高斯过程代码
import numpy as np
import sklearn.gaussian_process as gp
from scipy.stats import norm
from scipy.optimize import minimize
def expected_improvement(x, gaussian_process, evaluated_loss, greater_is_better=False, n_params=1):
"""
参数含义:
x:需要计算的点;
gaussian_process:回归对象,对评估的超参数进行训练;
evaluted_loss:numpy数组,包含损失函数值;
greater_is_better:布尔值,表示损失函数最大化还是最小化
n_params:超参数空间的维数
"""
x_to_predict = x.reshape(-1, n_params)
mu, sigma = gaussian_process.predict(x_to_predict, return_std=True)
if greater_is_better:
loss_optimum = np.max(evaluated_loss)
else:
loss_optimum = np.min(evaluated_loss)
scaling_factor = (-1) ** (not greater_is_better)
with np.errstate(divide='ignore'):
Z = scaling_factor * (mu - loss_optimum) / sigma
expected_improvement = scaling_factor * (mu - loss_optimum) * norm.cdf(Z) + sigma * norm.pdf(Z)
expected_improvement[sigma == 0.0] == 0.0
return -1 * expected_improvement
def sample_next_hyperparameter(acquisition_func, gaussian_process, evaluated_loss, greater_is_better=False,
bounds=(0, 10), n_restarts=25):
""" 采样下一个超参数
acquisition_func:采集函数最优
n_restarts:以不同的起点运行最小化的次数
"""
best_x = None
best_acquisition_value = 1
n_params = bounds.shape[0]
for starting_point in np.random.uniform(bounds[:, 0], bounds[:, 1], size=(n_restarts, n_params)):
res = minimize(fun=acquisition_func,
x0=starting_point.reshape(1, -1),
bounds=bounds,
method='L-BFGS-B',
args=(gaussian_process, evaluated_loss, greater_is_better, n_params))
if res.fun < best_acquisition_value:
best_acquisition_value = res.fun
best_x = res.x
return best_x
def bayesian_optimisation(n_iters, sample_loss, bounds, x0=None, n_pre_samples=5,
gp_params=None, random_search=False, alpha=1e-5, epsilon=1e-7):
""" 贝叶斯优化
n_iters:(int)运行搜索算法的迭代次数;
sample_loss:需优化的采样损失函数;
bounds:sample_loss函数的上下限;
x0:初始点数组,若没有则随机选取;
n_pre_samples:(int)根据x0计算;
gp_params:传递给基础高斯过程的参数字典;
random_search:执行随机搜索;
alpha:GP误差项的方差;
epsilon:精度公差
"""
x_list = []
y_list = []
n_params = bounds.shape[0]
if x0 is None:
for params in np.random.uniform(bounds[:, 0], bounds[:, 1], (n_pre_samples, bounds.shape[0])):
x_list.append(params)
y_list.append(sample_loss(params))
else:
for params in x0:
x_list.append(params)
y_list.append(sample_loss(params))
xp = np.array(x_list)
yp = np.array(y_list)
if gp_params is not None:
model = gp.GaussianProcessRegressor(**gp_params)
else:
kernel = gp.kernels.Matern()
model = gp.GaussianProcessRegressor(kernel=kernel,
alpha=alpha,
n_restarts_optimizer=10,normalize_y=True)
for n in range(n_iters):
model.fit(xp, yp)
if random_search:
x_random = np.random.uniform(bounds[:, 0], bounds[:, 1], size=(random_search, n_params))
ei = -1 * expected_improvement(x_random, model, yp, greater_is_better=True, n_params=n_params)
next_sample = x_random[np.argmax(ei), :]
else:
next_sample = sample_next_hyperparameter(expected_improvement, model, yp, greater_is_better=True, bounds=bounds, n_restarts=100)
if np.any(np.abs(next_sample - xp) <= epsilon):
next_sample = np.random.uniform(bounds[:, 0], bounds[:, 1], bounds.shape[0])
cv_score = sample_loss(next_sample)
x_list.append(next_sample)
y_list.append(cv_score)
xp = np.array(x_list)
yp = np.array(y_list)
return xp, yp
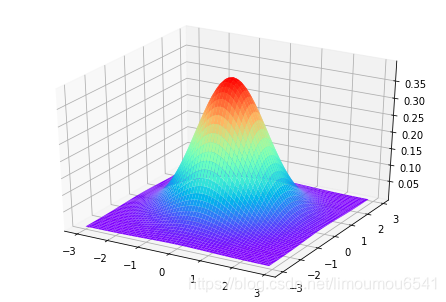
高斯分布和高斯过程拟合
import matplotlib.pyplot as plt
import numpy as np
from mpl_toolkits.mplot3d import Axes3D
from scrapy import statscollectors
fig = plt.figure()
ax = Axes3D(fig)
len = 3;
step = 0.1;
def build_gaussian_layer(mean, standard_deviation):
x = np.arange(-len, len, step);
y = np.arange(-len, len, step);
x, y = np.meshgrid(x, y);
z = np.exp(-((y-mean)**2 + (x - mean)**2)/(2*(standard_deviation**2)))
z = z/(np.sqrt(2*np.pi)*standard_deviation);
return (x, y, z);
x3, y3, z3 = build_gaussian_layer(0, 1)
ax.plot_surface(x3, y3, z3, rstride=1, cstride=1, cmap='rainbow')
plt.show()























 477
477

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









