样数据驱动的方法来说,很难捕捉到各种各样的场景,以及各种各样的干扰因素。想让深度神经网络处理所有的问题,似乎需要一个无穷大的数据集,这就给训练和测试数据集带来了巨大的挑战。
为什么数据集会不够大?
这三大问题,还杀不死深度学习,但它们都是需要警惕的信号。
Yuille说,瓶颈背后的原因,就是一个叫做“组合爆炸”的概念:就说视觉领域,真实世界的图像,从组合学观点来看太大量了。任何一个数据集,不管多大,都很难表达出现实的复杂程度。
那么,组合学意义上的大,是个什么概念?
大家想象一下,现在要搭建一个视觉场景:你有一本物体字典,要从字典里选出各种各样的物体,把它们放到不同的位置上。说起来容易,但每个人选择物体、摆放物体的方法都不一样,搭出的场景数量是可以指数增长的。就算只有一个物体,场景还是能指数增长。因为,它可以用千奇百怪的方式被遮挡;物体所在的背景也有无穷多种。人类的话,能够自然而然适应背景的变化;但深度神经网络对变化就比较敏感了,也更容易出错:
 也不是所有视觉任务都会发生组合爆炸 (Combinatorial Explosion) 。比如,医学影像就很适合用深度网络来处理,因为背景少有变化:比如,胰腺通常都会靠近十二指肠。但这样的应用并不常见,复杂多变的情况在现实中更普遍。如果没有指数意义上的大数据集,就很难模拟真实情况。而在有限的数据集上训练/测试出来的模型,会缺乏现实意义:因为数据集不够大,代表不了真实的数据分布。
也不是所有视觉任务都会发生组合爆炸 (Combinatorial Explosion) 。比如,医学影像就很适合用深度网络来处理,因为背景少有变化:比如,胰腺通常都会靠近十二指肠。但这样的应用并不常见,复杂多变的情况在现实中更普遍。如果没有指数意义上的大数据集,就很难模拟真实情况。而在有限的数据集上训练/测试出来的模型,会缺乏现实意义:因为数据集不够大,代表不了真实的数据分布。
那么,就有两个新问题需要重视:
1、怎样在有限的数据集里训练,才能让AI在复杂的真实世界里也有很好的表现?
2、怎样在有限的数据集里,高效地给算法做测试,才能保证它们承受得了现实里大量数据的考验?
组合爆炸如何应对?
数据集是不会指数型长大的,所以要试试从别的地方突破。可以训练一个组合模型,培养泛化能力。也可以用组合数据来测试模型,找出容易发生的故障。总之,组合是关键。训练组合模型组合性 (Compositionality) 是指,一个复杂的表达,它的意义可以通过各个组成部分的意义来决定。这里,一个重要的假设就是,一个结构是由许多更加基本的子结构,分层组成的;背后有一些语法规则。这就表示,AI可以从有限的数据里,学会那些子结构和语法,再泛化到各种各样的情景里。
与深度网络不同,组合模型 (Compositional Models) 需要结构化的表示方式,才能让结构和子结构更明确。组合模型的推断能力,可以延伸到AI见过的数据之外:推理、干预、诊断,以及基于现有知识结构去回答不同的问题。
在组合数据里测试模型
训练过后,该测试了。前面说过,世界那么复杂,而我们只能在有限的数据上测试算法。要处理组合数据 (Combinatorial Data) ,博弈论是一种重要的方法:它专注于最坏情况 (Worst Case) ,而不是平均情况 (Average Case) 。就像前面讨论过的那样,如果数据集没有覆盖到问题的组合复杂性,用平均情况讨论出的结果可能缺乏现实意义。而关注最坏情况,在许多场景下都是有意义的:比如自动驾驶汽车的算法,比如癌症诊断的算法。因为在这些场景下,算法故障可能带来严重的后果。
如果,能在低维空间里捕捉到故障模式 (Failure Modes) ,比如立体视觉的危险因子 (Hazard Factors) ,就能用图形和网格搜索来研究这些故障。但是对于大多数视觉任务,特别是那些涉及组合数据的任务,通常不会有能找出几个危险因子、隔离出来单独研究的简单情况。
对抗攻击:稍稍改变纹理,只影响AI识别,不影响人类
有种策略,是把标准对抗攻击 (Adversarial Attacks) 的概念扩展到包含非局部结构 (Non-Local Structure) ,支持让图像或场景发生变化的复杂运算,比如遮挡,比如改变物体表面的物理性质,但不要对人类的认知造成重大改变。把这样的方法应用到视觉算法上,还是很有挑战性的。不过,如果算法是用组合性 (Compositional) 的思路来写,清晰的结构可能会给算法故障检测带来很大的帮助。
作者:量子位
链接:https://www.zhihu.com/question/40577663/answer/729741077















 219
219











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









