






学习文章:人人都能看懂的chatGpt原理课
笔记作为学习用,侵删
Chatph和自然语言处理
什么是ChatGpt
ChatGPT(Chat Generative Pre-training Transformer) 是一个 AI 模型,属于自然语言处理( Natural Language Processing , NLP ) 领域,NLP 是人工智能的一个分支。
NLP(自然语言处理)是指,让计算机来理解并正确地操作自然语言(人们日常生活中接触和使用的英语、汉语、德语等等),完成人类指定的任务,比如关键词抽取,文本分类,机器翻译,对话系统(聊天机器人,也是chatgpt完成的工作)
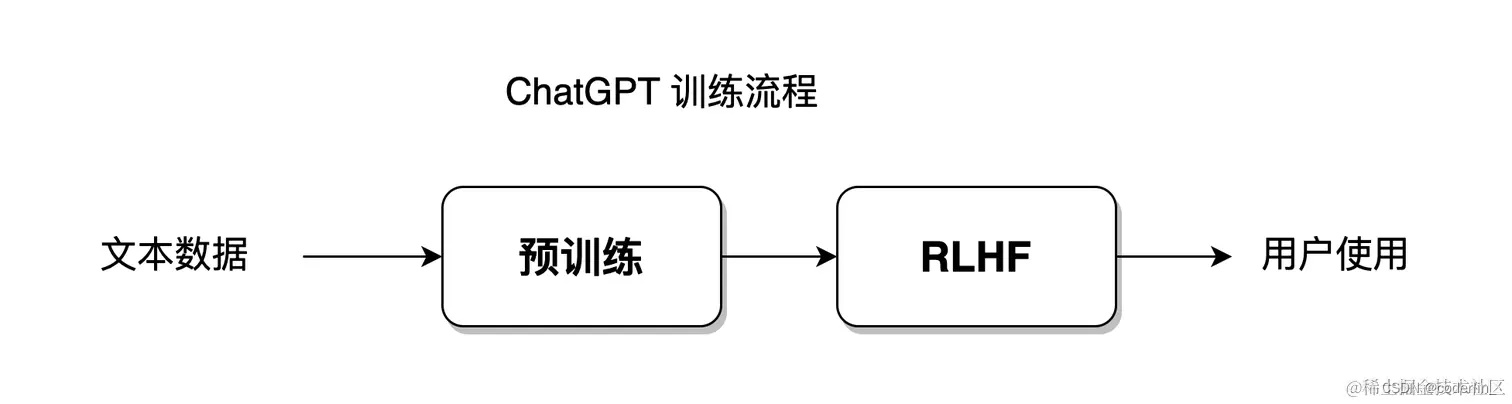
ChatGPT 的建模形式
Chatgpt的工作形式:
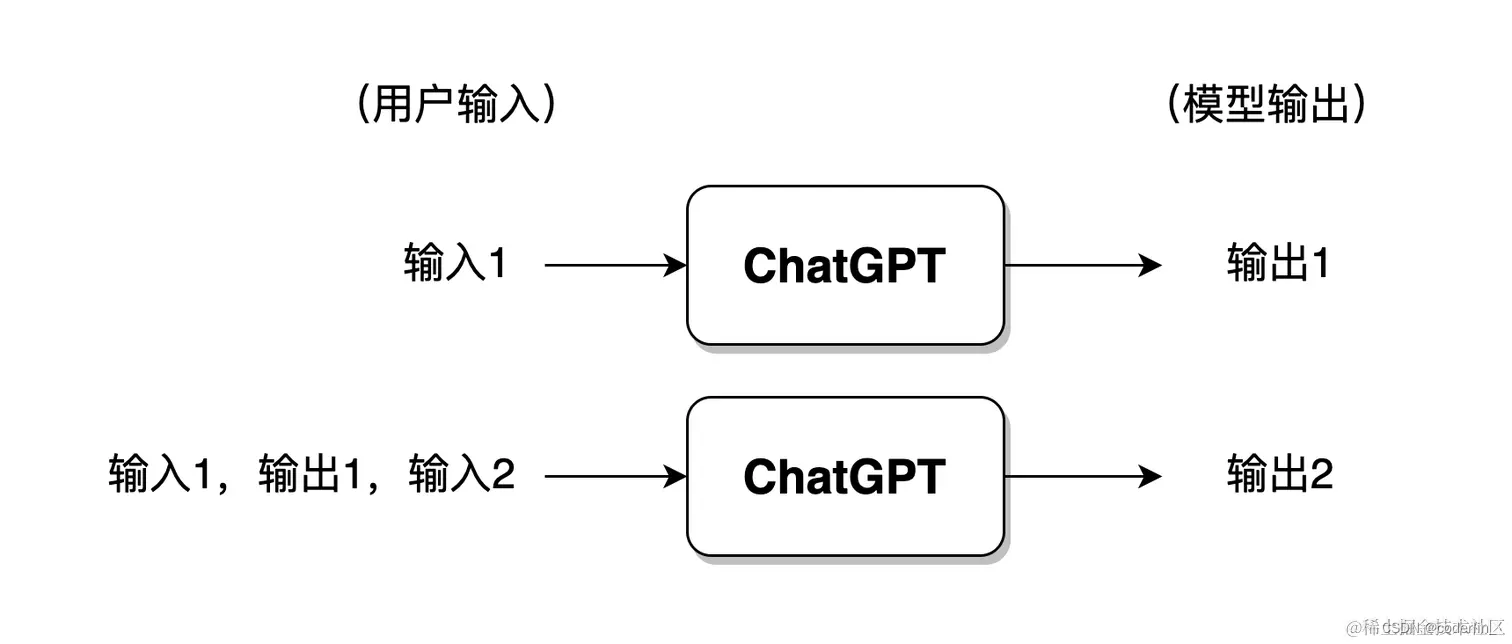
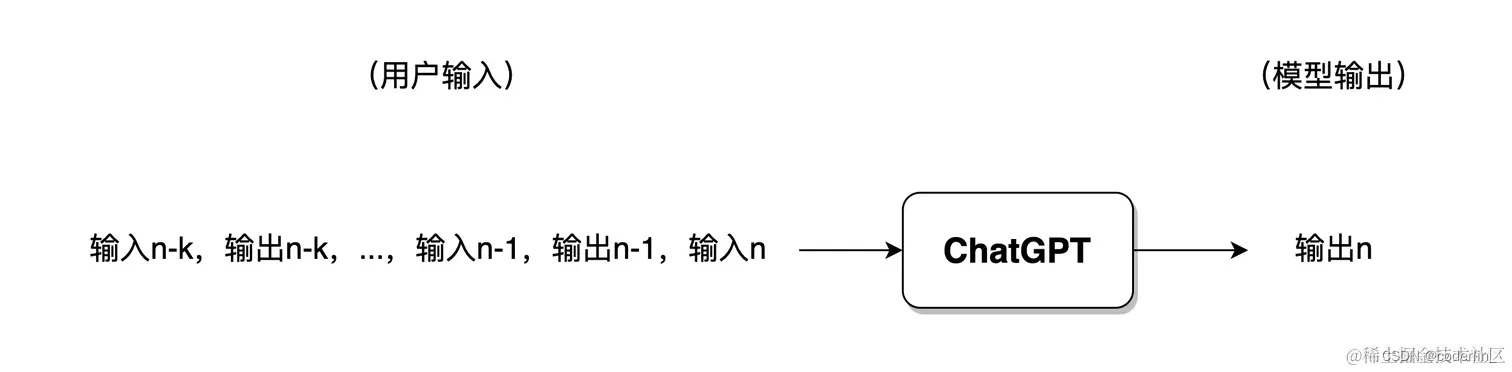
多轮对话时,一般来讲模型仅会保留最近几轮对话的信息,此前的对话信息将被遗忘。
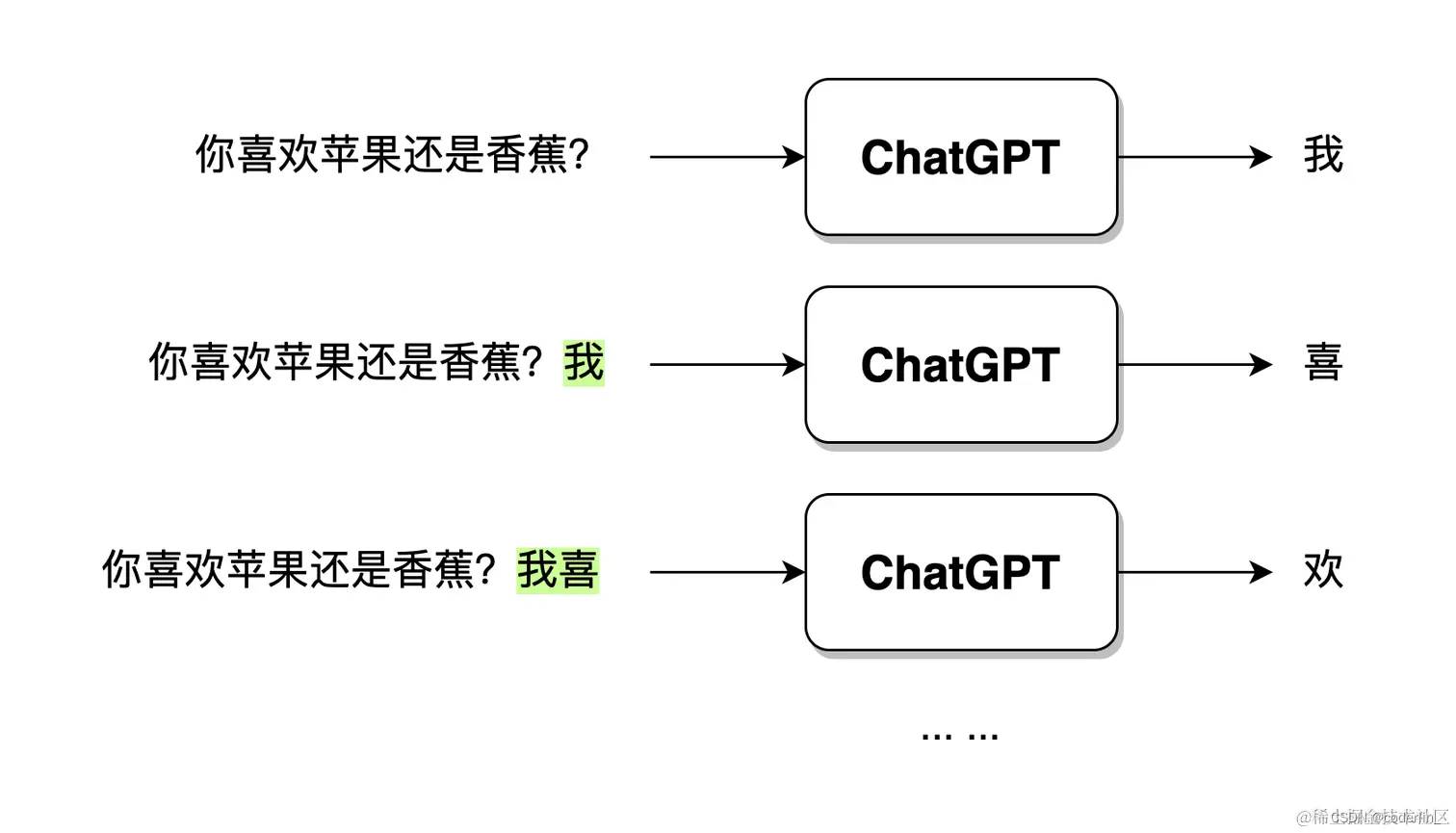
且Chatgpt在输出的时候,并不是直接一口气直接生成的,而是一个字一个字生成的,这种组逐字生成,即生成式,如
Chatgpt和NLP的发展历程
基于规则的NLP->基于统计的NLP->基于强化学习的NLP
- 基于
规则的NLP:顾名思义就是人工编写规则,让计算机根据规则来解析和生成自然语言。但是缺点很明显:规则无穷无尽,且自然语言中,任何规则都无法覆盖需求,本质上也没有将自然语言处理的方式交给计算机,仍然是人在主导。比如早期的"人工智能"。 - 基于
统计的NLP:利用机器学习算法,从大量的语料库中学习自然语言的规律特征(如chatGpt)。规则是隐形的,暗含在模型参数重,由模型根据训练得到,而基于规则的NLP,规则就是显性的,是人工编写的。但基于统计的也有缺点:黑盒不确定性,即规则是隐形的,暗含在参数中,比如gpt 有时候会给出云里雾里模糊的答案。
预训练:
在 ChatGPT 中,主要采用预训练( Pre-training ) 技术来完成基于统计的 NLP 模型学习。
它的重点在于,根据大规模原始语料学习一个语言模型,而这个模型并不直接学习如何解决具体的某种任务,而是学习从语法、词法、语用,到常识、知识等信息,把它们融汇在语言模型中。直观地讲,它更像是一个知识记忆器,而非运用知识解决实际问题。
基于强化学习的NLP
Chatgpt是基于统计的,然而他又利用新方法,带人工反馈的强化学习(Reinforcement Learning with Human Feedback,RLHF),所谓强化学习,就是一种机器学习的方式,旨在让chatGpt(智能体,如NLP中的深度神经网络模型)通过与环境的交互来学习如何做出最优决策。
比如训练小狗,小狗就是chatGpt,通过听口令(环境)来做出对应的动作(学习目标)
一只小狗,当听到主人吹哨后,就会被奖励食物;而当主人不吹哨时,小狗只能挨饿。通过反复的进食、挨饿,小狗就能建立起相应的条件反射,实际上就是完成了一次强化学习。
在NLP领域,环境是人为构造出来的一种语言环境模型。
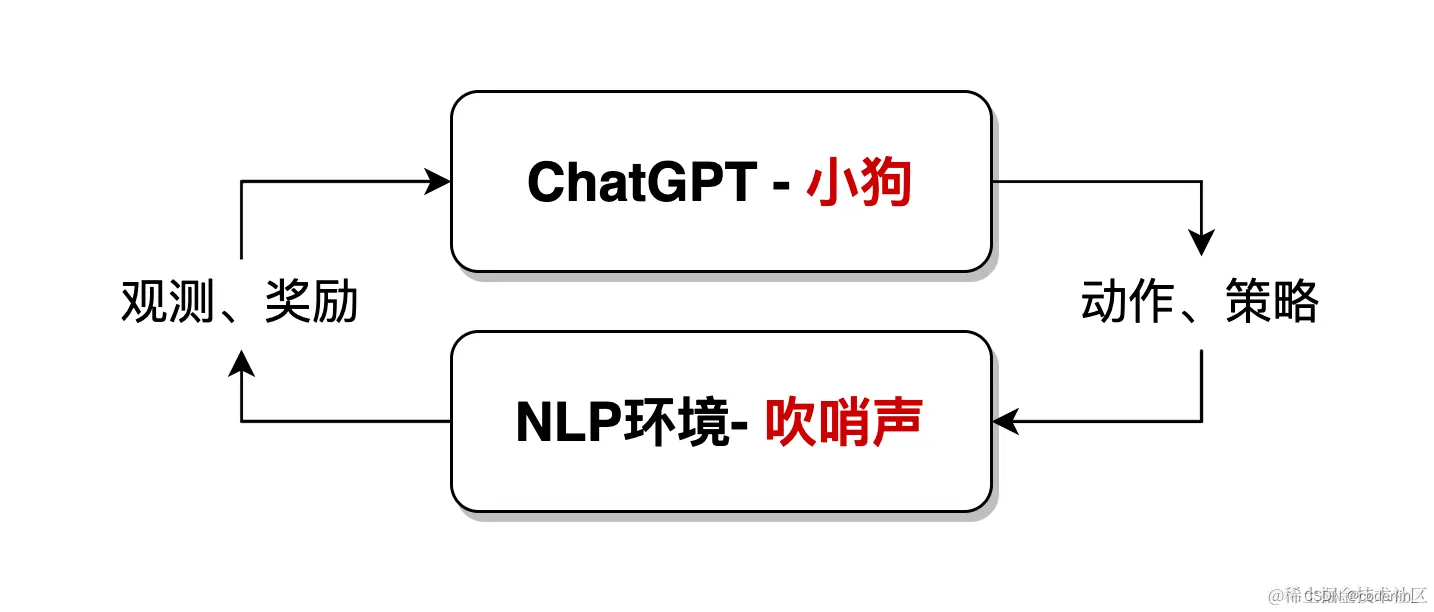
基于统计的方式,能让模型以最大自由度去拟合训练数据集,而强化学习,就是赋予模型更大的自由度,让模型能够自主学习,突破既定的数据集限制,chatGpt模型就是融合统计学习方法+强化学习方法,如
NLP 技术的发展脉络
基于规则,基于统计,基于强化学习这三种方式,并不仅仅是一种处理自然语言的手段,而是一种思想。一个解决某一个问题的模型,往往是融合了这三种解决思想的产物。
如果把计算机当作一个小孩,自然语言处理就像是人类来教育小孩子成长
基于规则:家长百分之百控制小孩子,强调手把手教。
基于统计:家长只告诉小孩子学习方法,而不教每一道题,让小孩子自己去学习,强调半引导,对于NLP,学习重心放在了神经网络模型上,但主动权仍有算法工程师执导。
基于强化学习:家长只给小孩制定目标,比如我要你考90分,然后就不管孩子如何学习,全靠孩子自学。小孩拥有极高的自由度和主动权,家长只对最终结果做出奖励和惩罚,不参与整个教育过程。对于NLP来说:整个过程的重心和主动权都在模型本身。
NLP 的发展一直以来都在逐渐向基于统计的方式靠拢,最终由基于强化学习的方式取得完全的胜利,胜利的标志,即 ChatGPT 的问世;
ChatGPT 的神经网络结构 Transformer
ChatGPT 是一个大型的神经网络,其内部结构是由若干层 Transformer 构成的,Transformer 是一种神经网络的结构。
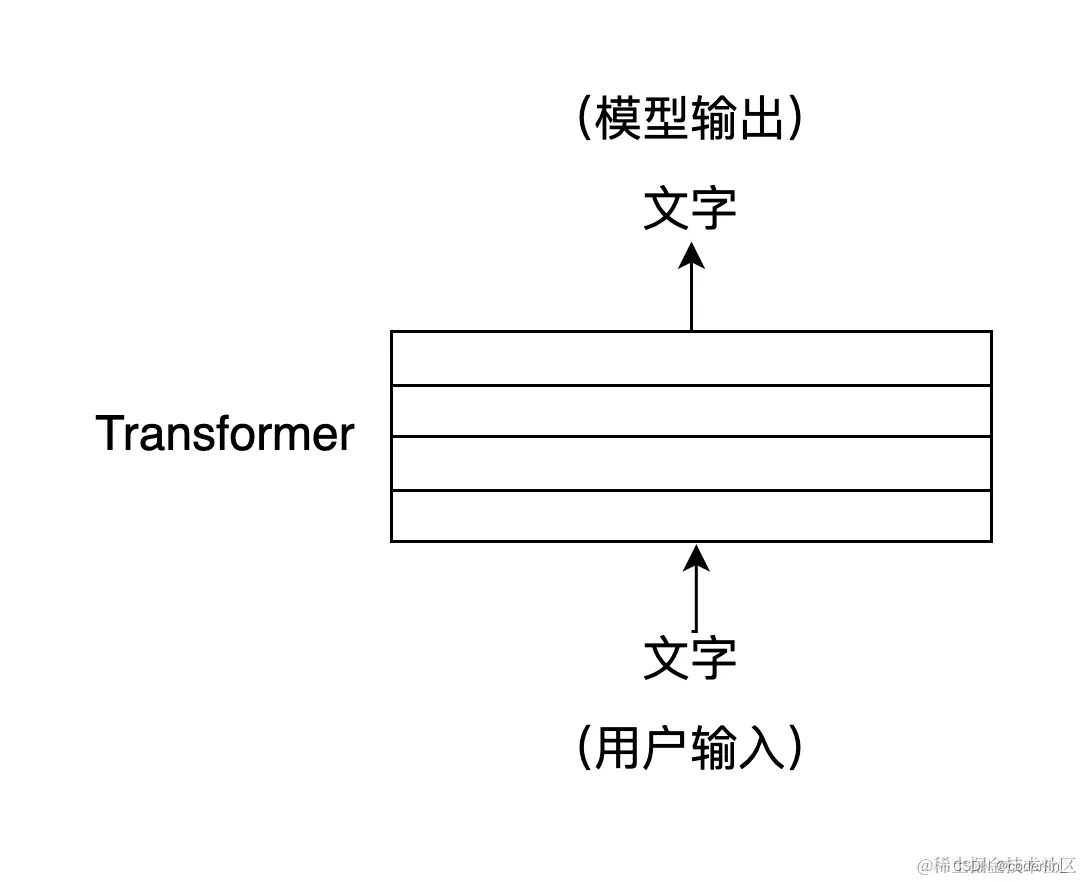
Transformer 的核心是自注意力机制(Self-Attention),它可以帮助模型在处理输入的文字序列时,自动关注与当前位置字符相关的,其他位置字符,自注意力机制可以将输入序列中的每个位置当作一个向量,他们可以同时参与计算,从而实现高效的并行运算。也就是
Transformer 能够更好地捕捉句子中,跨越很长距离的词汇之间的关系,解决文本上下文的长依赖
总结
- NLP 领域的发展逐渐由人为编写规则、逻辑控制计算机程序,到完全交由网络模型去适应语言环境。
- ChatGPT 的工作流程是一个生成式的对话系统。
- ChatGPT 的训练过程包括语言模型的预训练,RLHF 带人工反馈的强化学习。
- ChatGPT 的模型结构采用以自注意力机制为核心的 Transformer。
从Gpt1.0到ChatGPT
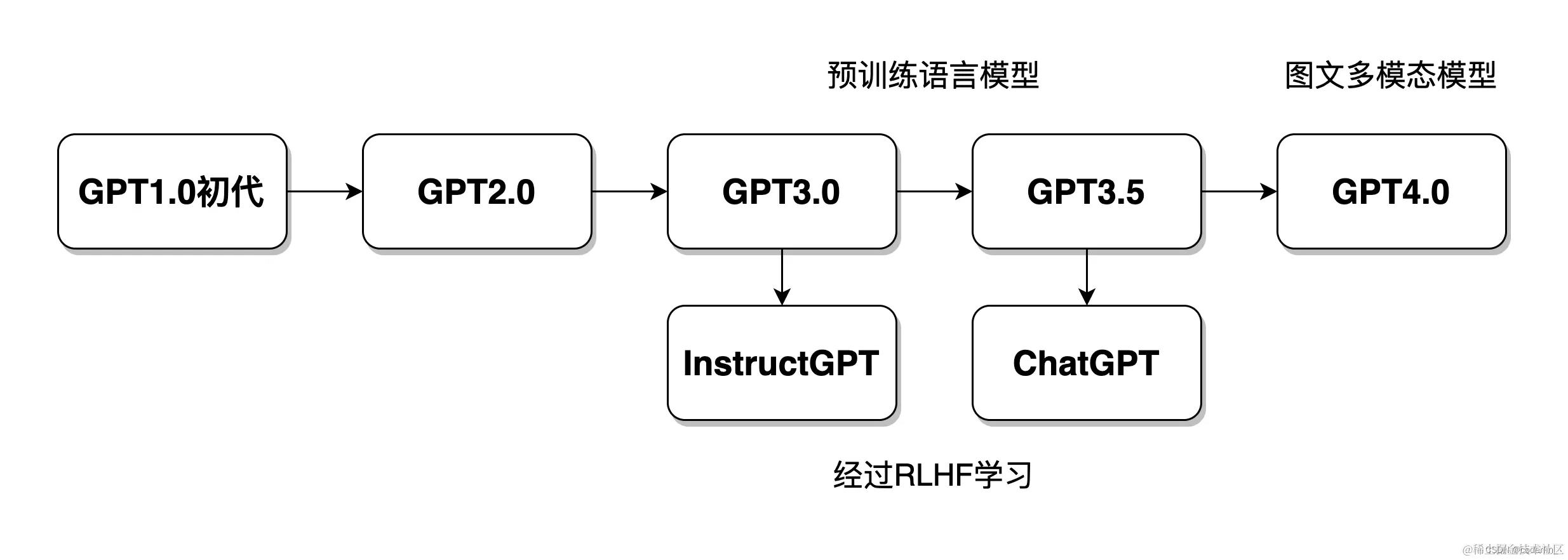
若把 ChatGPT 比作一个健康聪明的青年人,那么早期的模型就是他的婴儿时期、青少年时期,GPT 的发展历程像是朝着模拟人类发展。
GPT 初代
GPT,Bert,ELMO模型,一起将 NLP 带进了大规模神经网络语言模型(Large Language Model, LLM)时代。它们正式标志着 NLP 领域开始全面拥抱预训练的方式。
GPT 的语言建模
GPT 初代所做的事就是从从大规模的文本语料中,将每一条文本随机地分成两部分,只保留上半部分,让模型学习下半部分学习到底该填写什么,这种学习方法让模型具备了在当时看来非常强的智能。所谓语言模型(Language Model,LM),就是从大量的数据中学习复杂的上下文联系
GPT-2
GPT-2 的论文名就叫做【Language Models are Unsupervised Multitask Learners】,语言模型是多任务学习者。
GPT-2 主要就是在 GPT 初代的基础上,又添加了多个任务,比如机器翻译、问答、文本摘要等等,扩增了数据集和模型参数,又训练了一番。
元学习(meta-learning),实际上就是语言模型的一脑多用。
GPT-3
大模型中的大模型
小样本(Few-Shot)学习
GPT3 的论文标题叫做【Language Models are Few-Shot Learners】,语言模型是小样本学习者
以往在训练 NLP 模型的时候,都需要用到大量的标注数据。可是标注数据的成本实在是太高了,这些都得人工手工一个个来标注完成!有没有什么不这么依赖大量标注的方式吗?
GPT3 就提出了小样本学习的概念,简单来讲,就是让模型学习语言时,不需要那么多的样例数据。
如
假设,我们训练一个可抽取文本中人名的模型,就需要标注千千万万个人名,比如“张雪华”、“刘星宇”等。千千万万个标注数据,就像是教了模型千千万万次同一个题目一样,这样才能掌握。
而人脑却不是这样,当被告知“山下惠子”是一个日本人名以后(仅仅被教学了一次),人脑马上就能理解,“中岛晴子”大概率也是一个日本人名,尽管人脑从来没听说过这个名字。
ChatGPT
ChatGPT 模型结构上和之前的几代都没有太大变化,主要变化的是训练策略变了。
强化学习
ChatGPT 将 NLP 带入了强化学习时代。
训练 ChatGPT 所需要的文本,主要来自于互联网,这是一个有限的集合,但是我们提出的问题,无穷无尽,有的在网上根本找不到。
对于传统的深度神经网络模型的训练思路,只能根据网上已有的数据做训练,学习的只是已有的数据本身。
而chatgpt的强化学习思路,则是模拟一个环境模型(Reward)。
chatgpt会根据一个问题给出一个答案,而环境模型则会给他打分。高分代表奖励,低分代表惩罚,不会给出标准答案。
而chatgpt接收到评价反馈后,可以根据这个数值做模型的进一步训练,朝着生成更加恰当答案的方向拟合。
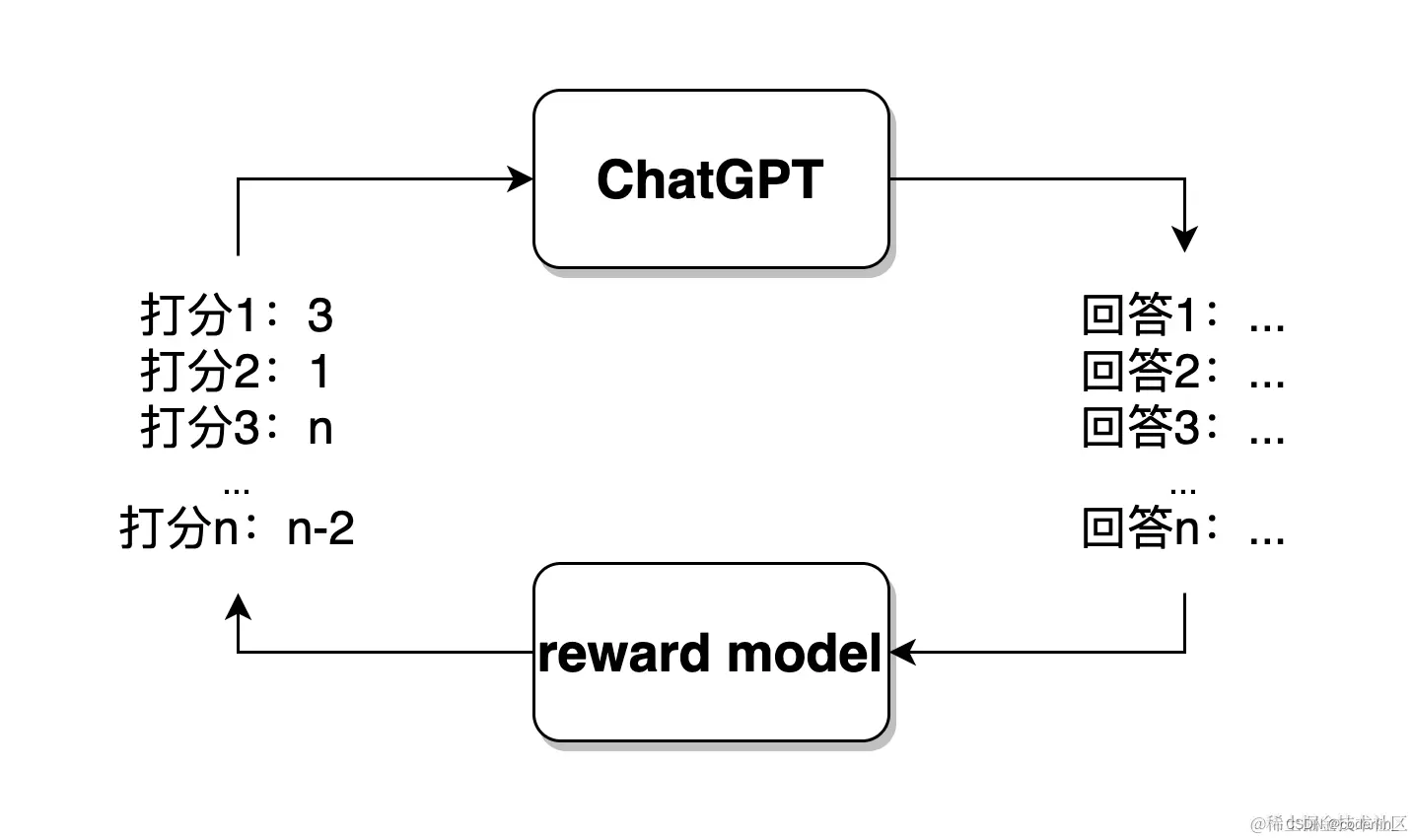
由此,chatgpt 模型已经不再局限于已有的训练数据集,可以扩展至更大的范围,应对从未见过的问题。
总结
- 纵观 ChatGPT 模型的进化历史,可以看出,模型的发展脚步就是在朝着模拟人类的方式前进着
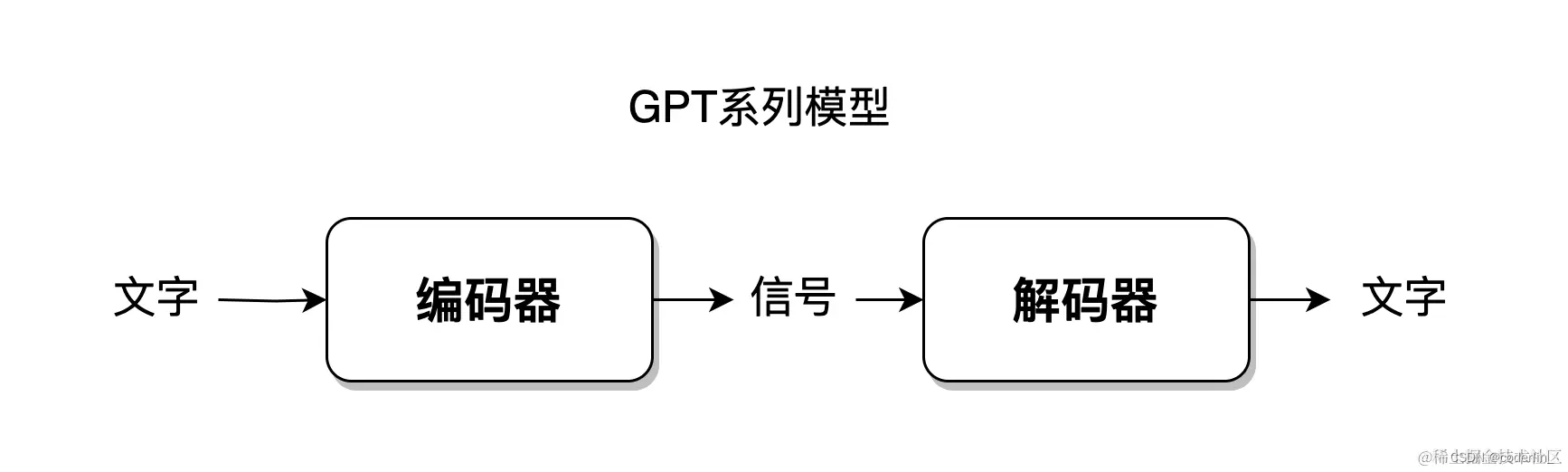
- 人类接收语言文字信息,输出语言文字,应用了编解码方式,ChatGPT 也利用了编解码的方式(编码解码)。
- 人类的大脑神经元数量是所有生物中最多的,ChatGPT 应用了超千亿的大规模参数模型(gpt3的模型参数量达1750亿)。
- 人类采用了对话的方式进行交流,ChatGPT 建模也采用了对话的方式(对话方式学习)。
- 人类的大脑具有多种多样的功能,ChatGPT 也融合了多任务,各种各样的NLP任务(gpt2 多任务学习)。
- 人类可以通过极少量的样例进行学习,ChatGPT 也可以完成小样本学习(gpt3 小样本学习,比如日本名中上惠子)。
- 人类可以在与实际环境的交互中学习知识,塑造语言,ChatGPT 也添加了强化学习,模拟与人类的交互(环境模型打分机制)。
- ChatGPT 的发展史,就是人工智能模拟人脑的历史。
















 5024
5024

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











